 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End 3D Hand Pose Estimation from Stereo Cameras
Jun 03, 2022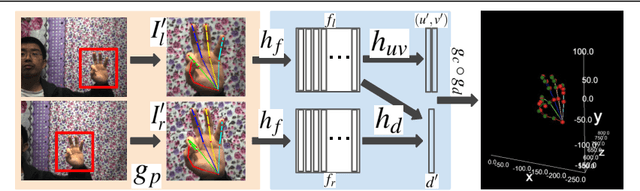
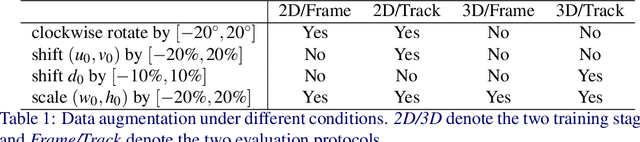

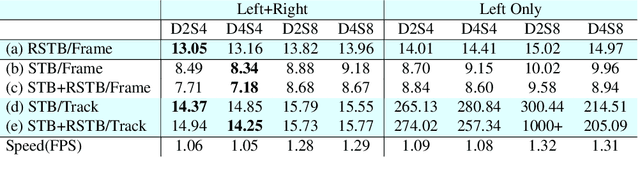
This work proposes an end-to-end approach to estimate full 3D hand pose from stereo cameras. Most existing methods of estimating hand pose from stereo cameras apply stereo matching to obtain depth map and use depth-based solution to estimate hand pose. In contrast, we propose to bypass the stereo matching and directly estimate the 3D hand pose from the stereo image pairs. The proposed neural network architecture extends from any keypoint predictor to estimate the sparse disparity of the hand joints. In order to effectively train the model, we propose a large scale synthetic dataset that is composed of stereo image pairs and ground truth 3D hand pose annotations. Experiments show that the proposed approach outperforms the existing methods based on the stereo depth.
E^2TAD: An Energy-Efficient Tracking-based Action Detector
Apr 09, 2022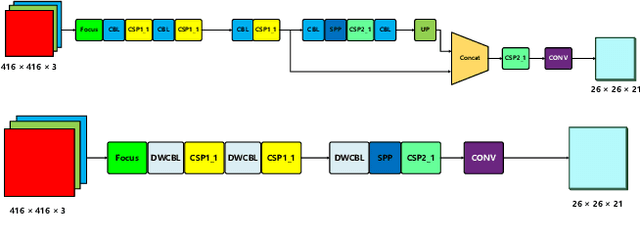

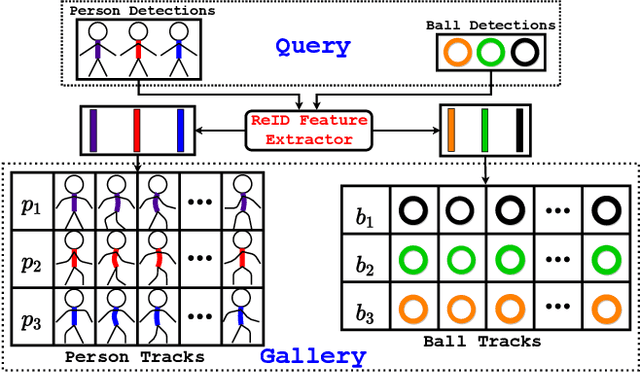
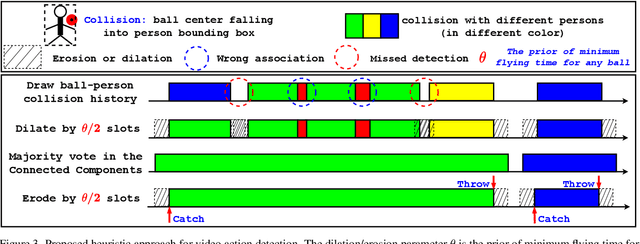
Video action detection (spatio-temporal action localization) is usually the starting point for human-centric intelligent analysis of videos nowadays. It has high practical impacts for many applications across robotics, security, healthcare, etc. The two-stage paradigm of Faster R-CNN inspires a standard paradigm of video action detection in object detection, i.e., firstly generating person proposals and then classifying their actions. However, none of the existing solutions could provide fine-grained action detection to the "who-when-where-what" level. This paper presents a tracking-based solution to accurately and efficiently localize predefined key actions spatially (by predicting the associated target IDs and locations) and temporally (by predicting the time in exact frame indices). This solution won first place in the UAV-Video Track of 2021 Low-Power Computer Vision Challenge (LPCVC).
