 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling medical imaging report generation with multimodal reinforcement learning
Jan 23, 2026Frontier models have demonstrated remarkable capabilities in understanding and reasoning with natural-language text, but they still exhibit major competency gaps in multimodal understanding and reasoning especially in high-value verticals such as biomedicine. Medical imaging report generation is a prominent example. Supervised fine-tuning can substantially improve performance, but they are prone to overfitting to superficial boilerplate patterns. In this paper, we introduce Universal Report Generation (UniRG) as a general framework for medical imaging report generation. By leveraging reinforcement learning as a unifying mechanism to directly optimize for evaluation metrics designed for end applications, UniRG can significantly improve upon supervised fine-tuning and attain durable generalization across diverse institutions and clinical practices. We trained UniRG-CXR on publicly available chest X-ray (CXR) data and conducted a thorough evaluation in CXR report generation with rigorous evaluation scenarios. On the authoritative ReXrank benchmark, UniRG-CXR sets new overall SOTA, outperforming prior state of the art by a wide margin.
X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains
May 06, 2025Recent proprietary models (e.g., o3) have begun to demonstrate strong multimodal reasoning capabilities. Yet, most existing open-source research concentrates on training text-only reasoning models, with evaluations limited to mainly mathematical and general-domain tasks. Therefore, it remains unclear how to effectively extend reasoning capabilities beyond text input and general domains. This paper explores a fundamental research question: Is reasoning generalizable across modalities and domains? Our findings support an affirmative answer: General-domain text-based post-training can enable such strong generalizable reasoning. Leveraging this finding, we introduce X-Reasoner, a vision-language model post-trained solely on general-domain text for generalizable reasoning, using a two-stage approach: an initial supervised fine-tuning phase with distilled long chain-of-thoughts, followed by reinforcement learning with verifiable rewards. Experiments show that X-Reasoner successfully transfers reasoning capabilities to both multimodal and out-of-domain settings, outperforming existing state-of-the-art models trained with in-domain and multimodal data across various general and medical benchmarks (Figure 1). Additionally, we find that X-Reasoner's performance in specialized domains can be further enhanced through continued training on domain-specific text-only data. Building upon this, we introduce X-Reasoner-Med, a medical-specialized variant that achieves new state of the art on numerous text-only and multimodal medical benchmarks.
TN-Eval: Rubric and Evaluation Protocols for Measuring the Quality of Behavioral Therapy Notes
Mar 26, 2025

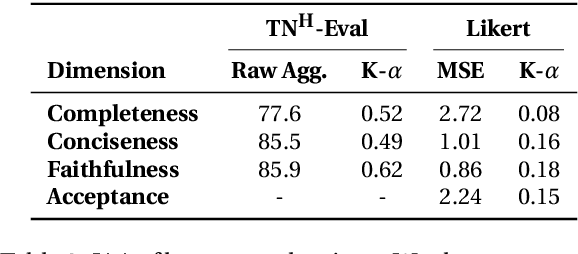

Behavioral therapy notes are important for both legal compliance and patient care. Unlike progress notes in physical health, quality standards for behavioral therapy notes remain underdeveloped. To address this gap, we collaborated with licensed therapists to design a comprehensive rubric for evaluating therapy notes across key dimensions: completeness, conciseness, and faithfulness. Further, we extend a public dataset of behavioral health conversations with therapist-written notes and LLM-generated notes, and apply our evaluation framework to measure their quality. We find that: (1) A rubric-based manual evaluation protocol offers more reliable and interpretable results than traditional Likert-scale annotations. (2) LLMs can mimic human evaluators in assessing completeness and conciseness but struggle with faithfulness. (3) Therapist-written notes often lack completeness and conciseness, while LLM-generated notes contain hallucination. Surprisingly, in a blind test, therapists prefer and judge LLM-generated notes to be superior to therapist-written notes.
Med-RLVR: Emerging Medical Reasoning from a 3B base model via reinforcement Learning
Feb 27, 2025



Reinforcement learning from verifiable rewards (RLVR) has recently gained attention for its ability to elicit self-evolved reasoning capabilitie from base language models without explicit reasoning supervisions, as demonstrated by DeepSeek-R1. While prior work on RLVR has primarily focused on mathematical and coding domains, its applicability to other tasks and domains remains unexplored. In this work, we investigate whether medical reasoning can emerge from RLVR. We introduce Med-RLVR as an initial study of RLVR in the medical domain leveraging medical multiple-choice question answering (MCQA) data as verifiable labels. Our results demonstrate that RLVR is not only effective for math and coding but also extends successfully to medical question answering. Notably, Med-RLVR achieves performance comparable to traditional supervised fine-tuning (SFT) on in-distribution tasks while significantly improving out-of-distribution generalization, with an 8-point accuracy gain. Further analysis of training dynamics reveals that, with no explicit reasoning supervision, reasoning emerges from the 3B-parameter base model. These findings underscore the potential of RLVR in domains beyond math and coding, opening new avenues for its application in knowledge-intensive fields such as medicine.
Universal Abstraction: Harnessing Frontier Models to Structure Real-World Data at Scale
Feb 02, 2025



