 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRep3D: Re-parameterize Large 3D Kernels with Low-Rank Receptive Modeling for Medical Imaging
May 26, 2025In contrast to vision transformers, which model long-range dependencies through global self-attention, large kernel convolutions provide a more efficient and scalable alternative, particularly in high-resolution 3D volumetric settings. However, naively increasing kernel size often leads to optimization instability and degradation in performance. Motivated by the spatial bias observed in effective receptive fields (ERFs), we hypothesize that different kernel elements converge at variable rates during training. To support this, we derive a theoretical connection between element-wise gradients and first-order optimization, showing that structurally re-parameterized convolution blocks inherently induce spatially varying learning rates. Building on this insight, we introduce Rep3D, a 3D convolutional framework that incorporates a learnable spatial prior into large kernel training. A lightweight two-stage modulation network generates a receptive-biased scaling mask, adaptively re-weighting kernel updates and enabling local-to-global convergence behavior. Rep3D adopts a plain encoder design with large depthwise convolutions, avoiding the architectural complexity of multi-branch compositions. We evaluate Rep3D on five challenging 3D segmentation benchmarks and demonstrate consistent improvements over state-of-the-art baselines, including transformer-based and fixed-prior re-parameterization methods. By unifying spatial inductive bias with optimization-aware learning, Rep3D offers an interpretable, and scalable solution for 3D medical image analysis. The source code is publicly available at https://github.com/leeh43/Rep3D.
WaveFormer: A 3D Transformer with Wavelet-Driven Feature Representation for Efficient Medical Image Segmentation
Apr 01, 2025Transformer-based architectures have advanced medical image analysis by effectively modeling long-range dependencies, yet they often struggle in 3D settings due to substantial memory overhead and insufficient capture of fine-grained local features. We address these limitations with WaveFormer, a novel 3D-transformer that: i) leverages the fundamental frequency-domain properties of features for contextual representation, and ii) is inspired by the top-down mechanism of the human visual recognition system, making it a biologically motivated architecture. By employing discrete wavelet transformations (DWT) at multiple scales, WaveFormer preserves both global context and high-frequency details while replacing heavy upsampling layers with efficient wavelet-based summarization and reconstruction. This significantly reduces the number of parameters, which is critical for real-world deployment where computational resources and training times are constrained. Furthermore, the model is generic and easily adaptable to diverse applications. Evaluations on BraTS2023, FLARE2021, and KiTS2023 demonstrate performance on par with state-of-the-art methods while offering substantially lower computational complexity.
Multi-Modal Mamba Modeling for Survival Prediction (M4Survive): Adapting Joint Foundation Model Representations
Mar 13, 2025Accurate survival prediction in oncology requires integrating diverse imaging modalities to capture the complex interplay of tumor biology. Traditional single-modality approaches often fail to leverage the complementary insights provided by radiological and pathological assessments. In this work, we introduce M4Survive (Multi-Modal Mamba Modeling for Survival Prediction), a novel framework that learns joint foundation model representations using efficient adapter networks. Our approach dynamically fuses heterogeneous embeddings from a foundation model repository (e.g., MedImageInsight, BiomedCLIP, Prov-GigaPath, UNI2-h), creating a correlated latent space optimized for survival risk estimation. By leveraging Mamba-based adapters, M4Survive enables efficient multi-modal learning while preserving computational efficiency. Experimental evaluations on benchmark datasets demonstrate that our approach outperforms both unimodal and traditional static multi-modal baselines in survival prediction accuracy. This work underscores the potential of foundation model-driven multi-modal fusion in advancing precision oncology and predictive analytics.