Self-supervised Pretraining with Classification Labels for Temporal Activity Detection
Nov 26, 2021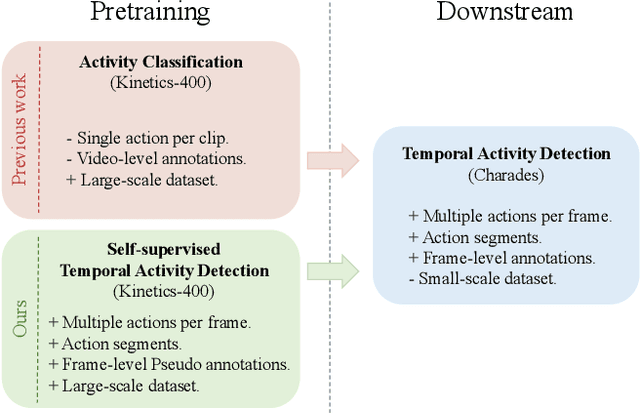
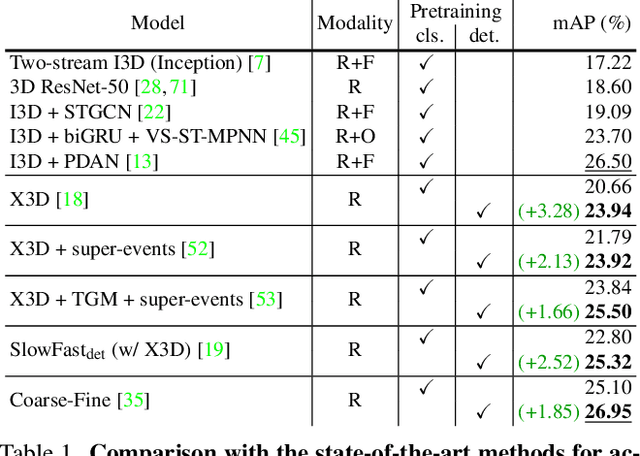
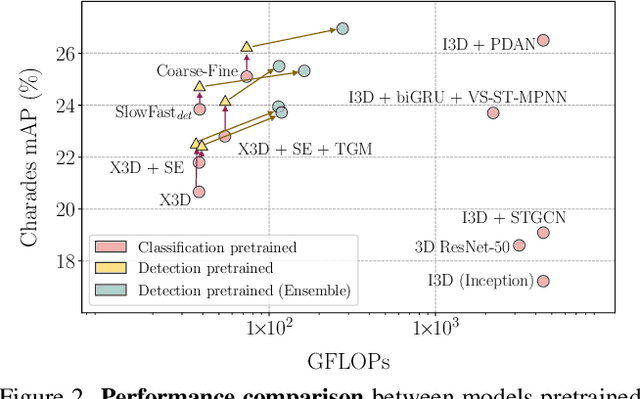
Temporal Activity Detection aims to predict activity classes per frame, in contrast to video-level predictions as done in Activity Classification (i.e., Activity Recognition). Due to the expensive frame-level annotations required for detection, the scale of detection datasets is limited. Thus, commonly, previous work on temporal activity detection resorts to fine-tuning a classification model pretrained on large-scale classification datasets (e.g., Kinetics-400). However, such pretrained models are not ideal for downstream detection performance due to the disparity between the pretraining and the downstream fine-tuning tasks. This work proposes a novel self-supervised pretraining method for detection leveraging classification labels to mitigate such disparity by introducing frame-level pseudo labels, multi-action frames, and action segments. We show that the models pretrained with the proposed self-supervised detection task outperform prior work on multiple challenging activity detection benchmarks, including Charades and MultiTHUMOS. Our extensive ablations further provide insights on when and how to use the proposed models for activity detection. Code and models will be released online.
