 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Recent Advances in Data-driven Intelligent Control for Wireless Communication: A Comprehensive Survey
Aug 06, 2024The advent of next-generation wireless communication systems heralds an era characterized by high data rates, low latency, massive connectivity, and superior energy efficiency. These systems necessitate innovative and adaptive strategies for resource allocation and device behavior control in wireless networks. Traditional optimization-based methods have been found inadequate in meeting the complex demands of these emerging systems. As the volume of data continues to escalate, the integration of data-driven methods has become indispensable for enabling adaptive and intelligent control mechanisms in future wireless communication systems. This comprehensive survey explores recent advancements in data-driven methodologies applied to wireless communication networks. It focuses on developments over the past five years and their application to various control objectives within wireless cyber-physical systems. It encompasses critical areas such as link adaptation, user scheduling, spectrum allocation, beam management, power control, and the co-design of communication and control systems. We provide an in-depth exploration of the technical underpinnings that support these data-driven approaches, including the algorithms, models, and frameworks developed to enhance network performance and efficiency. We also examine the challenges that current data-driven algorithms face, particularly in the context of the dynamic and heterogeneous nature of next-generation wireless networks. The paper provides a critical analysis of these challenges and offers insights into potential solutions and future research directions. This includes discussing the adaptability, integration with 6G, and security of data-driven methods in the face of increasing network complexity and data volume.
Exploring Effective Mask Sampling Modeling for Neural Image Compression
Jun 09, 2023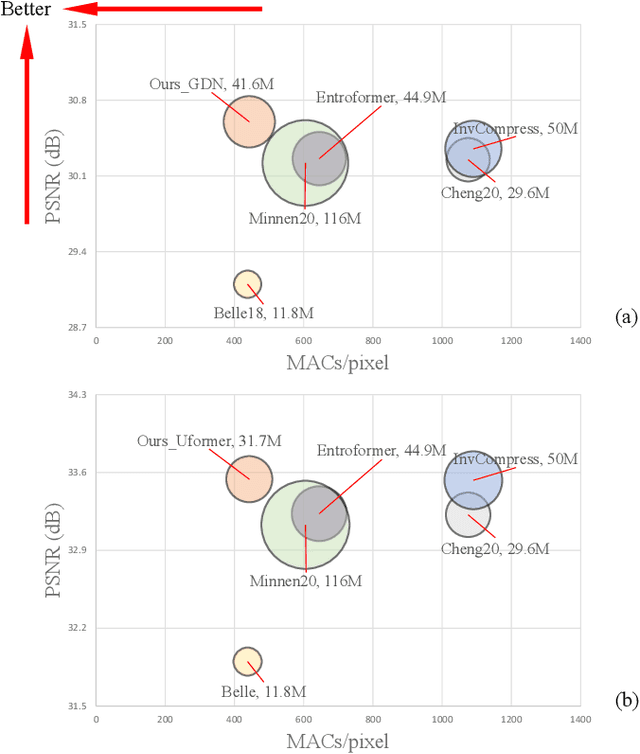


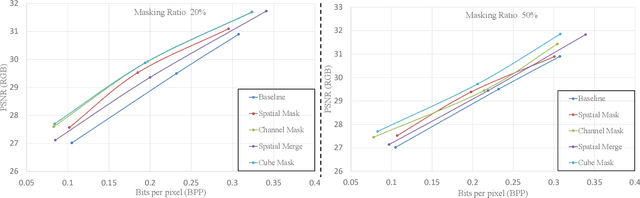
Image compression aims to reduce the information redundancy in images. Most existing neural image compression methods rely on side information from hyperprior or context models to eliminate spatial redundancy, but rarely address the channel redundancy. Inspired by the mask sampling modeling in recent self-supervised learning methods for natural language processing and high-level vision, we propose a novel pretraining strategy for neural image compression. Specifically, Cube Mask Sampling Module (CMSM) is proposed to apply both spatial and channel mask sampling modeling to image compression in the pre-training stage. Moreover, to further reduce channel redundancy, we propose the Learnable Channel Mask Module (LCMM) and the Learnable Channel Completion Module (LCCM). Our plug-and-play CMSM, LCMM, LCCM modules can apply to both CNN-based and Transformer-based architectures, significantly reduce the computational cost, and improve the quality of images. Experiments on the public Kodak and Tecnick datasets demonstrate that our method achieves competitive performance with lower computational complexity compared to state-of-the-art image compression methods.