Boltzmann Attention Sampling for Image Analysis with Small Objects
Mar 04, 2025Detecting and segmenting small objects, such as lung nodules and tumor lesions, remains a critical challenge in image analysis. These objects often occupy less than 0.1% of an image, making traditional transformer architectures inefficient and prone to performance degradation due to redundant attention computations on irrelevant regions. Existing sparse attention mechanisms rely on rigid hierarchical structures, which are poorly suited for detecting small, variable, and uncertain object locations. In this paper, we propose BoltzFormer, a novel transformer-based architecture designed to address these challenges through dynamic sparse attention. BoltzFormer identifies and focuses attention on relevant areas by modeling uncertainty using a Boltzmann distribution with an annealing schedule. Initially, a higher temperature allows broader area sampling in early layers, when object location uncertainty is greatest. As the temperature decreases in later layers, attention becomes more focused, enhancing efficiency and accuracy. BoltzFormer seamlessly integrates into existing transformer architectures via a modular Boltzmann attention sampling mechanism. Comprehensive evaluations on benchmark datasets demonstrate that BoltzFormer significantly improves segmentation performance for small objects while reducing attention computation by an order of magnitude compared to previous state-of-the-art methods.
Brain age identification from diffusion MRI synergistically predicts neurodegenerative disease
Oct 29, 2024



Estimated brain age from magnetic resonance image (MRI) and its deviation from chronological age can provide early insights into potential neurodegenerative diseases, supporting early detection and implementation of prevention strategies. Diffusion MRI (dMRI), a widely used modality for brain age estimation, presents an opportunity to build an earlier biomarker for neurodegenerative disease prediction because it captures subtle microstructural changes that precede more perceptible macrostructural changes. However, the coexistence