Learning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking
Jun 07, 2021
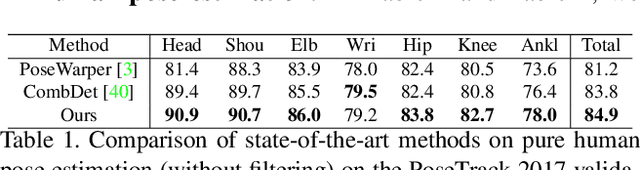
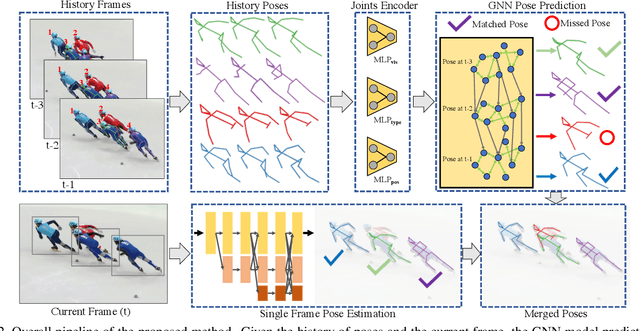
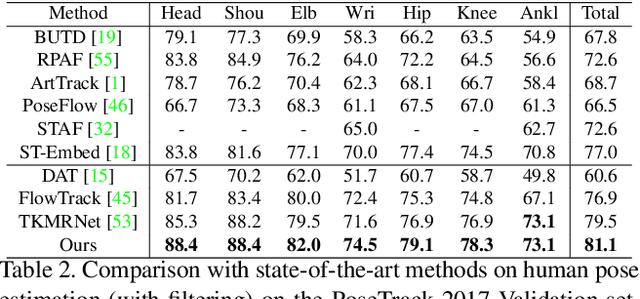
Multi-person pose estimation and tracking serve as crucial steps for video understanding. Most state-of-the-art approaches rely on first estimating poses in each frame and only then implementing data association and refinement. Despite the promising results achieved, such a strategy is inevitably prone to missed detections especially in heavily-cluttered scenes, since this tracking-by-detection paradigm is, by nature, largely dependent on visual evidences that are absent in the case of occlusion. In this paper, we propose a novel online approach to learning the pose dynamics, which are independent of pose detections in current fame, and hence may serve as a robust estimation even in challenging scenarios including occlusion. Specifically, we derive this prediction of dynamics through a graph neural network~(GNN) that explicitly accounts for both spatial-temporal and visual information. It takes as input the historical pose tracklets and directly predicts the corresponding poses in the following frame for each tracklet. The predicted poses will then be aggregated with the detected poses, if any, at the same frame so as to produce the final pose, potentially recovering the occluded joints missed by the estimator. Experiments on PoseTrack 2017 and PoseTrack 2018 datasets demonstrate that the proposed method achieves results superior to the state of the art on both human pose estimation and tracking tasks.
