 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
PALM: A Dataset and Baseline for Learning Multi-subject Hand Prior
Nov 07, 2025

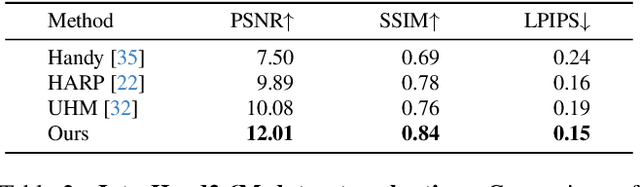
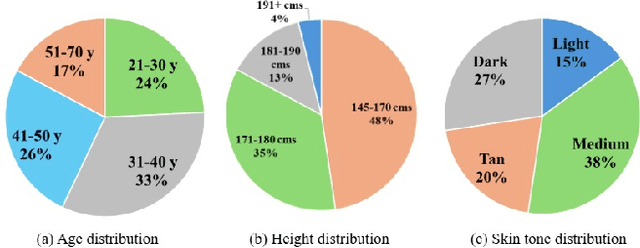
The ability to grasp objects, signal with gestures, and share emotion through touch all stem from the unique capabilities of human hands. Yet creating high-quality personalized hand avatars from images remains challenging due to complex geometry, appearance, and articulation, particularly under unconstrained lighting and limited views. Progress has also been limited by the lack of datasets that jointly provide accurate 3D geometry, high-resolution multiview imagery, and a diverse population of subjects. To address this, we present PALM, a large-scale dataset comprising 13k high-quality hand scans from 263 subjects and 90k multi-view images, capturing rich variation in skin tone, age, and geometry. To show its utility, we present a baseline PALM-Net, a multi-subject prior over hand geometry and material properties learned via physically based inverse rendering, enabling realistic, relightable single-image hand avatar personalization. PALM's scale and diversity make it a valuable real-world resource for hand modeling and related research.
End-to-End 3D Hand Pose Estimation from Stereo Cameras
Jun 03, 2022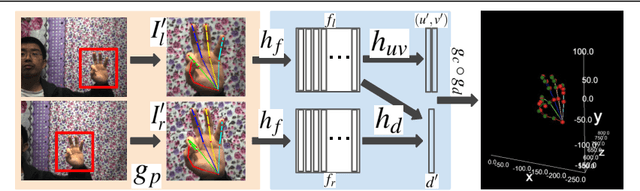
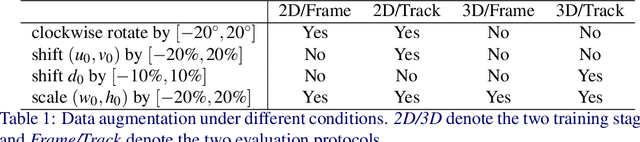

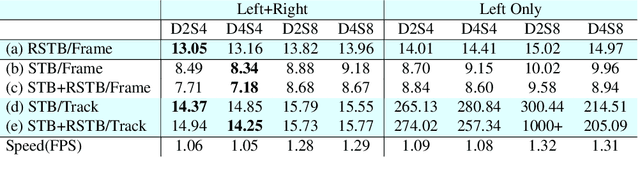
This work proposes an end-to-end approach to estimate full 3D hand pose from stereo cameras. Most existing methods of estimating hand pose from stereo cameras apply stereo matching to obtain depth map and use depth-based solution to estimate hand pose. In contrast, we propose to bypass the stereo matching and directly estimate the 3D hand pose from the stereo image pairs. The proposed neural network architecture extends from any keypoint predictor to estimate the sparse disparity of the hand joints. In order to effectively train the model, we propose a large scale synthetic dataset that is composed of stereo image pairs and ground truth 3D hand pose annotations. Experiments show that the proposed approach outperforms the existing methods based on the stereo depth.
3D Hand Shape and Pose Estimation from a Single RGB Image
Mar 03, 2019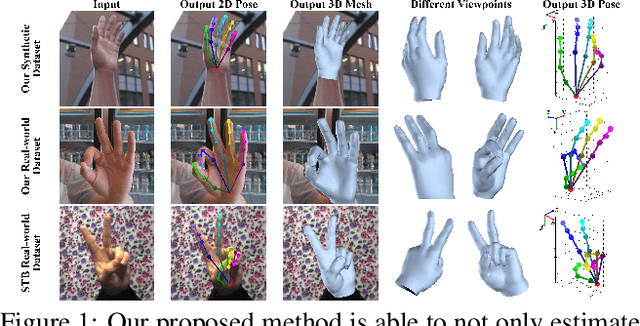