of macro- and micro-structural information in dMRI raises the question of whether current dMRI-based brain age estimation models are leveraging the intended microstructural information or if they inadvertently rely on the macrostructural information. To develop a microstructure-specific brain age, we propose a method for brain age identification from dMRI that minimizes the model's use of macrostructural information by non-rigidly registering all images to a standard template. Imaging data from 13,398 participants across 12 datasets were used for the training and evaluation. We compare our brain age models, trained with and without macrostructural information minimized, with an architecturally similar T1-weighted (T1w) MRI-based brain age model and two state-of-the-art T1w MRI-based brain age models that primarily use macrostructural information. We observe difference between our dMRI-based brain age and T1w MRI-based brain age across stages of neurodegeneration, with dMRI-based brain age being older than T1w MRI-based brain age in participants transitioning from cognitively normal (CN) to mild cognitive impairment (MCI), but younger in participants already diagnosed with Alzheimer's disease (AD). Approximately 4 years before MCI diagnosis, dMRI-based brain age yields better performance than T1w MRI-based brain ages in predicting transition from CN to MCI.
MedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging
Oct 09, 2024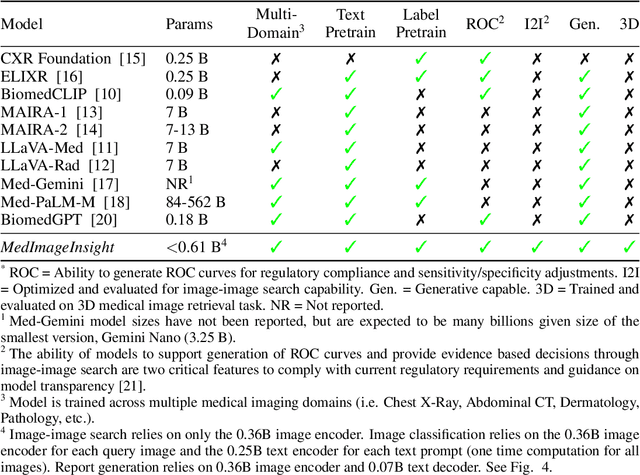
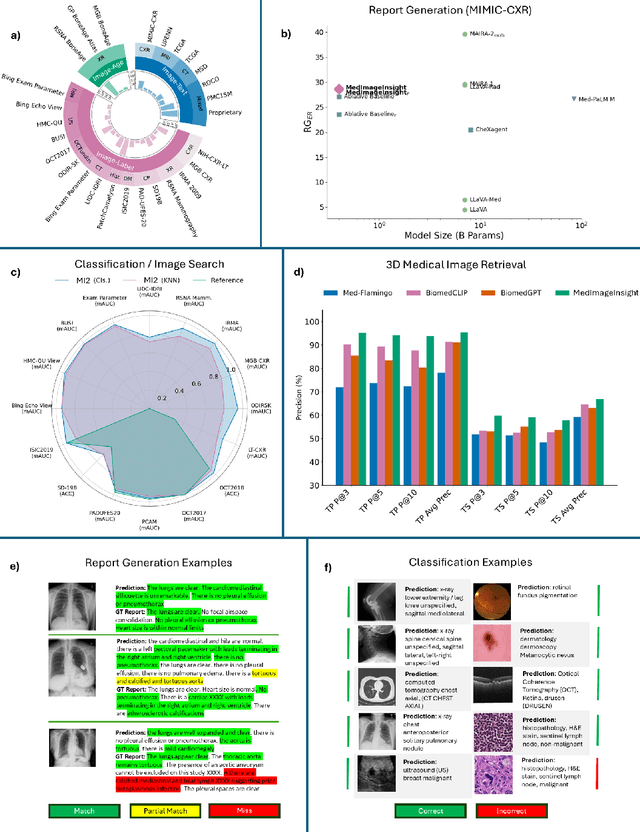
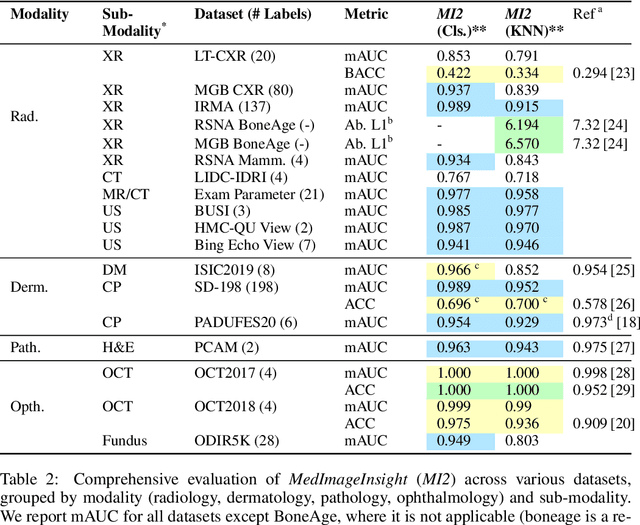
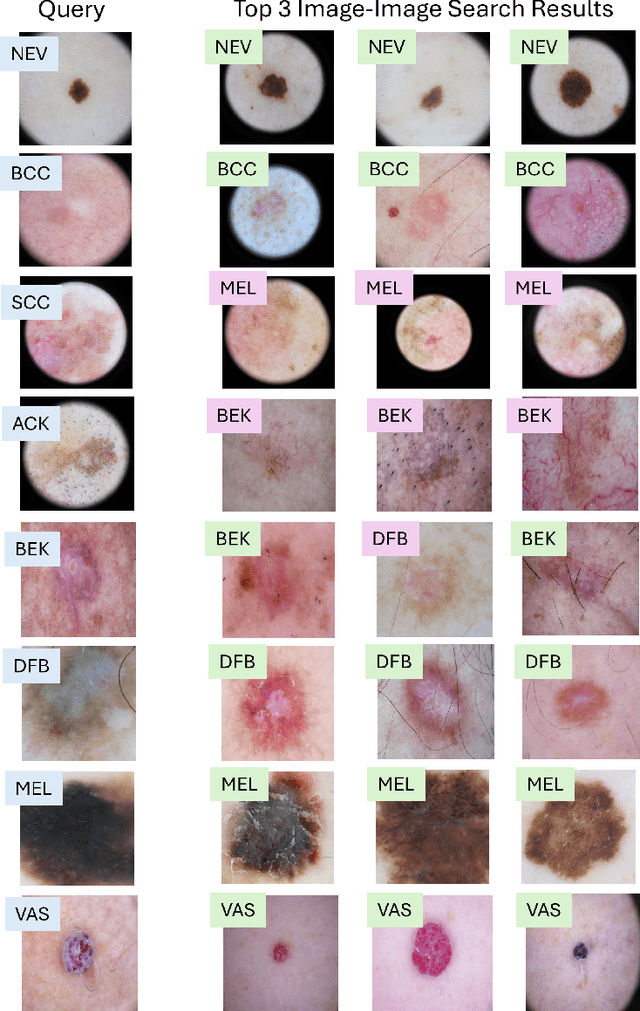
In this work, we present MedImageInsight, an open-source medical imaging embedding model. MedImageInsight is trained on medical images with associated text and labels across a diverse collection of domains, including X-Ray, CT, MRI, dermoscopy, OCT, fundus photography, ultrasound, histopathology, and mammography. Rigorous evaluations demonstrate MedImageInsight's ability to achieve state-of-the-art (SOTA) or human expert level performance across classification, image-image search, and fine-tuning tasks. Specifically, on