 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025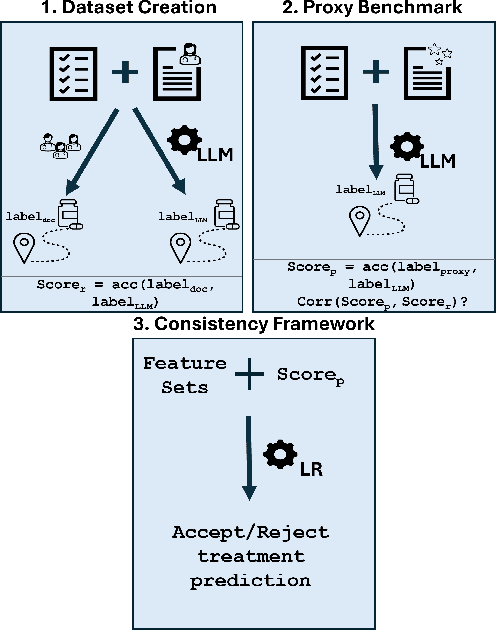
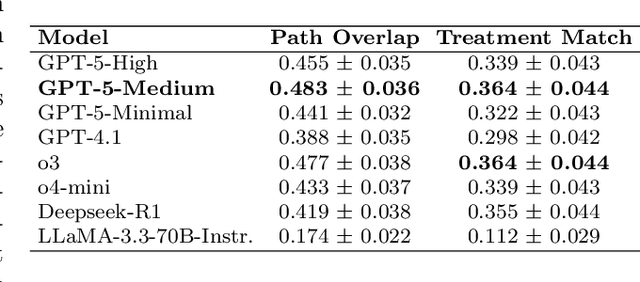
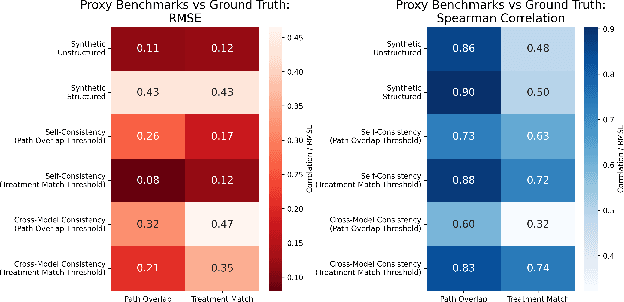

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
Exploring Scaling Laws for EHR Foundation Models
May 29, 2025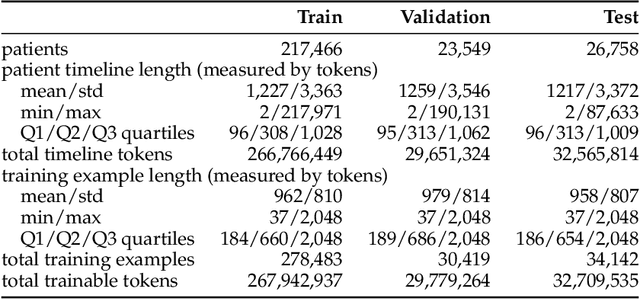
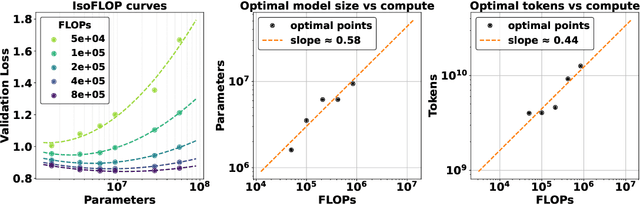
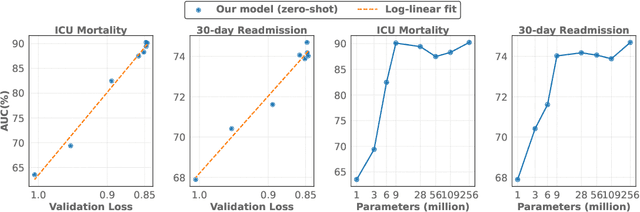
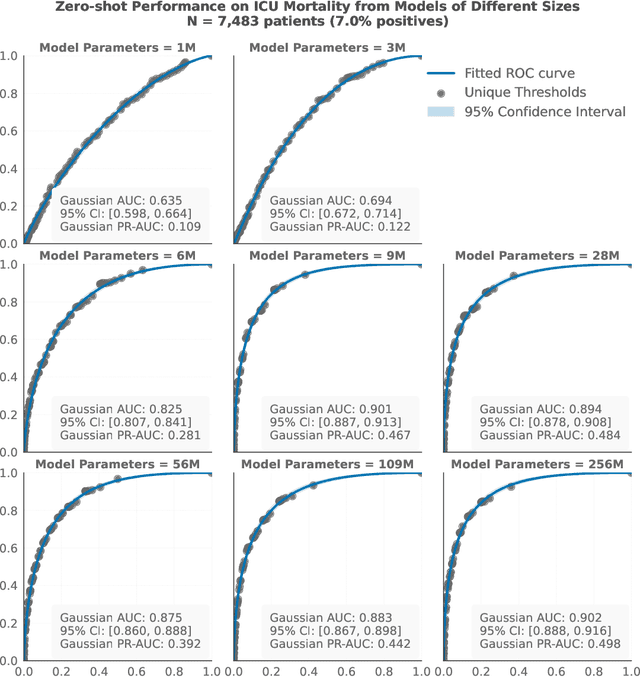
The emergence of scaling laws has profoundly shaped the development of large language models (LLMs), enabling predictable performance gains through systematic increases in model size, dataset volume, and compute. Yet, these principles remain largely unexplored in the context of electronic health records (EHRs) -- a rich, sequential, and globally abundant data source that differs structurally from natural language. In this work, we present the first empirical investigation of scaling laws for EHR foundation models. By training transformer architectures on patient timeline data from the MIMIC-IV database across varying model sizes and compute budgets, we identify consistent scaling patterns, including parabolic IsoFLOPs curves and power-law relationships between compute, model parameters, data size, and clinical utility. These findings demonstrate that EHR models exhibit scaling behavior analogous to LLMs, offering predictive insights into resource-efficient training strategies. Our results lay the groundwork for developing powerful EHR foundation models capable of transforming clinical prediction tasks and advancing personalized healthcare.
Universal Abstraction: Harnessing Frontier Models to Structure Real-World Data at Scale
Feb 02, 2025



