 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanceChat: Large Language Model-Guided Music-to-Dance Generation
Jun 12, 2025Music-to-dance generation aims to synthesize human dance motion conditioned on musical input. Despite recent progress, significant challenges remain due to the semantic gap between music and dance motion, as music offers only abstract cues, such as melody, groove, and emotion, without explicitly specifying the physical movements. Moreover, a single piece of music can produce multiple plausible dance interpretations. This one-to-many mapping demands additional guidance, as music alone provides limited information for generating diverse dance movements. The challenge is further amplified by the scarcity of paired music and dance data, which restricts the model\^a\u{A}\'Zs ability to learn diverse dance patterns. In this paper, we introduce DanceChat, a Large Language Model (LLM)-guided music-to-dance generation approach. We use an LLM as a choreographer that provides textual motion instructions, offering explicit, high-level guidance for dance generation. This approach goes beyond implicit learning from music alone, enabling the model to generate dance that is both more diverse and better aligned with musical styles. Our approach consists of three components: (1) an LLM-based pseudo instruction generation module that produces textual dance guidance based on music style and structure, (2) a multi-modal feature extraction and fusion module that integrates music, rhythm, and textual guidance into a shared representation, and (3) a diffusion-based motion synthesis module together with a multi-modal alignment loss, which ensures that the generated dance is aligned with both musical and textual cues. Extensive experiments on AIST++ and human evaluations show that DanceChat outperforms state-of-the-art methods both qualitatively and quantitatively.
STaR: Seamless Spatial-Temporal Aware Motion Retargeting with Penetration and Consistency Constraints
Apr 09, 2025Motion retargeting seeks to faithfully replicate the spatio-temporal motion characteristics of a source character onto a target character with a different body shape. Apart from motion semantics preservation, ensuring geometric plausibility and maintaining temporal consistency are also crucial for effective motion retargeting. However, many existing methods prioritize either geometric plausibility or temporal consistency. Neglecting geometric plausibility results in interpenetration while neglecting temporal consistency leads to motion jitter. In this paper, we propose a novel sequence-to-sequence model for seamless Spatial-Temporal aware motion Retargeting (STaR), with penetration and consistency constraints. STaR consists of two modules: (1) a spatial module that incorporates dense shape representation and a novel limb penetration constraint to ensure geometric plausibility while preserving motion semantics, and (2) a temporal module that utilizes a temporal transformer and a novel temporal consistency constraint to predict the entire motion sequence at once while enforcing multi-level trajectory smoothness. The seamless combination of the two modules helps us achieve a good balance between the semantic, geometric, and temporal targets. Extensive experiments on the Mixamo and ScanRet datasets demonstrate that our method produces plausible and coherent motions while significantly reducing interpenetration rates compared with other approaches.
HandSplat: Embedding-Driven Gaussian Splatting for High-Fidelity Hand Rendering
Mar 18, 2025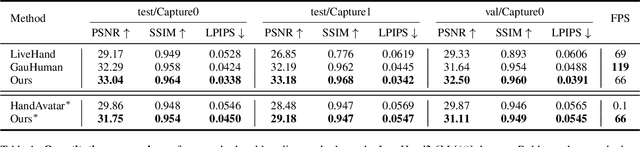
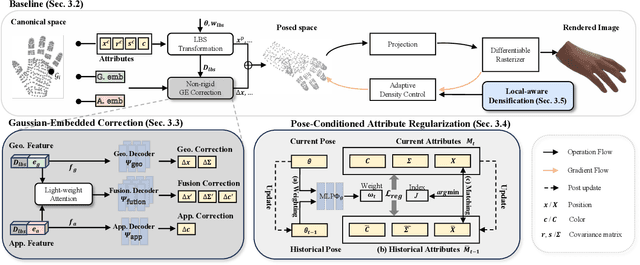
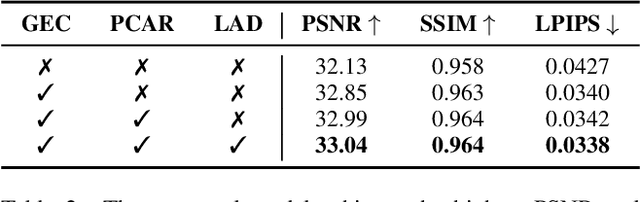

Existing 3D Gaussian Splatting (3DGS) methods for hand rendering rely on rigid skeletal motion with an oversimplified non-rigid motion model, which fails to capture fine geometric and appearance details. Additionally, they perform densification based solely on per-point gradients and process poses independently, ignoring spatial and temporal correlations. These limitations lead to geometric detail loss, temporal instability, and inefficient point distribution. To address these issues, we propose HandSplat, a novel Gaussian Splatting-based framework that enhances both fidelity and stability for hand rendering. To improve fidelity, we extend standard 3DGS attributes with implicit geometry and appearance embeddings for finer non-rigid motion modeling while preserving the static hand characteristic modeled by original 3DGS attributes. Additionally, we introduce a local gradient-aware densification strategy that dynamically refines Gaussian density in high-variation regions. To improve stability, we incorporate pose-conditioned attribute regularization to encourage attribute consistency across similar poses, mitigating temporal artifacts. Extensive experiments on InterHand2.6M demonstrate that HandSplat surpasses existing methods in fidelity and stability while achieving real-time performance. We will release the code and pre-trained models upon acceptance.