public datasets, MedImageInsight achieves SOTA in CT 3D medical image retrieval, as well as SOTA in disease classification and search for chest X-ray, dermatology, and OCT imaging. Furthermore, MedImageInsight achieves human expert performance in bone age estimation (on both public and partner data), as well as AUC above 0.9 in most other domains. When paired with a text decoder, MedImageInsight achieves near SOTA level single image report findings generation with less than 10\% the parameters of other models. Compared to fine-tuning GPT-4o with only MIMIC-CXR data for the same task, MedImageInsight outperforms in clinical metrics, but underperforms on lexical metrics where GPT-4o sets a new SOTA. Importantly for regulatory purposes, MedImageInsight can generate ROC curves, adjust sensitivity and specificity based on clinical need, and provide evidence-based decision support through image-image search (which can also enable retrieval augmented generation). In an independent clinical evaluation of image-image search in chest X-ray, MedImageInsight outperformed every other publicly available foundation model evaluated by large margins (over 6 points AUC), and significantly outperformed other models in terms of AI fairness (across age and gender). We hope releasing MedImageInsight will help enhance collective progress in medical imaging AI research and development.
Enhancing Single-Slice Segmentation with 3D-to-2D Unpaired Scan Distillation
Jun 18, 2024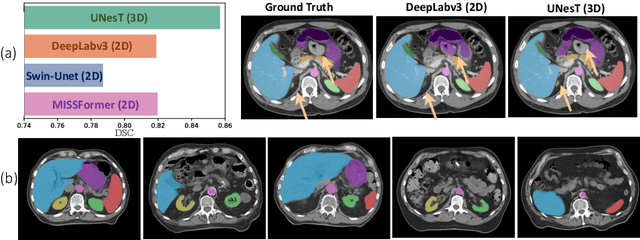
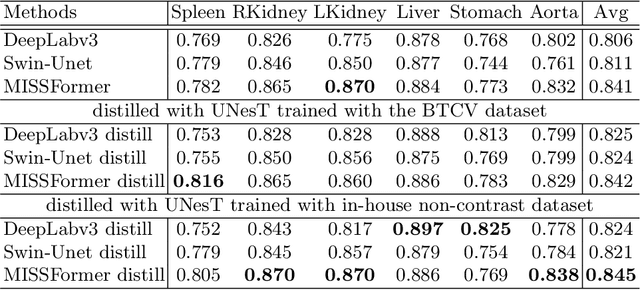
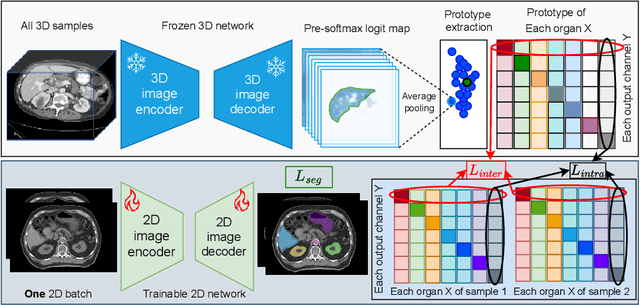
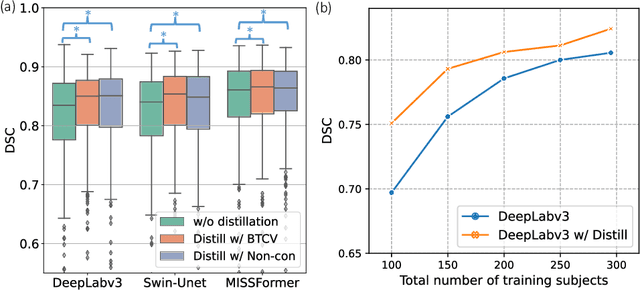
2D single-slice abdominal computed tomography (CT) enables the assessment of body habitus and organ health with low radiation exposure. However, single-slice data necessitates the use of 2D networks for segmentation, but these networks often struggle to capture contextual information effectively. Consequently, even when trained on identical datasets, 3D networks typically achieve superior segmentation results. In this work, we propose a novel 3D-to-2D distillation framework, leveraging