The vast majority of real-world patient information resides in unstructured clinical text, and the process of medical abstraction seeks to extract and normalize structured information from this unstructured input. However, traditional medical abstraction methods can require significant manual efforts that can include crafting rules or annotating training labels, limiting scalability. In this paper, we propose UniMedAbstractor (UMA), a zero-shot medical abstraction framework leveraging Large Language Models (LLMs) through a modular and customizable prompt template. We refer to our approach as universal abstraction as it can quickly scale to new attributes through its universal prompt template without curating attribute-specific training labels or rules. We evaluate UMA for oncology applications, focusing on fifteen key attributes representing the cancer patient journey, from short-context attributes (e.g., performance status, treatment) to complex long-context attributes requiring longitudinal reasoning (e.g., tumor site, histology, TNM staging). Experiments on real-world data show UMA's strong performance and generalizability. Compared to supervised and heuristic baselines, UMA with GPT-4o achieves on average an absolute 2-point F1/accuracy improvement for both short-context and long-context attribute abstraction. For pathologic T staging, UMA even outperforms the supervised model by 20 points in accuracy.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024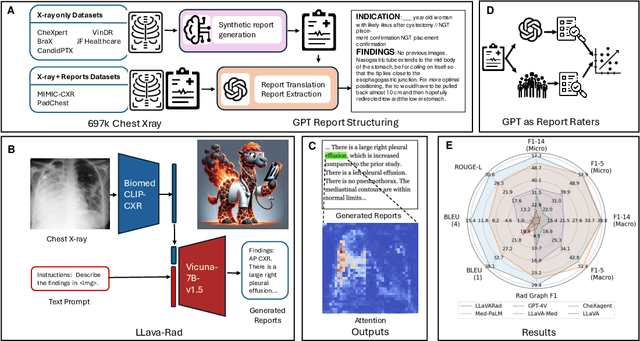
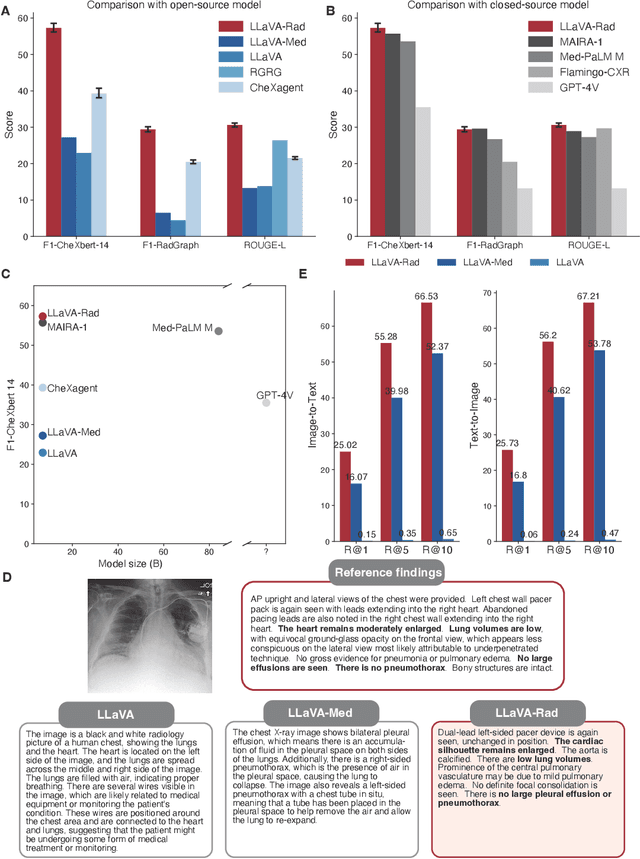
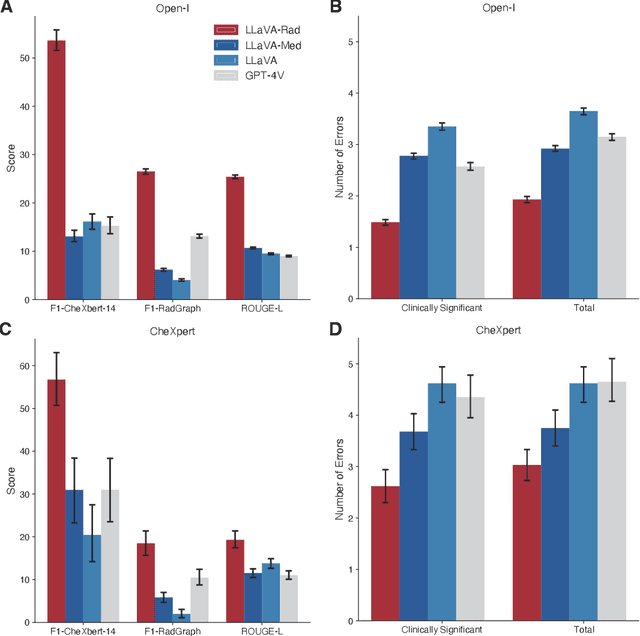
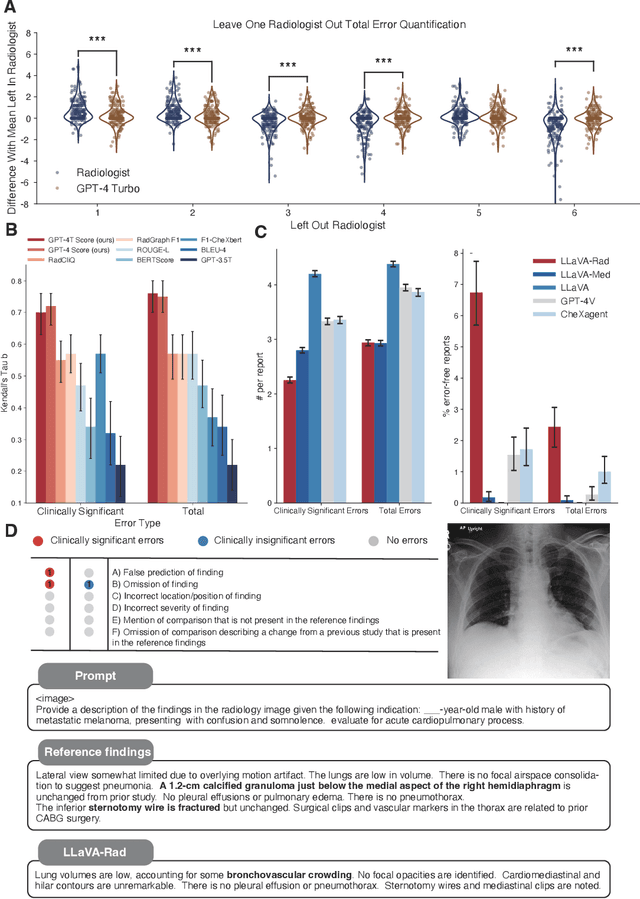
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
Foundation Models for Biomedical Image Segmentation: A Survey
Jan 15, 2024Recent advancements in biomedical image analysis have been significantly driven by the Segment Anything Model (SAM). This transformative technology, originally developed for general-purpose computer vision, has found rapid application in medical image processing. Within the last year, marked by over 100 