The vast majority of real-world patient information resides in unstructured clinical text, and the process of medical abstraction seeks to extract and normalize structured information from this unstructured input. However, traditional medical abstraction methods can require significant manual efforts that can include crafting rules or annotating training labels, limiting scalability. In this paper, we propose UniMedAbstractor (UMA), a zero-shot medical abstraction framework leveraging Large Language Models (LLMs) through a modular and customizable prompt template. We refer to our approach as universal abstraction as it can quickly scale to new attributes through its universal prompt template without curating attribute-specific training labels or rules. We evaluate UMA for oncology applications, focusing on fifteen key attributes representing the cancer patient journey, from short-context attributes (e.g., performance status, treatment) to complex long-context attributes requiring longitudinal reasoning (e.g., tumor site, histology, TNM staging). Experiments on real-world data show UMA's strong performance and generalizability. Compared to supervised and heuristic baselines, UMA with GPT-4o achieves on average an absolute 2-point F1/accuracy improvement for both short-context and long-context attribute abstraction. For pathologic T staging, UMA even outperforms the supervised model by 20 points in accuracy.
CriSPO: Multi-Aspect Critique-Suggestion-guided Automatic Prompt Optimization for Text Generation
Oct 03, 2024



Large language models (LLMs) can generate fluent summaries across domains using prompting techniques, reducing the need to train models for summarization applications. However, crafting effective prompts that guide LLMs to generate summaries with the appropriate level of detail and writing style remains a challenge. In this paper, we explore the use of salient information extracted from the source document to enhance summarization prompts. We show that adding keyphrases in prompts can improve ROUGE F1 and recall, making the generated summaries more similar to the reference and more complete. The number of keyphrases can control the precision-recall trade-off. Furthermore, our analysis reveals that incorporating phrase-level salient information is superior to word- or sentence-level. However, the impact on hallucination is not universally positive across LLMs. To conduct this analysis, we introduce Keyphrase Signal Extractor (CriSPO), a lightweight model that can be finetuned to extract salient keyphrases. By using CriSPO, we achieve consistent ROUGE improvements across datasets and open-weight and proprietary LLMs without any LLM customization. Our findings provide insights into leveraging salient information in building prompt-based summarization systems.
Exploring the Boundaries of GPT-4 in Radiology
Oct 23, 2023



The recent success of general-domain large language models (LLMs) has significantly changed the natural language processing paradigm towards a unified foundation model across domains and applications. In this paper, we focus on assessing the performance of GPT-4, the most capable LLM so far, on the text-based applications for radiology reports, comparing against state-of-the-art (SOTA) radiology-specific models. Exploring various prompting strategies, we evaluated GPT-4 on a diverse range of common radiology tasks and we found GPT-4 either outperforms or is on par with current SOTA radiology models. With zero-shot prompting, GPT-4 already obtains substantial gains ($\approx$ 10% absolute improvement) over radiology models in temporal sentence similarity classification (accuracy) and natural language inference ($F_1$). For tasks that require learning dataset-specific style or schema (e.g. findings summarisation), GPT-4 improves with example-based prompting and matches supervised SOTA. Our extensive error analysis with a board-certified radiologist shows GPT-4 has a sufficient level of radiology knowledge with only occasional errors in complex context that require nuanced domain knowledge. For findings summarisation, GPT-4 outputs are found to be overall comparable with existing manually-written impressions.
Compositional Zero-Shot Domain Transfer with Text-to-Text Models
Mar 23, 2023Label scarcity is a bottleneck for improving task performance in specialised domains. We propose a novel compositional transfer learning framework (DoT5 - domain compositional zero-shot T5) for zero-shot domain transfer. Without access to in-domain labels, DoT5 jointly learns domain knowledge (from MLM of unlabelled in-domain free text) and task knowledge (from task training on more readily available general-domain data) in a multi-task manner. To improve the transferability of task training, we design a strategy named NLGU: we simultaneously train NLG for in-domain label-to-data generation which enables data augmentation for self-finetuning and NLU for label prediction. We evaluate DoT5 on the biomedical domain and the resource-lean subdomain of radiology, focusing on NLI, text summarisation and embedding learning. DoT5 demonstrates the effectiveness of compositional transfer learning through multi-task learning. In particular, DoT5 outperforms the current SOTA in zero-shot transfer by over 7 absolute points in accuracy on RadNLI. We validate DoT5 with ablations and a case study demonstrating its ability to solve challenging NLI examples requiring in-domain expertise.
Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing
Jan 11, 2023


