 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Synthetic CT Generation from Time-of-Flight Non-Attenutaion-Corrected PET for Whole-Body PET Attenuation Correction
Apr 10, 2025Positron Emission Tomography (PET) imaging requires accurate attenuation correction (AC) to account for photon loss due to tissue density variations. In PET/MR systems, computed tomography (CT), which offers a straightforward estimation of AC is not available. This study presents a deep learning approach to generate synthetic CT (sCT) images directly from Time-of-Flight (TOF) non-attenuation corrected (NAC) PET images, enhancing AC for PET/MR. We first evaluated models pre-trained on large-scale natural image datasets for a CT-to-CT reconstruction task, finding that the pre-trained model outperformed those trained solely on medical datasets. The pre-trained model was then fine-tuned using an institutional dataset of 35 TOF NAC PET and CT volume pairs, achieving the lowest mean absolute error (MAE) of 74.49 HU and highest peak signal-to-noise ratio (PSNR) of 28.66 dB within the body contour region. Visual assessments demonstrated improved reconstruction of both bone and soft tissue structures from TOF NAC PET images. This work highlights the effectiveness of using pre-trained deep learning models for medical image translation tasks. Future work will assess the impact of sCT on PET attenuation correction and explore additional neural network architectures and datasets to further enhance performance and practical applications in PET imaging.
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
Unbiased Evaluation of Large Language Models from a Causal Perspective
Feb 10, 2025



Benchmark contamination has become a significant concern in the LLM evaluation community. Previous Agents-as-an-Evaluator address this issue by involving agents in the generation of questions. Despite their success, the biases in Agents-as-an-Evaluator methods remain largely unexplored. In this paper, we present a theoretical formulation of evaluation bias, providing valuable insights into designing unbiased evaluation protocols. Furthermore, we identify two type of bias in Agents-as-an-Evaluator through carefully designed probing tasks on a minimal Agents-as-an-Evaluator setup. To address these issues, we propose the Unbiased Evaluator, an evaluation protocol that delivers a more comprehensive, unbiased, and interpretable assessment of LLMs.Extensive experiments reveal significant room for improvement in current LLMs. Additionally, we demonstrate that the Unbiased Evaluator not only offers strong evidence of benchmark contamination but also provides interpretable evaluation results.
Invariant debiasing learning for recommendation via biased imputation
Dec 28, 2024



Previous debiasing studies utilize unbiased data to make supervision of model training. They suffer from the high trial risks and experimental costs to obtain unbiased data. Recent research attempts to use invariant learning to detach the invariant preference of users for unbiased recommendations in an unsupervised way. However, it faces the drawbacks of low model accuracy and unstable prediction performance due to the losing cooperation with variant preference. In this paper, we experimentally demonstrate that invariant learning causes information loss by directly discarding the variant information, which reduces the generalization ability and results in the degradation of model performance in unbiased recommendations. Based on this consideration, we propose a novel lightweight knowledge distillation framework (KDDebias) to automatically learn the unbiased preference of users from both invariant and variant information. Specifically, the variant information is imputed to the invariant user preference in the distance-aware knowledge distillation process. Extensive experiments on three public datasets, i.e., Yahoo!R3, Coat, and MIND, show that with the biased imputation from the variant preference of users, our proposed method achieves significant improvements with less than 50% learning parameters compared to the SOTA unsupervised debiasing model in recommender systems. Our code are publicly available at https://github.com/BAI-LAB/KD-Debias.