publications, SAM has demonstrated its prowess in zero-shot learning adaptations for medical imaging. The fundamental premise of SAM lies in its capability to segment or identify objects in images without prior knowledge of the object type or imaging modality. This approach aligns well with tasks achievable by the human visual system, though its application in non-biological vision contexts remains more theoretically challenging. A notable feature of SAM is its ability to adjust segmentation according to a specified resolution scale or area of interest, akin to semantic priming. This adaptability has spurred a wave of creativity and innovation in applying SAM to medical imaging. Our review focuses on the period from April 1, 2023, to September 30, 2023, a critical first six months post-initial publication. We examine the adaptations and integrations of SAM necessary to address longstanding clinical challenges, particularly in the context of 33 open datasets covered in our analysis. While SAM approaches or achieves state-of-the-art performance in numerous applications, it falls short in certain areas, such as segmentation of the carotid artery, adrenal glands, optic nerve, and mandible bone. Our survey delves into the innovative techniques where SAM's foundational approach excels and explores the core concepts in translating and applying these models effectively in diverse medical imaging scenarios.
Enhancing Medical Text Evaluation with GPT-4
Nov 16, 2023In the evaluation of medical text generation, it is essential to scrutinize each piece of information and ensure the utmost accuracy of the evaluation. Existing evaluation metrics either focus on coarse-level evaluation that assigns one score for the whole generated output or rely on evaluation models trained on general domain, resulting in inaccuracies when adapted to the medical domain. To address these issues, we propose a set of