 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic CT Generation from Time-of-Flight Non-Attenutaion-Corrected PET for Whole-Body PET Attenuation Correction
Apr 10, 2025Positron Emission Tomography (PET) imaging requires accurate attenuation correction (AC) to account for photon loss due to tissue density variations. In PET/MR systems, computed tomography (CT), which offers a straightforward estimation of AC is not available. This study presents a deep learning approach to generate synthetic CT (sCT) images directly from Time-of-Flight (TOF) non-attenuation corrected (NAC) PET images, enhancing AC for PET/MR. We first evaluated models pre-trained on large-scale natural image datasets for a CT-to-CT reconstruction task, finding that the pre-trained model outperformed those trained solely on medical datasets. The pre-trained model was then fine-tuned using an institutional dataset of 35 TOF NAC PET and CT volume pairs, achieving the lowest mean absolute error (MAE) of 74.49 HU and highest peak signal-to-noise ratio (PSNR) of 28.66 dB within the body contour region. Visual assessments demonstrated improved reconstruction of both bone and soft tissue structures from TOF NAC PET images. This work highlights the effectiveness of using pre-trained deep learning models for medical image translation tasks. Future work will assess the impact of sCT on PET attenuation correction and explore additional neural network architectures and datasets to further enhance performance and practical applications in PET imaging.
SASWISE-UE: Segmentation and Synthesis with Interpretable Scalable Ensembles for Uncertainty Estimation
Nov 08, 2024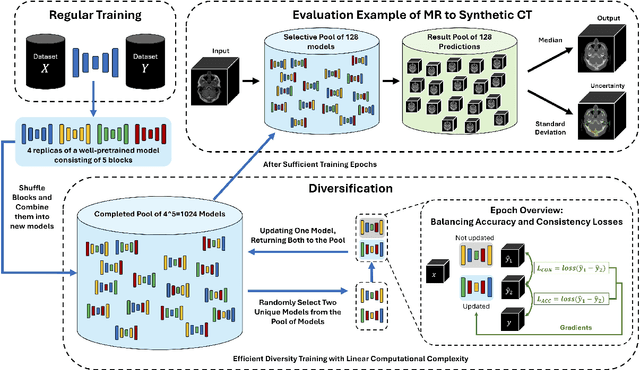
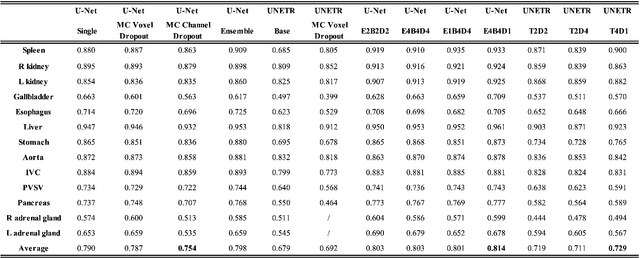
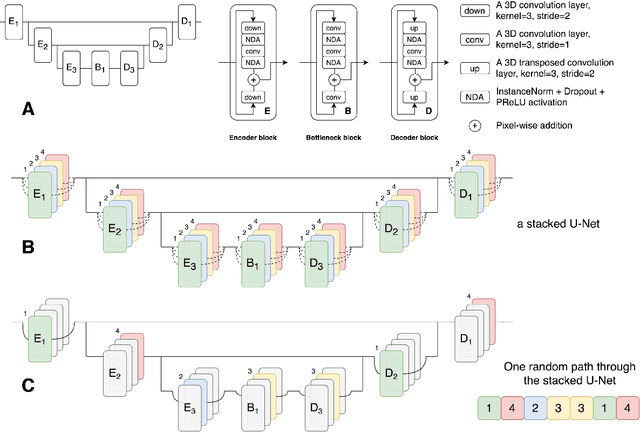
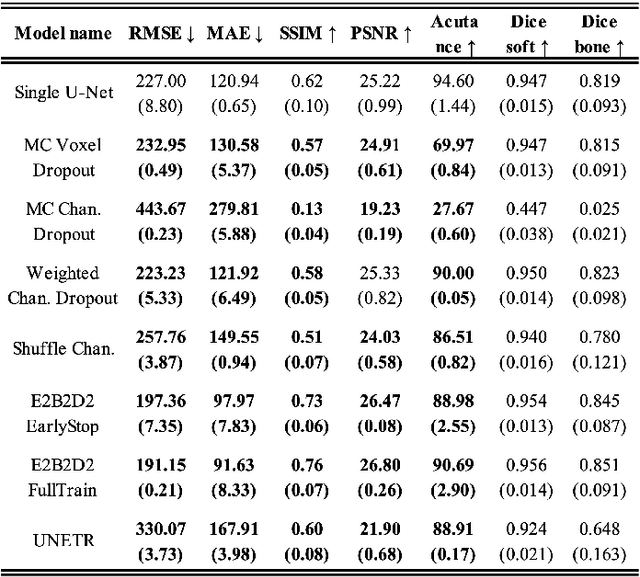
This paper introduces an efficient sub-model ensemble framework aimed at enhancing the interpretability of medical deep learning models, thus increasing their clinical applicability. By generating uncertainty maps, this framework enables end-users to evaluate the reliability of model outputs. We developed a strategy to develop diverse models from a single well-trained checkpoint, facilitating the training of a model family. This involves producing multiple outputs from a single input, fusing them into a final output, and estimating uncertainty based on output disagreements. Implemented using U-Net and UNETR models for segmentation and synthesis tasks, this approach was tested on CT body segmentation and MR-CT synthesis datasets. It achieved a mean Dice coefficient of 0.814 in segmentation and a Mean Absolute Error of 88.17 HU in synthesis, improved from 89.43 HU by pruning. Additionally, the framework was evaluated under corruption and undersampling, maintaining correlation between uncertainty and error, which highlights its robustness. These results suggest that the proposed approach not only maintains the performance of well-trained models but also enhances interpretability through effective uncertainty estimation, applicable to both convolutional and transformer models in a range of imaging tasks.