SuperCap: Multi-resolution Superpixel-based Image Captioning
Mar 11, 2025It has been a longstanding goal within image captioning to move beyond a dependence on object detection. We investigate using superpixels coupled with Vision Language Models (VLMs) to bridge the gap between detector-based captioning architectures and those that solely pretrain on large datasets. Our novel superpixel approach ensures that the model receives object-like features whilst the use of VLMs provides our model with open set object understanding. Furthermore, we extend our architecture to make use of multi-resolution inputs, allowing our model to view images in different levels of detail, and use an attention mechanism to determine which parts are most relevant to the caption. We demonstrate our model's performance with multiple VLMs and through a range of ablations detailing the impact of different architectural choices. Our full model achieves a competitive CIDEr score of $136.9$ on the COCO Karpathy split.
HanDrawer: Leveraging Spatial Information to Render Realistic Hands Using a Conditional Diffusion Model in Single Stage
Mar 03, 2025



Although diffusion methods excel in text-to-image generation, generating accurate hand gestures remains a major challenge, resulting in severe artifacts, such as incorrect number of fingers or unnatural gestures. To enable the diffusion model to learn spatial information to improve the quality of the hands generated, we propose HanDrawer, a module to condition the hand generation process. Specifically, we apply graph convolutional layers to extract the endogenous spatial structure and physical constraints implicit in MANO hand mesh vertices. We then align and fuse these spatial features with other modalities via cross-attention. The spatially fused features are used to guide a single stage diffusion model denoising process for high quality generation of the hand region. To improve the accuracy of spatial feature fusion, we propose a Position-Preserving Zero Padding (PPZP) fusion strategy, which ensures that the features extracted by HanDrawer are fused into the region of interest in the relevant layers of the diffusion model. HanDrawer learns the entire image features while paying special attention to the hand region thanks to an additional hand reconstruction loss combined with the denoising loss. To accurately train and evaluate our approach, we perform careful cleansing and relabeling of the widely used HaGRID hand gesture dataset and obtain high quality multimodal data. Quantitative and qualitative analyses demonstrate the state-of-the-art performance of our method on the HaGRID dataset through multiple evaluation metrics. Source code and our enhanced dataset will be released publicly if the paper is accepted.
ST-ITO: Controlling Audio Effects for Style Transfer with Inference-Time Optimization
Oct 28, 2024Audio production style transfer is the task of processing an input to impart stylistic elements from a reference recording. Existing approaches often train a neural network to estimate control parameters for a set of audio effects. However, these approaches are limited in that they can only control a fixed set of effects, where the effects must be differentiable or otherwise employ specialized training techniques. In this work, we introduce ST-ITO, Style Transfer with Inference-Time Optimization, an approach that instead searches the parameter space of an audio effect chain at inference. This method enables control of arbitrary audio effect chains, including unseen and non-differentiable effects. Our approach employs a learned metric of audio production style, which we train through a simple and scalable self-supervised pretraining strategy, along with a gradient-free optimizer. Due to the limited existing evaluation methods for audio production style transfer, we introduce a multi-part benchmark to evaluate audio production style metrics and style transfer systems. This evaluation demonstrates that our audio representation better captures attributes related to audio production and enables expressive style transfer via control of arbitrary audio effects.