factuality-centric evaluation aspects and design corresponding GPT-4-based metrics for medical text generation. We systematically compare these metrics with existing ones on clinical note generation and medical report summarization tasks, revealing low inter-metric correlation. A comprehensive human evaluation confirms that the proposed GPT-4-based metrics exhibit substantially higher agreement with human judgments than existing evaluation metrics. Our study contributes to the understanding of medical text generation evaluation and offers a more reliable alternative to existing metrics.
TRIALSCOPE: A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models
Nov 06, 2023The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
Scaling Clinical Trial Matching Using Large Language Models: A Case Study in Oncology
Aug 18, 2023Clinical trial matching is a key process in health delivery and discovery. In practice, it is plagued by overwhelming unstructured data and unscalable manual processing. In this paper, we conduct a systematic study on scaling clinical trial matching using large language models (LLMs), with oncology as the focus area. Our study is grounded in a clinical trial matching system currently in test deployment at a large U.S. health network. Initial findings are promising: out of box, cutting-edge LLMs, such as GPT-4, can already structure elaborate eligibility criteria of clinical trials and extract complex matching logic (e.g., nested AND/OR/NOT). While still far from perfect, LLMs substantially outperform prior strong baselines and may serve as a preliminary solution to help triage patient-trial candidates with humans in the loop. Our study also reveals a few significant growth areas for applying LLMs to end-to-end clinical trial matching, such as context limitation and accuracy, especially in structuring patient information from longitudinal medical records.
Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events
Jul 12, 2023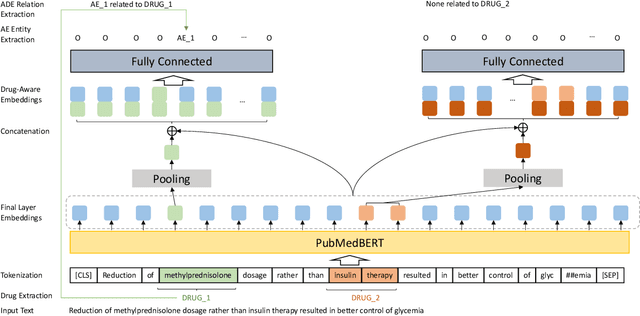
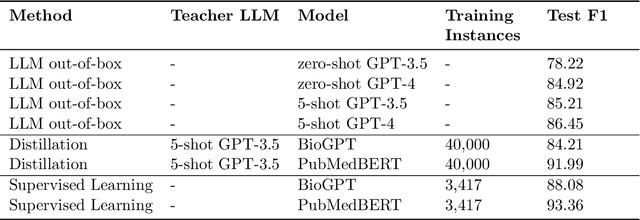
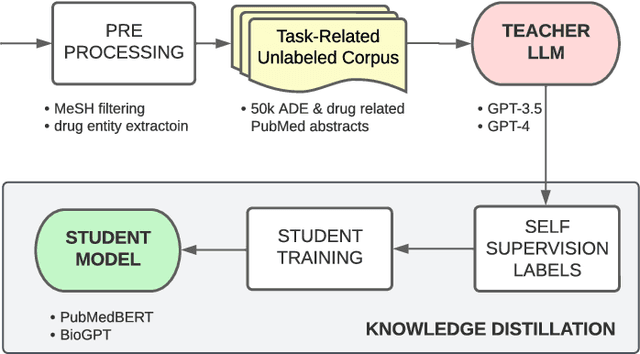
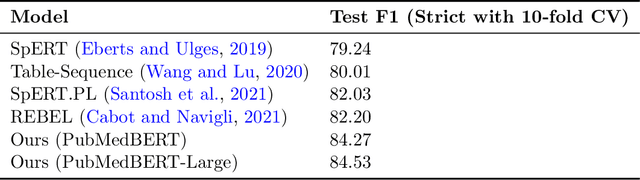
Large language models (LLMs), such as GPT-4, have demonstrated remarkable capabilities across a wide range of tasks, including health applications. In this paper, we study how LLMs can be used to scale biomedical knowledge curation. We find that while LLMs already possess decent competency in structuring biomedical text, by distillation into a task-specific student model through self-supervised learning, substantial gains can be attained over out-of-box LLMs, with additional advantages such as cost, efficiency, and white-box model access. We conduct a case study on adverse drug event (ADE) extraction, which is an important area for improving care. On standard ADE extraction evaluation, a GPT-3.5 distilled PubMedBERT model attained comparable accuracy as supervised state-of-the-art models without using any labeled data. Despite being over 1,000 times smaller, the distilled model outperformed its teacher GPT-3.5 by over 6 absolute points in F1 and GPT-4 by over 5 absolute points. Ablation studies on distillation model choice (e.g., PubMedBERT vs BioGPT) and ADE extraction architecture shed light on best practice for biomedical knowledge extraction. Similar gains were attained by distillation for other standard biomedical knowledge extraction tasks such as gene-disease associations and protected health information, further illustrating the promise of this approach.
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Jun 01, 2023Conversational generative AI has demonstrated remarkable promise for empowering biomedical practitioners, but current investigations focus on unimodal text. Multimodal conversational AI has seen rapid progress by leveraging billions of image-text pairs from the public web, but such general-domain vision-language models still lack sophistication in understanding and conversing about biomedical images. In this paper, we propose a cost-efficient approach for training a vision-language conversational assistant that can answer open-ended research questions of biomedical images. The key idea is to leverage a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central, use GPT-4 to self-instruct open-ended instruction-following data from the captions, and then fine-tune a large general-domain vision-language model using a novel curriculum learning method. Specifically, the model first learns to align biomedical vocabulary using the figure-caption pairs as is, then learns to master open-ended conversational semantics using GPT-4 generated instruction-following data, broadly mimicking how a layperson gradually acquires biomedical knowledge. This enables us to train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med) in less than 15 hours (with eight A100s). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. On three standard biomedical visual question answering datasets, LLaVA-Med outperforms previous supervised state-of-the-art on certain metrics. To facilitate biomedical multimodal research, we will release our instruction-following data and the LLaVA-Med model.