Mind the Gap: A Generalized Approach for Cross-Modal Embedding Alignment
Oct 30, 2024Retrieval-Augmented Generation (RAG) systems enhance text generation by incorporating external knowledge but often struggle when retrieving context across different text modalities due to semantic gaps. We introduce a generalized projection-based method, inspired by adapter modules in transfer learning, that efficiently bridges these gaps between various text types, such as programming code and pseudocode, or English and French sentences. Our approach emphasizes speed, accuracy, and data efficiency, requiring minimal resources for training and inference. By aligning embeddings from heterogeneous text modalities into a unified space through a lightweight projection network, our model significantly outperforms traditional retrieval methods like the Okapi BM25 algorithm and models like Dense Passage Retrieval (DPR), while approaching the accuracy of Sentence Transformers. Extensive evaluations demonstrate the effectiveness and generalizability of our method across different tasks, highlighting its potential for real-time, resource-constrained applications.
MedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging
Oct 09, 2024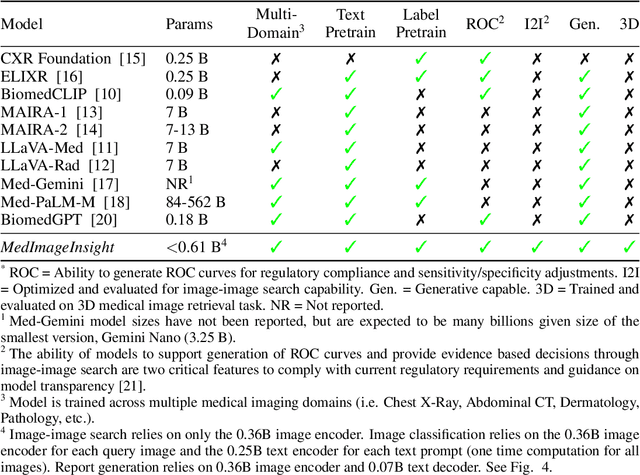
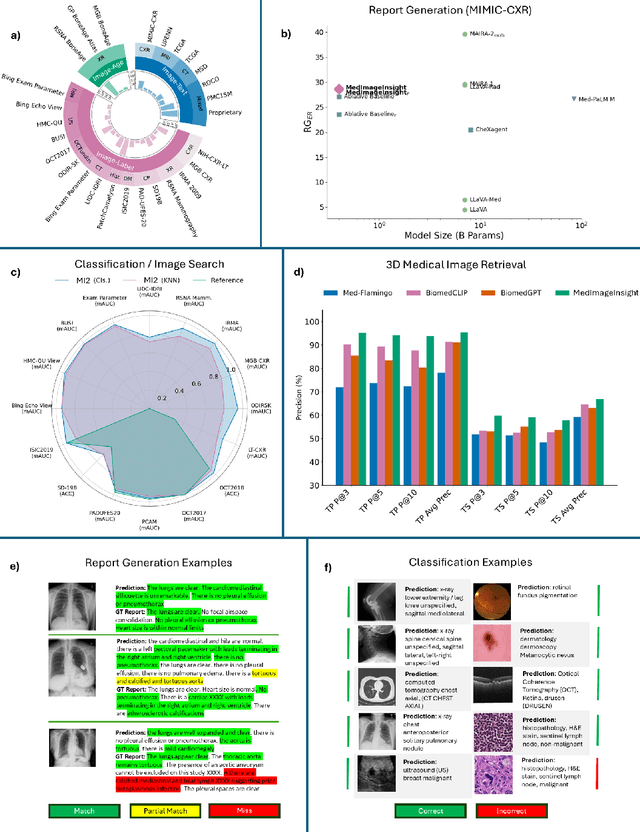
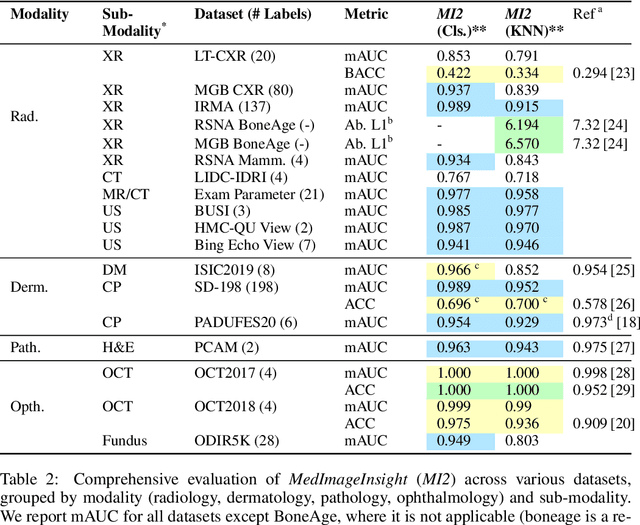
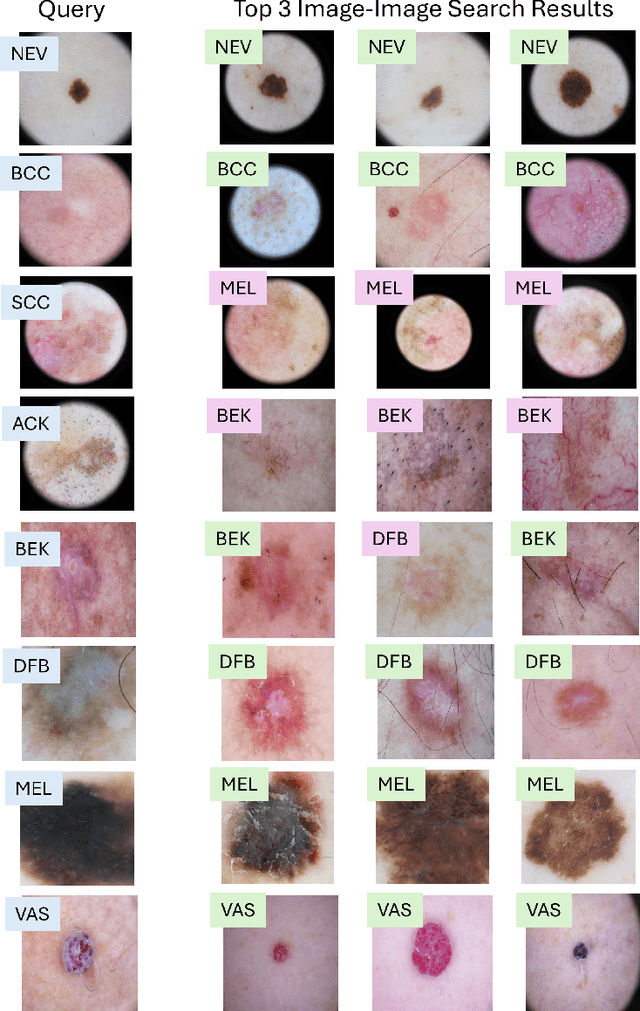
In this work, we present MedImageInsight, an open-source medical imaging embedding model. MedImageInsight is trained on medical images with associated text and labels across a diverse collection of domains, including X-Ray, CT, MRI, dermoscopy, OCT, fundus