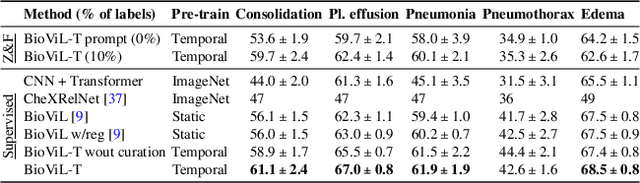
Self-supervised learning in vision-language processing exploits semantic alignment between imaging and text modalities. Prior work in biomedical VLP has mostly relied on the alignment of single image and report pairs even though clinical notes commonly refer to prior images. This does not only introduce poor alignment between the modalities but also a missed opportunity to exploit rich self-supervision through existing temporal content in the data. In this work, we explicitly account for prior images and reports when available during both training and fine-tuning. Our approach, named BioViL-T, uses a CNN-Transformer hybrid multi-image encoder trained jointly with a text model. It is designed to be versatile to arising challenges such as pose variations and missing input images across time. The resulting model excels on downstream tasks both in single- and multi-image setups, achieving state-of-the-art performance on (I) progression classification, (II) phrase grounding, and (III) report generation, whilst offering consistent improvements on disease classification and sentence-similarity tasks. We release a novel multi-modal temporal benchmark dataset, MS-CXR-T, to quantify the quality of vision-language representations in terms of temporal semantics. Our experimental results show the advantages of incorporating prior images and reports to make most use of the data.
Context vs Target Word: Quantifying Biases in Lexical Semantic Datasets
Dec 13, 2021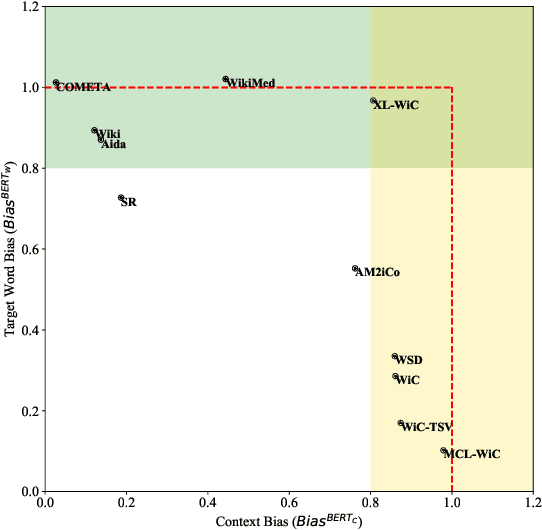


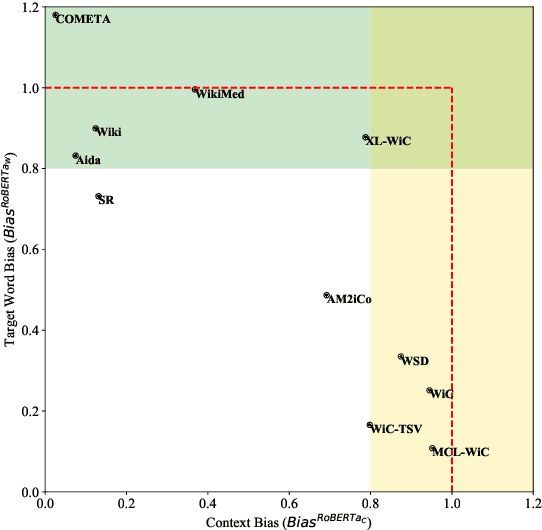
State-of-the-art contextualized models such as BERT use tasks such as WiC and WSD to evaluate their word-in-context representations. This inherently assumes that performance in these tasks reflect how well a model represents the coupled word and context semantics. This study investigates this assumption by presenting the first quantitative analysis (using probing baselines) on the context-word interaction being tested in major contextual lexical semantic tasks. Specifically, based on the probing baseline performance, we propose measures to calculate the degree of context or word biases in a dataset, and plot existing datasets on a continuum. The analysis shows most existing datasets fall into the extreme ends of the continuum (i.e. they are either heavily context-biased or target-word-biased) while only AM$^2$iCo and Sense Retrieval challenge a model to represent both the context and target words. Our case study on WiC reveals that human subjects do not share models' strong context biases in the dataset (humans found semantic judgments much more difficult when the target word is missing) and models are learning spurious correlations from context alone. This study demonstrates that models are usually not being tested for word-in-context representations as such in these tasks and results are therefore open to misinterpretation. We recommend our framework as sanity check for context and target word biases of future task design and application in lexical semantics.