Versatile Volumetric Medical Image Coding for Human-Machine Vision
Dec 12, 2024
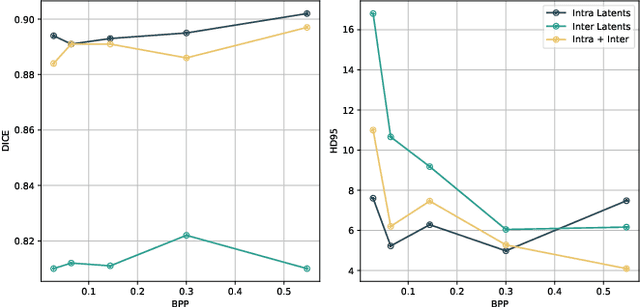
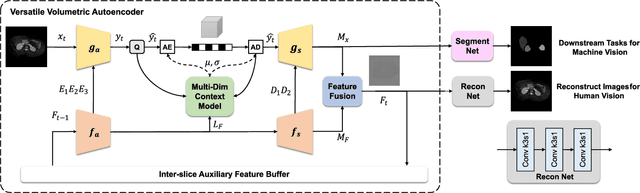
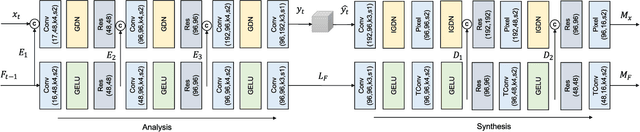
Neural image compression (NIC) has received considerable attention due to its significant advantages in feature representation and data optimization. However, most existing NIC methods for volumetric medical images focus solely on improving human-oriented perception. For these methods, data need to be decoded back to pixels for downstream machine learning analytics, which is a process that lowers the efficiency of diagnosis and treatment in modern digital healthcare scenarios. In this paper, we propose a Versatile Volumetric Medical Image Coding (VVMIC) framework for both human and machine vision, enabling various analytics of coded representations directly without decoding them into pixels. Considering the specific three-dimensional structure distinguished from natural frame images, a Versatile Volumetric Autoencoder (VVAE) module is crafted to learn the inter-slice latent representations to enhance the expressiveness of the current-slice latent representations, and to produce intermediate decoding features for downstream reconstruction and segmentation tasks. To further improve coding performance, a multi-dimensional context model is assembled by aggregating the inter-slice latent context with the spatial-channel context and the hierarchical hypercontext. Experimental results show that our VVMIC framework maintains high-quality image reconstruction for human vision while achieving accurate segmentation results for machine-vision tasks compared to a number of reported traditional and neural methods.
KG-Retriever: Efficient Knowledge Indexing for Retrieval-Augmented Large Language Models
Dec 07, 2024Large language models with retrieval-augmented generation encounter a pivotal challenge in intricate retrieval tasks, e.g., multi-hop question answering, which requires the model to navigate across multiple documents and generate comprehensive responses based on fragmented information. To tackle this challenge, we introduce a novel Knowledge Graph-based RAG framework with a hierarchical knowledge retriever, termed KG-Retriever. The retrieval indexing in KG-Retriever is constructed on a hierarchical index graph that consists of a knowledge graph layer and a collaborative document layer. The associative nature of graph structures is fully utilized to strengthen intra-document and inter-document connectivity, thereby fundamentally alleviating the information fragmentation problem and meanwhile improving the retrieval efficiency in cross-document retrieval of LLMs. With the coarse-grained collaborative information from neighboring documents and concise information from the knowledge graph, KG-Retriever achieves marked improvements on five public QA datasets, showing the effectiveness and efficiency of our proposed RAG framework.