pre-trained 3D models to enhance 2D single-slice segmentation. Specifically, we extract the prediction distribution centroid from the 3D representations, to guide the 2D student by learning intra- and inter-class correlation. Unlike traditional knowledge distillation methods that require the same data input, our approach employs unpaired 3D CT scans with any contrast to guide the 2D student model. Experiments conducted on 707 subjects from the single-slice Baltimore Longitudinal Study of Aging (BLSA) dataset demonstrate that state-of-the-art 2D multi-organ segmentation methods can benefit from the 3D teacher model, achieving enhanced performance in single-slice multi-organ segmentation. Notably, our approach demonstrates considerable efficacy in low-data regimes, outperforming the model trained with all available training subjects even when utilizing only 200 training subjects. Thus, this work underscores the potential to alleviate manual annotation burdens.
BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once
May 21, 2024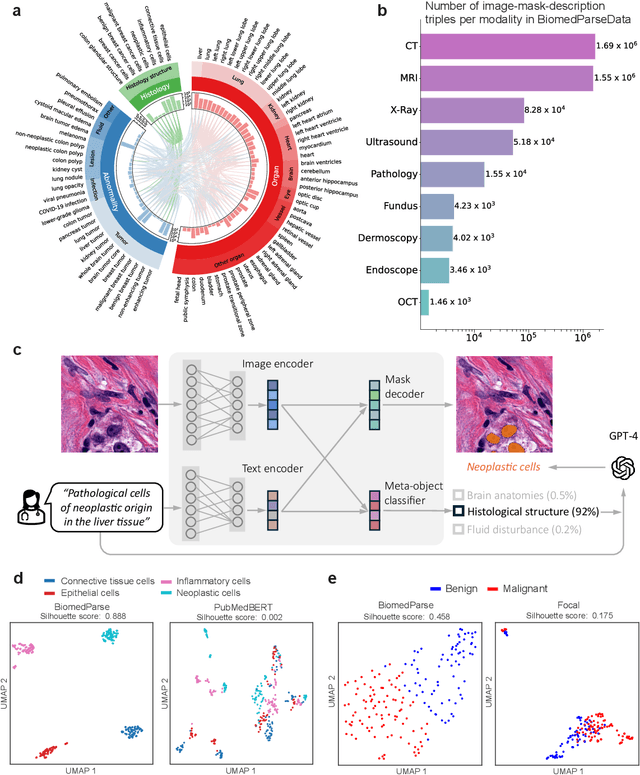
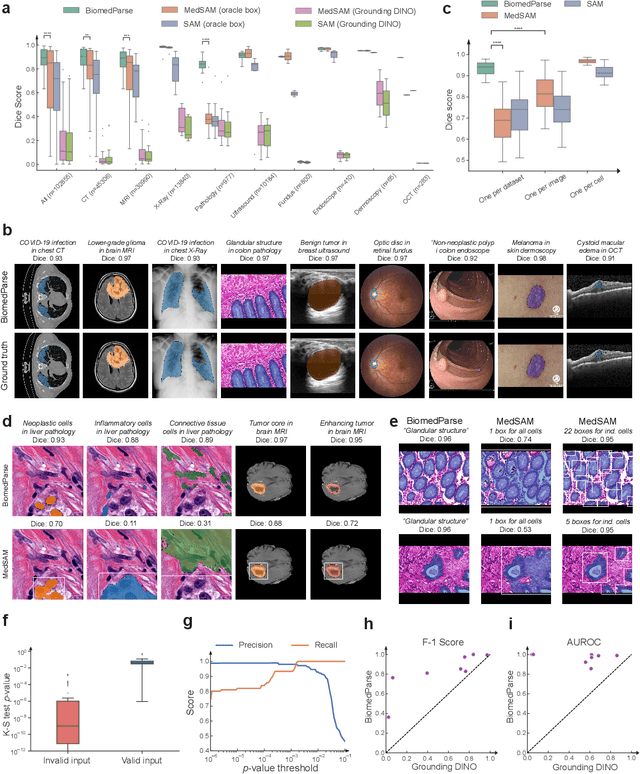
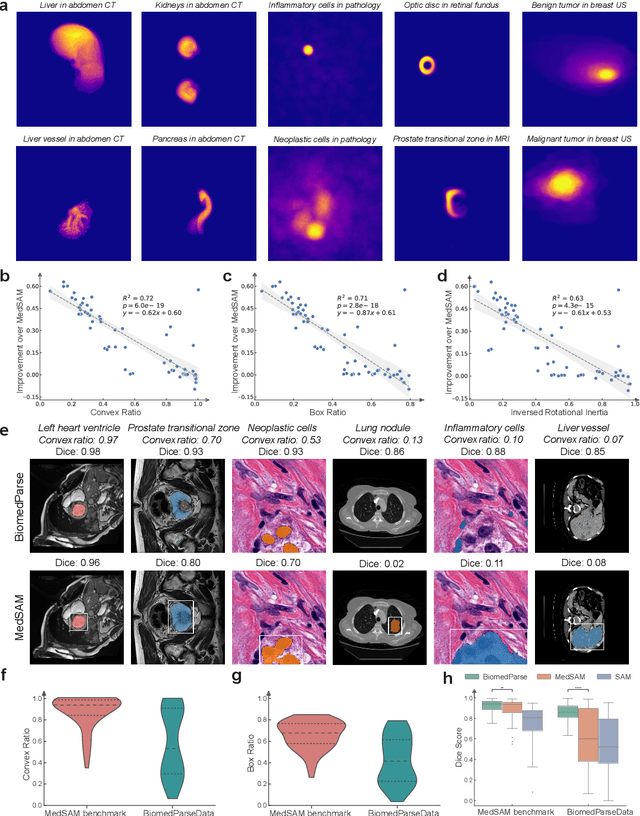
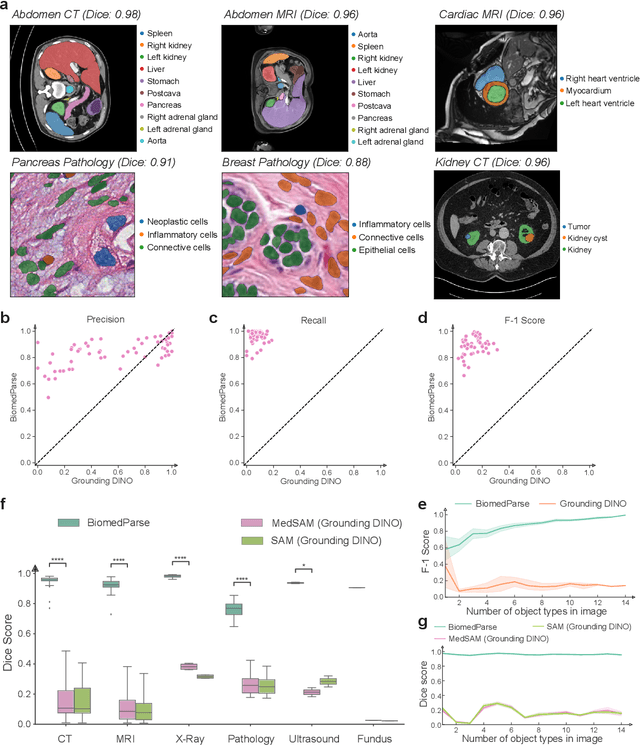
Biomedical image analysis is fundamental for biomedical discovery in cell biology, pathology, radiology, and many other biomedical domains. Holistic image analysis comprises interdependent subtasks such as segmentation, detection, and recognition of relevant objects. Here, we propose BiomedParse, a biomedical foundation model for imaging parsing that can jointly conduct segmentation, detection, and recognition for 82 object types across 9 imaging modalities. Through joint learning, we can improve accuracy for individual tasks and enable novel applications such as segmenting all relevant objects in an image through a text prompt, rather than requiring users to laboriously specify the bounding box for each object. We leveraged readily available natural-language labels or descriptions accompanying those datasets and use GPT-4 to harmonize the noisy, unstructured text information with established biomedical object ontologies. We