SaccadeNet: A Fast and Accurate Object Detector
Mar 26, 2020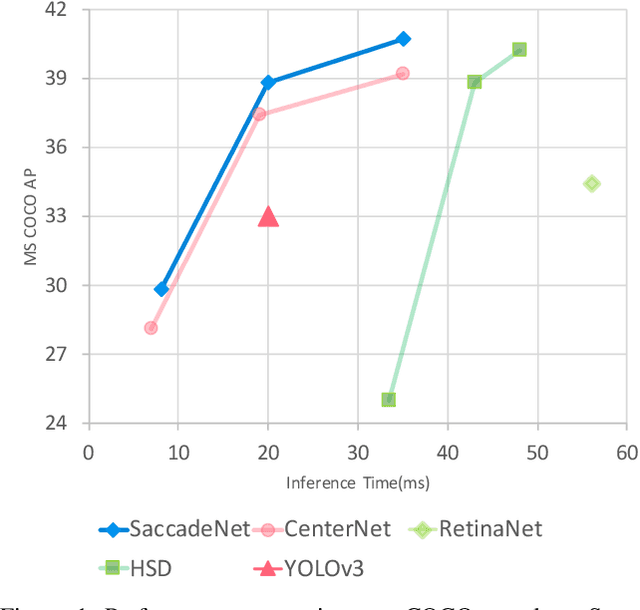
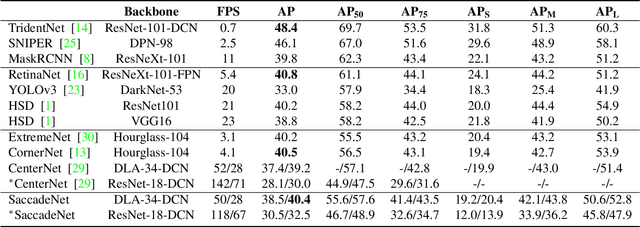
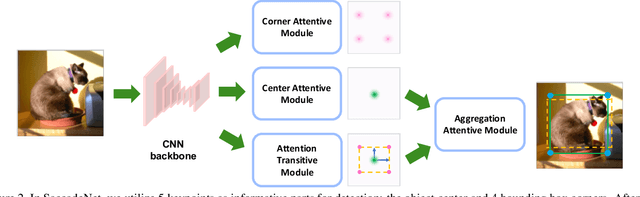

Object detection is an essential step towards holistic scene understanding. Most existing object detection algorithms attend to certain object areas once and then predict the object locations. However, neuroscientists have revealed that humans do not look at the scene in fixed steadiness. Instead, human eyes move around, locating informative parts to understand the object location. This active perceiving movement process is called \textit{saccade}. %In this paper, Inspired by such mechanism, we propose a fast and accurate object detector called \textit{SaccadeNet}. It contains four main modules, the \cenam, the \coram, the \atm, and the \aggatt, which allows it to attend to different informative object keypoints, and predict object locations from coarse to fine. The \coram~is used only during training to extract more informative corner features which brings free-lunch performance boost. On the MS COCO dataset, we achieve the performance of 40.4\% mAP at 28 FPS and 30.5\% mAP at 118 FPS. Among all the real-time object detectors, %that can run faster than 25 FPS, our SaccadeNet achieves the best detection performance, which demonstrates the effectiveness of the proposed detection mechanism.
Calibrated Domain-Invariant Learning for Highly Generalizable Large Scale Re-Identification
Nov 27, 2019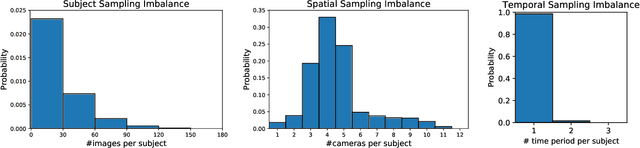
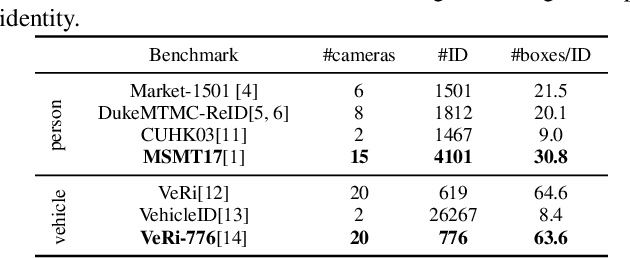
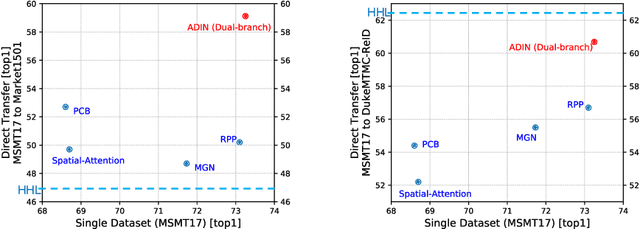
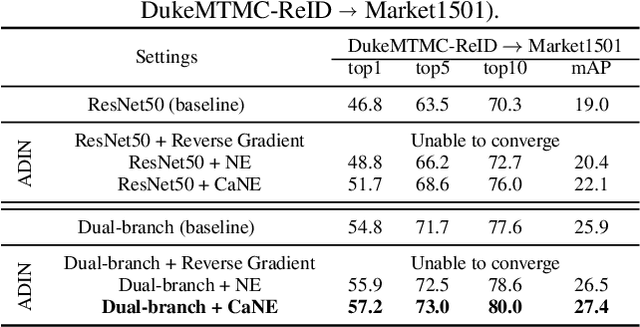
