 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Effective Mask Sampling Modeling for Neural Image Compression
Paper and Code
Jun 09, 2023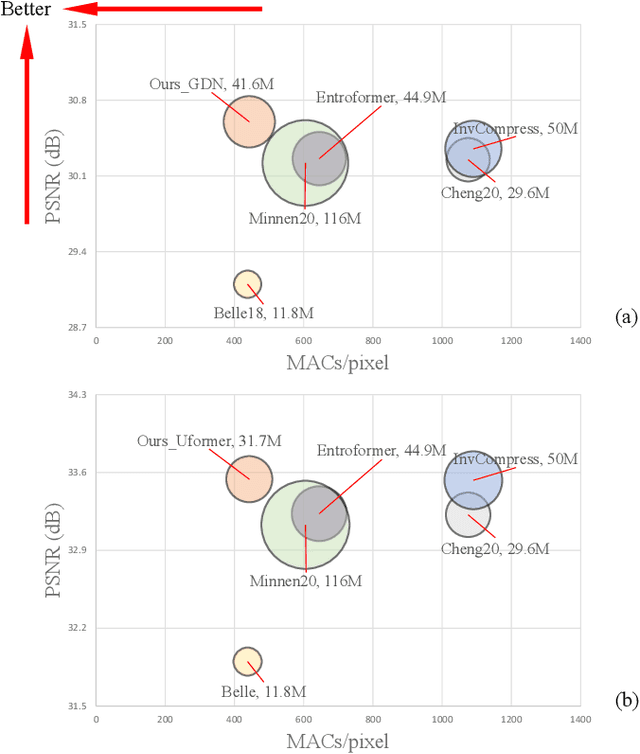


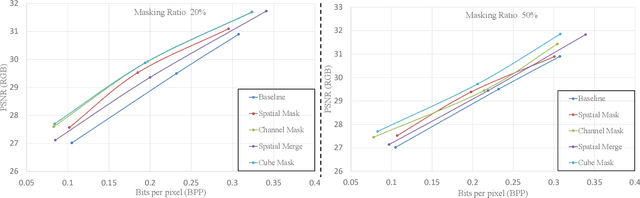
Image compression aims to reduce the information redundancy in images. Most existing neural image compression methods rely on side information from hyperprior or context models to eliminate spatial redundancy, but rarely address the channel redundancy. Inspired by the mask sampling modeling in recent self-supervised learning methods for natural language processing and high-level vision, we propose a novel pretraining strategy for neural image compression. Specifically, Cube Mask Sampling Module (CMSM) is proposed to apply both spatial and channel mask sampling modeling to image compression in the pre-training stage. Moreover, to further reduce channel redundancy, we propose the Learnable Channel Mask Module (LCMM) and the Learnable Channel Completion Module (LCCM). Our plug-and-play CMSM, LCMM, LCCM modules can apply to both CNN-based and Transformer-based architectures, significantly reduce the computational cost, and improve the quality of images. Experiments on the public Kodak and Tecnick datasets demonstrate that our method achieves competitive performance with lower computational complexity compared to state-of-the-art image compression methods.