created a large dataset comprising over six million triples of image, segmentation mask, and textual description. On image segmentation, we showed that BiomedParse is broadly applicable, outperforming state-of-the-art methods on 102,855 test image-mask-label triples across 9 imaging modalities (everything). On object detection, which aims to locate a specific object of interest, BiomedParse again attained state-of-the-art performance, especially on objects with irregular shapes (everywhere). On object recognition, which aims to identify all objects in a given image along with their semantic types, we showed that BiomedParse can simultaneously segment and label all biomedical objects in an image (all at once). In summary, BiomedParse is an all-in-one tool for biomedical image analysis by jointly solving segmentation, detection, and recognition for all major biomedical image modalities, paving the path for efficient and accurate image-based biomedical discovery.
Nucleus subtype classification using inter-modality learning
Jan 29, 2024Understanding the way cells communicate, co-locate, and interrelate is essential to understanding human physiology. Hematoxylin and eosin (H&E) staining is ubiquitously available both for clinical studies and research. The Colon Nucleus Identification and Classification (CoNIC) Challenge has recently innovated on robust artificial intelligence labeling of six cell types on H&E stains of the colon. However, this is a very small fraction of the number of potential cell classification types. Specifically, the CoNIC Challenge is unable to classify epithelial subtypes (progenitor, endocrine, goblet), lymphocyte subtypes (B, helper T, cytotoxic T), or connective subtypes (fibroblasts, stromal). In this paper, we propose to use inter-modality learning to label previously un-labelable cell types on virtual H&E. We leveraged multiplexed immunofluorescence (MxIF) histology imaging to identify 14 subclasses of cell types. We performed style transfer to synthesize virtual H&E from MxIF and transferred the higher density labels from MxIF to these virtual H&E images. We then evaluated