Many real-world applications, such as city-scale traffic monitoring and control, requires large-scale re-identification. However, previous ReID methods often failed to address two limitations in existing ReID benchmarks, i.e., low spatiotemporal coverage and sample imbalance. Notwithstanding their demonstrated success in every single benchmark, they have difficulties in generalizing to unseen environments. As a result, these methods are less applicable in a large-scale setting due to poor generalization. In seek for a highly generalizable large-scale ReID method, we present an adversarial domain invariant feature learning framework (ADIN) that explicitly learns to separate identity-related features from challenging variations, where for the first time "free" annotations in ReID data such as video timestamp and camera index are utilized. Furthermore, we find that the imbalance of nuisance classes jeopardizes the adversarial training, and for mitigation we propose a calibrated adversarial loss that is attentive to nuisance distribution. Experiments on existing large-scale person vehicle ReID datasets demonstrate that ADIN learns more robust and generalizable representations, as evidenced by its outstanding direct transfer performance across datasets, which is a criterion that can better measure the generalizability of large-scale ReID methods/
ABD-Net: Attentive but Diverse Person Re-Identification
Aug 09, 2019
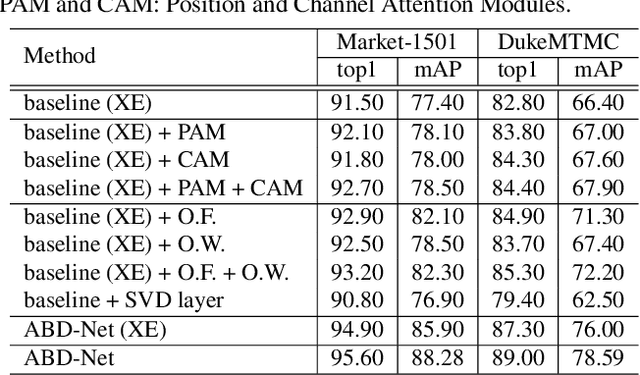
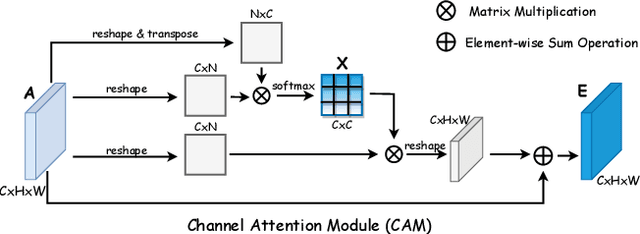
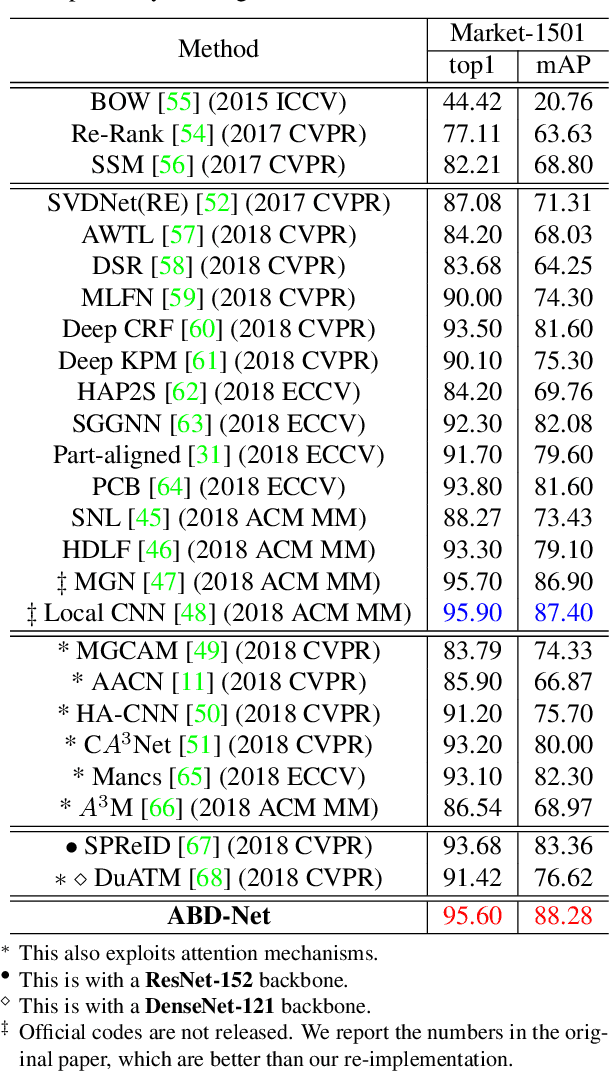
Attention mechanism has been shown to be effective for person re-identification (Re-ID). However, the learned attentive feature embeddings which are often not naturally diverse nor uncorrelated, will compromise the retrieval performance based on the Euclidean distance. We advocate that enforcing diversity could greatly complement the power of attention. To this end, we propose an Attentive but Diverse Network (ABD-Net), which seamlessly integrates attention modules and diversity regularization throughout the entire network, to learn features that are