Deep Learning for Longitudinal Gross Tumor Volume Segmentation in MRI-Guided Adaptive Radiotherapy for Head and Neck Cancer
Dec 01, 2024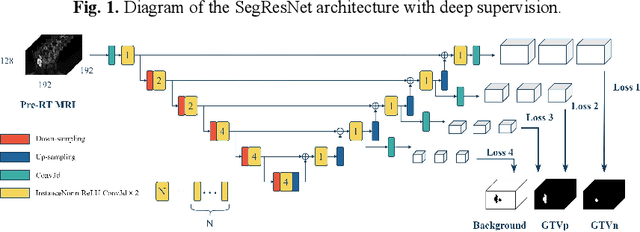
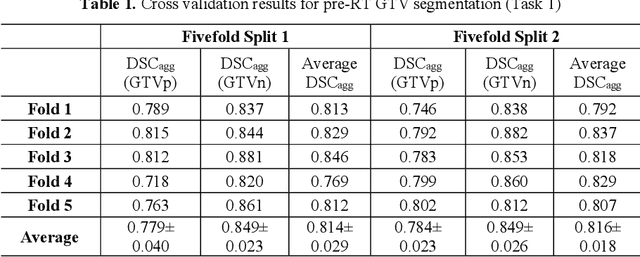
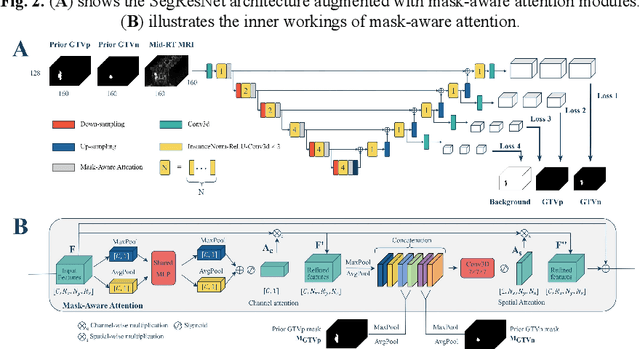
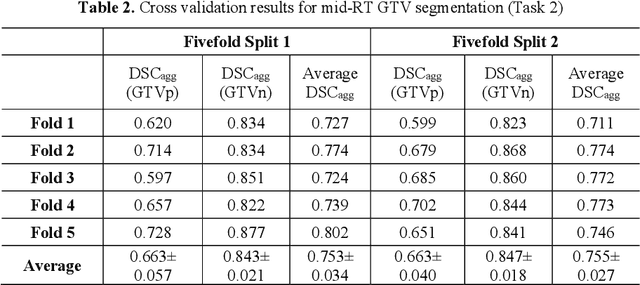
Accurate segmentation of gross tumor volume (GTV) is essential for effective MRI-guided adaptive radiotherapy (MRgART) in head and neck cancer. However, manual segmentation of the GTV over the course of therapy is time-consuming and prone to interobserver variability. Deep learning (DL) has the potential to overcome these challenges by automatically delineating GTVs. In this study, our team, $\textit{UW LAIR}$, tackled the challenges of both pre-radiotherapy (pre-RT) (Task 1) and mid-radiotherapy (mid-RT) (Task 2) tumor volume segmentation. To this end, we developed a series of DL models for longitudinal GTV segmentation. The backbone of our models for both tasks was SegResNet with deep supervision. For Task 1, we trained the model using a combined dataset of pre-RT and mid-RT MRI data, which resulted in the improved aggregated Dice similarity coefficient (DSCagg) on an internal testing set compared to models trained solely on pre-RT MRI data. In Task 2, we introduced mask-aware attention modules, enabling pre-RT GTV masks to influence intermediate features learned from mid-RT data. This attention-based approach yielded slight improvements over the baseline method, which concatenated mid-RT MRI with pre-RT GTV masks as input. In the final testing phase, the ensemble of 10 pre-RT segmentation models achieved an average DSCagg of 0.794, with 0.745 for primary GTV (GTVp) and 0.844 for metastatic lymph nodes (GTVn) in Task 1. For Task 2, the ensemble of 10 mid-RT segmentation models attained an average DSCagg of 0.733, with 0.607 for GTVp and 0.859 for GTVn, leading us to $\textbf{achieve 1st place}$. In summary, we presented a collection of DL models that could facilitate GTV segmentation in MRgART, offering the potential to streamline radiation oncology workflows. Our code and model weights are available at https://github.com/xtie97/HNTS-MRG24-UWLAIR.