the efficacy of learning in this approach. We identified helper T and progenitor nuclei with positive predictive values of $0.34 \pm 0.15$ (prevalence $0.03 \pm 0.01$) and $0.47 \pm 0.1$ (prevalence $0.07 \pm 0.02$) respectively on virtual H&E. This approach represents a promising step towards automating annotation in digital pathology.
Foundation Models for Biomedical Image Segmentation: A Survey
Jan 15, 2024Recent advancements in biomedical image analysis have been significantly driven by the Segment Anything Model (SAM). This transformative technology, originally developed for general-purpose computer vision, has found rapid application in medical image processing. Within the last year, marked by over 100 publications, SAM has demonstrated its prowess in zero-shot learning adaptations for medical imaging. The fundamental premise of SAM lies in its capability to segment or identify objects in images without prior knowledge of the object type or imaging modality. This approach aligns well with tasks achievable by the human visual system, though its application in non-biological vision contexts remains more theoretically challenging. A notable feature of SAM is its ability to adjust segmentation according to a specified resolution scale or area of interest, akin to semantic priming. This adaptability has spurred a wave of creativity and innovation in applying SAM to medical imaging. Our review focuses on the period from April 1, 2023, to September 30, 2023, a critical first six months post-initial publication. We examine the adaptations and integrations of SAM necessary to address longstanding clinical challenges, particularly in the context of 33 open datasets covered in our analysis. While SAM approaches or achieves state-of-the-art performance in numerous applications, it falls short in certain areas, such as segmentation of the carotid artery, adrenal glands, optic nerve, and mandible bone. Our survey delves into the innovative techniques where SAM's foundational approach excels and explores the core concepts in translating and applying these models effectively in diverse medical imaging scenarios.