representative, robust, and more discriminative. Specifically, we introduce a pair of complementary attention modules, focusing on channel aggregation and position awareness, respectively. Furthermore, a new efficient form of orthogonality constraint is derived to enforce orthogonality on both hidden activations and weights. Through careful ablation studies, we verify that the proposed attentive and diverse terms each contributes to the performance gains of ABD-Net. On three popular benchmarks, ABD-Net consistently outperforms existing state-of-the-art methods.
Streamlined Dense Video Captioning
Apr 08, 2019

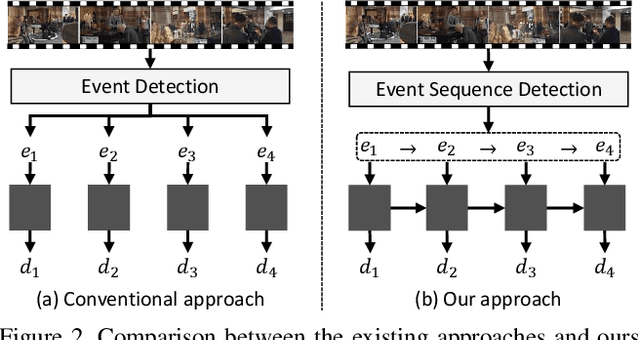
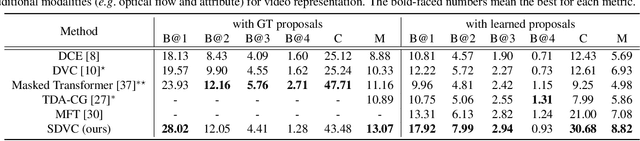
Dense video captioning is an extremely challenging task since accurate and coherent description of events in a video requires holistic understanding of video contents as well as contextual reasoning of individual events. Most existing approaches handle this problem by first detecting event proposals from a video and then captioning on a subset of the proposals. As a result, the generated sentences are prone to be redundant or inconsistent since they fail to consider temporal dependency between events. To tackle this challenge, we propose a novel dense video captioning framework, which models temporal dependency across events in a video explicitly and leverages visual and linguistic context from prior events for coherent storytelling. This objective is achieved by 1) integrating an event sequence generation network to select a sequence of event proposals adaptively, and 2) feeding the sequence of event proposals to our sequential video captioning network, which is trained by reinforcement learning with two-level rewards at both event and episode levels for better context modeling. The proposed technique achieves outstanding performances on ActivityNet Captions dataset in most metrics.