photography, ultrasound, histopathology, and mammography. Rigorous evaluations demonstrate MedImageInsight's ability to achieve state-of-the-art (SOTA) or human expert level performance across classification, image-image search, and fine-tuning tasks. Specifically, on public datasets, MedImageInsight achieves SOTA in CT 3D medical image retrieval, as well as SOTA in disease classification and search for chest X-ray, dermatology, and OCT imaging. Furthermore, MedImageInsight achieves human expert performance in bone age estimation (on both public and partner data), as well as AUC above 0.9 in most other domains. When paired with a text decoder, MedImageInsight achieves near SOTA level single image report findings generation with less than 10\% the parameters of other models. Compared to fine-tuning GPT-4o with only MIMIC-CXR data for the same task, MedImageInsight outperforms in clinical metrics, but underperforms on lexical metrics where GPT-4o sets a new SOTA. Importantly for regulatory purposes, MedImageInsight can generate ROC curves, adjust sensitivity and specificity based on clinical need, and provide evidence-based decision support through image-image search (which can also enable retrieval augmented generation). In an independent clinical evaluation of image-image search in chest X-ray, MedImageInsight outperformed every other publicly available foundation model evaluated by large margins (over 6 points AUC), and significantly outperformed other models in terms of AI fairness (across age and gender). We hope releasing MedImageInsight will help enhance collective progress in medical imaging AI research and development.