This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Mar 29, 2018
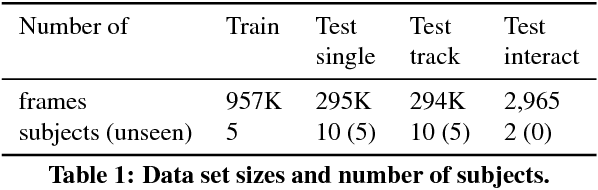
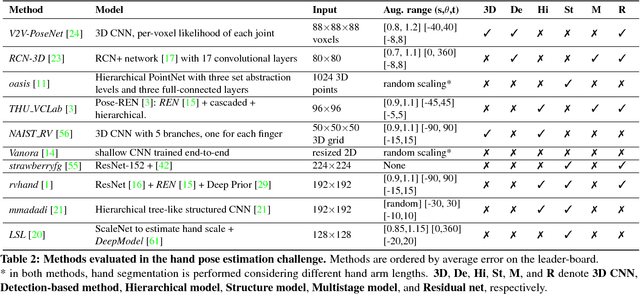
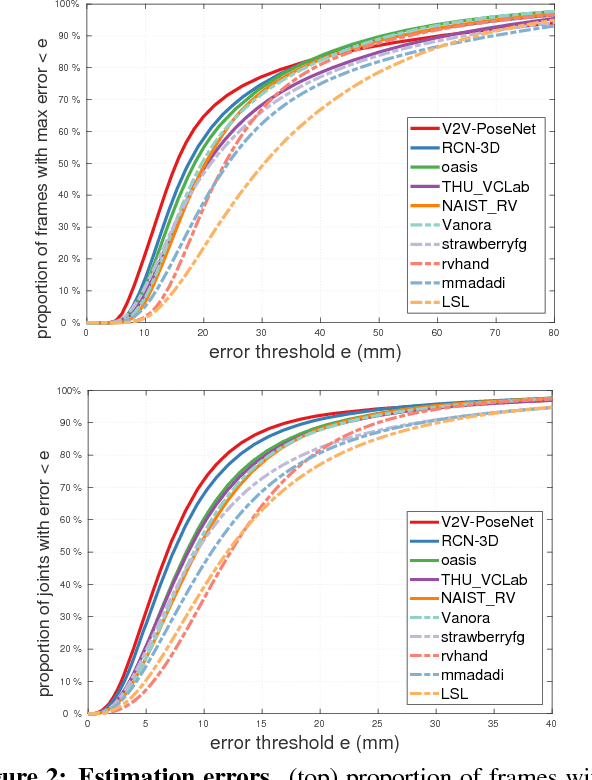
In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.
Robust 3D Hand Pose Estimation in Single Depth Images: from Single-View CNN to Multi-View CNNs
Dec 27, 2016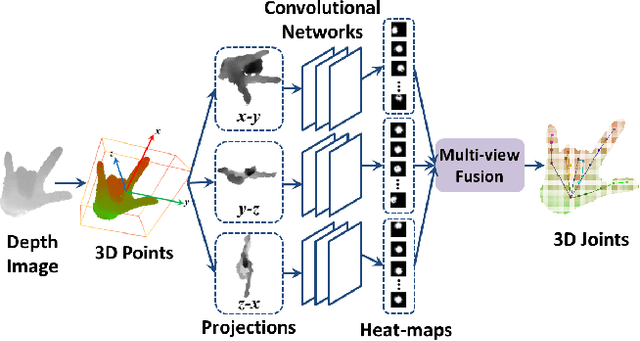
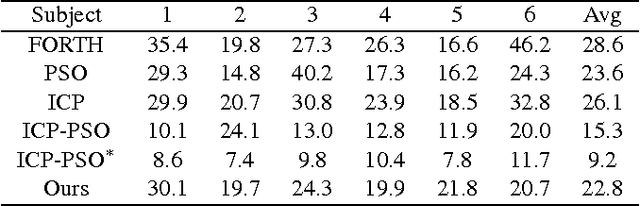

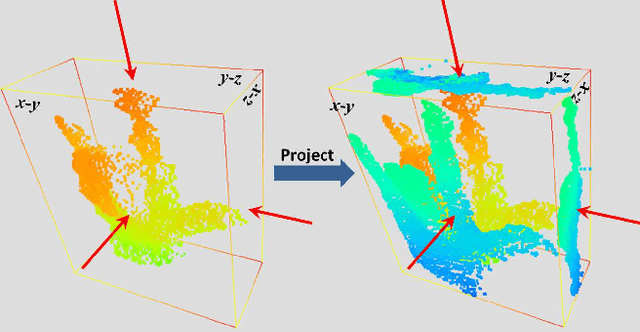
Articulated hand pose estimation plays an important role in human-computer interaction. Despite the recent progress, the accuracy of existing methods is still not satisfactory, partially due to the difficulty of embedded high-dimensional and non-linear regression problem. Different from the existing discriminative methods that regress for the hand pose with a single depth image, we propose to first project the query depth image onto three orthogonal planes and utilize these multi-view projections to regress for 2D heat-maps which estimate the joint positions on each plane. These multi-view heat-maps are then fused to produce final 3D hand pose estimation with learned pose priors. Experiments show that the proposed method largely outperforms state-of-the-art on a challenging dataset. Moreover, a cross-dataset experiment also demonstrates the good generalization ability of the proposed method.