SASWISE-UE: Segmentation and Synthesis with Interpretable Scalable Ensembles for Uncertainty Estimation
Nov 08, 2024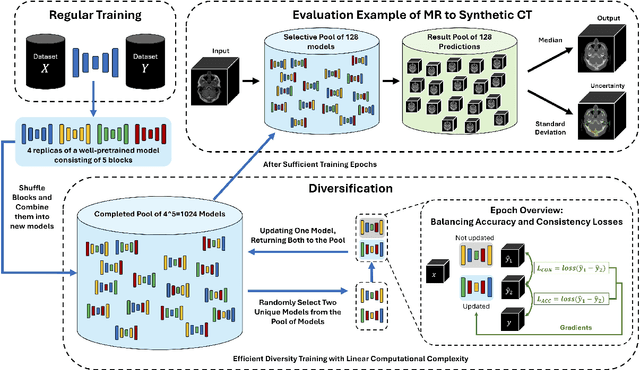
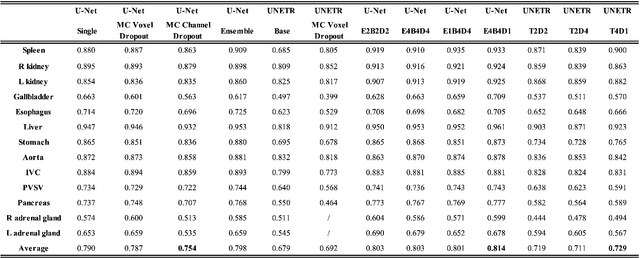
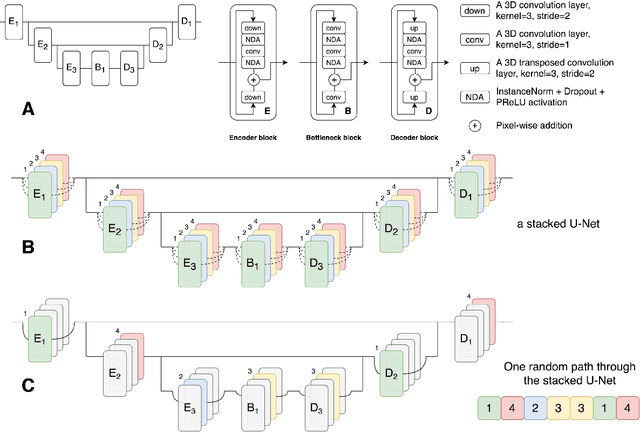
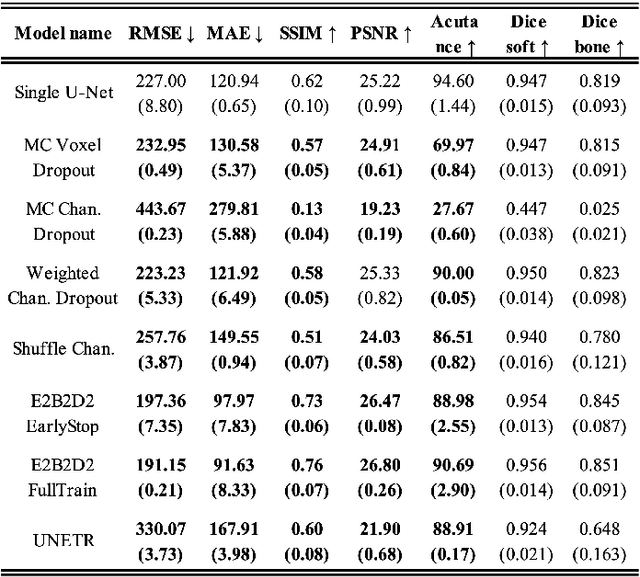
This paper introduces an efficient sub-model ensemble framework aimed at enhancing the interpretability of medical deep learning models, thus increasing their clinical applicability. By generating uncertainty maps, this framework enables end-users to evaluate the reliability of model outputs. We developed a strategy to develop diverse models from a single well-trained checkpoint, facilitating the training of a model family. This involves producing multiple outputs from a single input, fusing them into a final output, and estimating uncertainty based on output disagreements. Implemented using U-Net and UNETR models for segmentation and synthesis tasks, this approach was tested on CT body segmentation and MR-CT synthesis datasets. It achieved a mean Dice coefficient of 0.814 in segmentation and a Mean Absolute Error of 88.17 HU in synthesis, improved from 89.43 HU by pruning. Additionally, the framework was evaluated under corruption and undersampling, maintaining correlation between uncertainty and error, which highlights its robustness. These results suggest that the proposed approach not only maintains the performance of well-trained models but also enhances interpretability through effective uncertainty estimation, applicable to both convolutional and transformer models in a range of imaging tasks.