Adaptive Multi-Modal Control of Digital Human Hand Synthesis Using a Region-Aware Cycle Loss
Sep 13, 2024



Diffusion models have shown their remarkable ability to synthesize images, including the generation of humans in specific poses. However, current models face challenges in adequately expressing conditional control for detailed hand pose generation, leading to significant distortion in the hand regions. To tackle this problem, we first curate the How2Sign dataset to provide richer and more accurate hand pose annotations. In addition, we introduce adaptive, multi-modal fusion to integrate characters' physical features expressed in different modalities such as skeleton, depth, and surface normal. Furthermore, we propose a novel Region-Aware Cycle Loss (RACL) that enables the diffusion model training to focus on improving the hand region, resulting in improved quality of generated hand gestures. More specifically, the proposed RACL computes a weighted keypoint distance between the full-body pose keypoints from the generated image and the ground truth, to generate higher-quality hand poses while balancing overall pose accuracy. Moreover, we use two hand region metrics, named hand-PSNR and hand-Distance for hand pose generation evaluations. Our experimental evaluations demonstrate the effectiveness of our proposed approach in improving the quality of digital human pose generation using diffusion models, especially the quality of the hand region. The source code is available at https://github.com/fuqifan/Region-Aware-Cycle-Loss.
Exploring Effective Mask Sampling Modeling for Neural Image Compression
Jun 09, 2023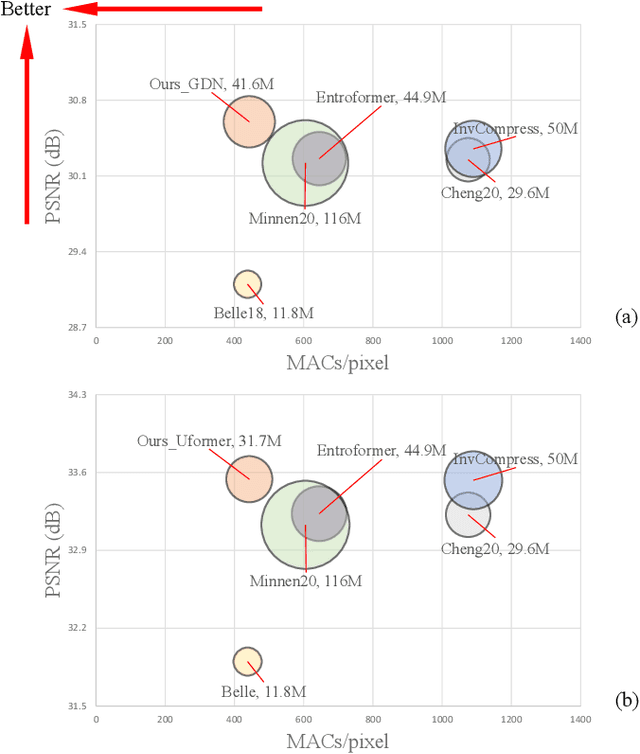


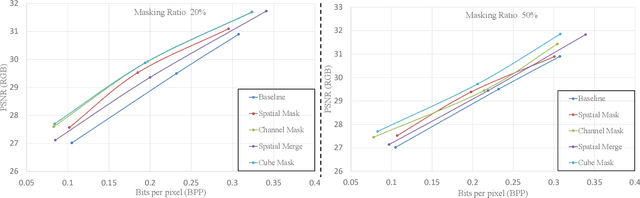
Image compression aims to reduce the information redundancy in images. Most existing neural image compression methods rely on side information from hyperprior or context models to eliminate spatial redundancy, but rarely address the channel redundancy. Inspired by the mask sampling modeling in recent self-supervised learning methods for natural language processing and high-level vision, we propose a novel pretraining strategy for neural image compression. Specifically, Cube Mask Sampling Module (CMSM) is proposed to apply both spatial and channel mask sampling modeling to image compression in the pre-training stage. Moreover, to further reduce channel redundancy, we propose the Learnable Channel Mask Module (LCMM) and the Learnable Channel Completion Module (LCCM). Our plug-and-play CMSM, LCMM, LCCM modules can apply to both CNN-based and Transformer-based architectures, significantly reduce the computational cost, and improve the quality of images. Experiments on the public Kodak and Tecnick datasets demonstrate that our method achieves competitive performance with lower computational complexity compared to state-of-the-art image compression methods.