Joint Channel Estimation and Feedback with Masked Token Transformers in Massive MIMO Systems
Jun 08, 2023When the base station has downlink channel status information (CSI), the huge potential of large-scale multiple input multiple output (MIMO) in frequency division duplex (FDD) mode can be fully exploited. In this paper, we propose a deep-learning-based joint channel estimation and feedback framework to realize channel estimation and feedback in massive MIMO systems. Specifically, we use traditional channel design rather than end-to-end methods. Our model contains two networks. The first network is a channel estimation network, which adopts a double loss design, and can accurately estimate the full channel information while removing channel noises. The second network is a compression and feedback network. Inspired by the masked token transformer, we propose a learnable mask token method to obtain excellent estimation and compression performance. The extensive simulation results and ablation studies show that our method outperforms state-of-the-art channel estimation and feedback methods in both separate and joint tasks.
A Stochastic Composite Augmented Lagrangian Method For Reinforcement Learning
May 20, 2021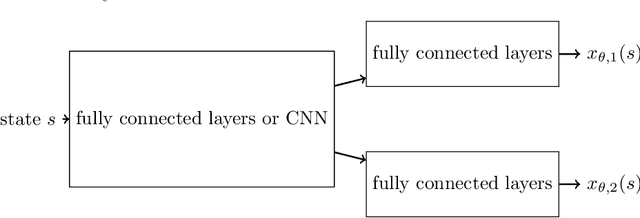
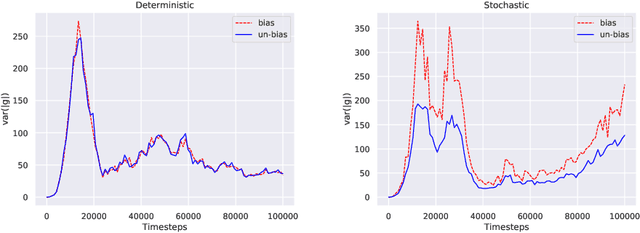
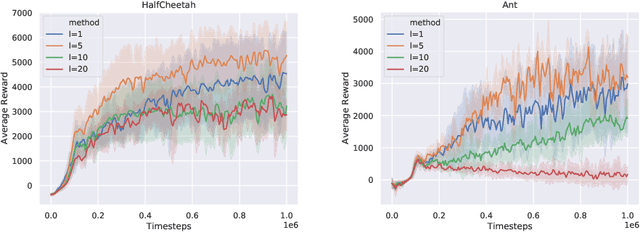
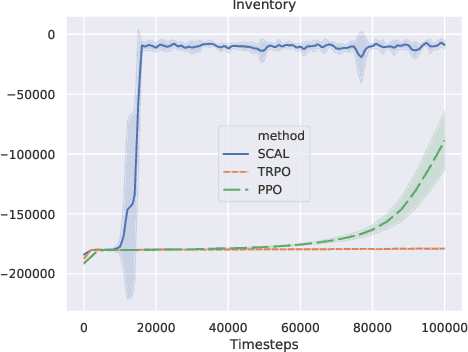
In this paper, we consider the linear programming (LP) formulation for deep reinforcement learning. The number of the constraints depends on the size of state and action spaces, which makes the problem intractable in large or continuous environments. The general augmented Lagrangian method suffers the double-sampling obstacle in solving the LP. Namely, the conditional expectations originated from the constraint functions and the quadratic penalties in the augmented Lagrangian function impose difficulties in sampling and evaluation. Motivated from the updates of the multipliers, we overcome the obstacles in minimizing the augmented Lagrangian function by replacing the intractable conditional expectations with the multipliers. Therefore, a deep parameterized augment Lagrangian method is proposed. Furthermore, the replacement provides a promising breakthrough to integrate the two steps in the augmented Lagrangian method into a single constrained problem. A general theoretical analysis shows that the solutions generated from a sequence of the constrained optimizations converge to the optimal solution of the LP if the error is controlled properly. A theoretical analysis on the quadratic penalty algorithm under neural tangent kernel setting shows the residual can be arbitrarily small if the parameter in network and optimization algorithm is chosen suitably. Preliminary experiments illustrate that our method is competitive to other state-of-the-art algorithms.