3D Hand Shape and Pose Estimation from a Single RGB Image
Mar 03, 2019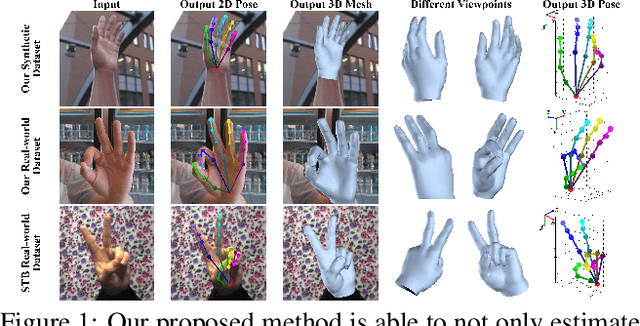



This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
Deep Regionlets: Blended Representation and Deep Learning for Generic Object Detection
Nov 28, 2018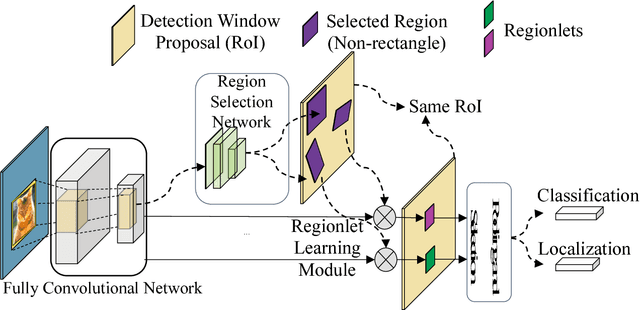
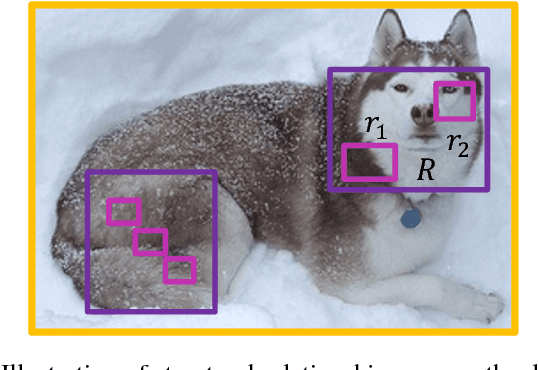

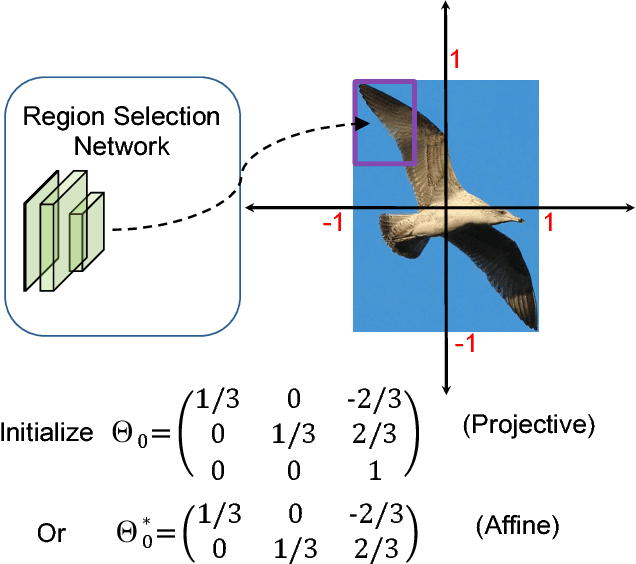
In this paper, we propose a novel object detection algorithm named "Deep Regionlets" by integrating deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the advantages of regionlets on modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions from which features can be learned from. The regionlet learning module focuses on local feature selection and transformation to alleviate the effects of appearance variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We present the results of ablation studies and extensive experiments on PASCAL VOC and Microsoft COCO datasets. The proposed algorithm outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.