NeRFVS: Neural Radiance Fields for Free View Synthesis via Geometry Scaffolds
Apr 13, 2023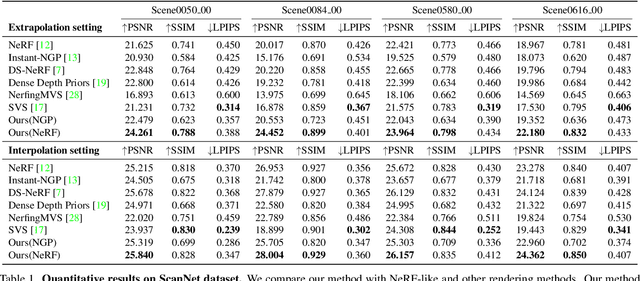
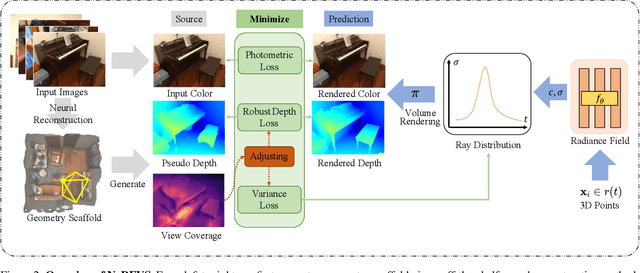
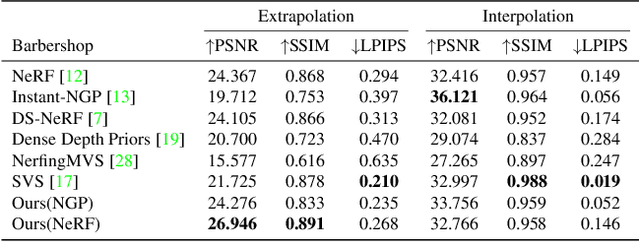

We present NeRFVS, a novel neural radiance fields (NeRF) based method to enable free navigation in a room. NeRF achieves impressive performance in rendering images for novel views similar to the input views while suffering for novel views that are significantly different from the training views. To address this issue, we utilize the holistic priors, including pseudo depth maps and view coverage information, from neural reconstruction to guide the learning of implicit neural representations of 3D indoor scenes. Concretely, an off-the-shelf neural reconstruction method is leveraged to generate a geometry scaffold. Then, two loss functions based on the holistic priors are proposed to improve the learning of NeRF: 1) A robust depth loss that can tolerate the error of the pseudo depth map to guide the geometry learning of NeRF; 2) A variance loss to regularize the variance of implicit neural representations to reduce the geometry and color ambiguity in the learning procedure. These two loss functions are modulated during NeRF optimization according to the view coverage information to reduce the negative influence brought by the view coverage imbalance. Extensive results demonstrate that our NeRFVS outperforms state-of-the-art view synthesis methods quantitatively and qualitatively on indoor scenes, achieving high-fidelity free navigation results.
Graph Neural Networks in Vision-Language Image Understanding: A Survey
Mar 07, 20232D image understanding is a complex problem within Computer Vision, but it holds the key to providing human level scene comprehension. It goes further than identifying the objects in an image, and instead it attempts to understand the scene. Solutions to this problem form the underpinning of a range of tasks, including image captioning, Visual Question Answering (VQA), and image retrieval. Graphs provide a natural way to represent the relational arrangement between objects in an image, and thus in recent years Graph Neural Networks (GNNs) have become a standard component of many 2D image understanding pipelines, becoming a core architectural component especially in the VQA group of tasks. In this survey, we review this rapidly evolving field and we provide a taxonomy of graph types used in 2D image understanding approaches, a comprehensive list of the GNN models used in this domain, and a roadmap of future potential developments. To the best of our knowledge, this is the first comprehensive survey that covers image captioning, visual question answering, and image retrieval techniques that focus on using GNNs as the main part of their architecture.