 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Visuals Aren't the Problem: Evaluating Vision-Language Models on Misleading Data Visualizations
Mar 23, 2026Visualizations help communicate data insights, but deceptive data representations can distort their interpretation and propagate misinformation. While recent Vision Language Models (VLMs) perform well on many chart understanding tasks, their ability to detect misleading visualizations, especially when deception arises from subtle reasoning errors in captions, remains poorly understood. Here, we evaluate VLMs on misleading visualization-caption pairs grounded in a fine-grained taxonomy of reasoning errors (e.g., Cherry-picking, Causal inference) and visualization design errors (e.g., Truncated axis, Dual axis, inappropriate encodings). To this end, we develop a benchmark that combines real-world visualization with human-authored, curated misleading captions designed to elicit specific reasoning and visualization error types, enabling controlled analysis across error categories and modalities of misleadingness. Evaluating many commercial and open-source VLMs, we find that models detect visual design errors substantially more reliably than reasoning-based misinformation, and frequently misclassify non-misleading visualizations as deceptive. Overall, our work fills a gap between coarse detection of misleading content and the attribution of the specific reasoning or visualization errors that give rise to it.
The Unlearning Mirage: A Dynamic Framework for Evaluating LLM Unlearning
Mar 11, 2026Unlearning in Large Language Models (LLMs) aims to enhance safety, mitigate biases, and comply with legal mandates, such as the right to be forgotten. However, existing unlearning methods are brittle: minor query modifications, such as multi-hop reasoning and entity aliasing, can recover supposedly forgotten information. As a result, current evaluation metrics often create an illusion of effectiveness, failing to detect these vulnerabilities due to reliance on static, unstructured benchmarks. We propose a dynamic framework that stress tests unlearning robustness using complex structured queries. Our approach first elicits knowledge from the target model (pre-unlearning) and constructs targeted probes, ranging from simple queries to multi-hop chains, allowing precise control over query difficulty. Our experiments show that the framework (1) shows comparable coverage to existing benchmarks by automatically generating semantically equivalent Q&A probes, (2) aligns with prior evaluations, and (3) uncovers new unlearning failures missed by other benchmarks, particularly in multi-hop settings. Furthermore, activation analyses show that single-hop queries typically follow dominant computation pathways, which are more likely to be disrupted by unlearning methods. In contrast, multi-hop queries tend to use alternative pathways that often remain intact, explaining the brittleness of unlearning techniques in multi-hop settings. Our framework enables practical and scalable evaluation of unlearning methods without the need for manual construction of forget test sets, enabling easier adoption for real-world applications. We release the pip package and the code at https://sites.google.com/view/unlearningmirage/home.
BabyLM Turns 4 and Goes Multilingual: Call for Papers for the 2026 BabyLM Workshop
Feb 24, 2026The goal of the BabyLM is to stimulate new research connections between cognitive modeling and language model pretraining. We invite contributions in this vein to the BabyLM Workshop, which will also include the 4th iteration of the BabyLM Challenge. As in previous years, the challenge features two ``standard'' tracks (Strict and Strict-Small), in which participants must train language models on under 100M or 10M words of data, respectively. This year, we move beyond our previous English-only pretraining datasets with a new Multilingual track, focusing on English, Dutch, and Chinese. For the workshop, we call for papers related to the overall theme of BabyLM, which includes training efficiency, small-scale training datasets, cognitive modeling, model evaluation, and architecture innovation.
The World According to LLMs: How Geographic Origin Influences LLMs' Entity Deduction Capabilities
Aug 07, 2025Large Language Models (LLMs) have been extensively tuned to mitigate explicit biases, yet they often exhibit subtle implicit biases rooted in their pre-training data. Rather than directly probing LLMs with human-crafted questions that may trigger guardrails, we propose studying how models behave when they proactively ask questions themselves. The 20 Questions game, a multi-turn deduction task, serves as an ideal testbed for this purpose. We systematically evaluate geographic performance disparities in entity deduction using a new dataset, Geo20Q+, consisting of both notable people and culturally significant objects (e.g., foods, landmarks, animals) from diverse regions. We test popular LLMs across two gameplay configurations (canonical 20-question and unlimited turns) and in seven languages (English, Hindi, Mandarin, Japanese, French, Spanish, and Turkish). Our results reveal geographic disparities: LLMs are substantially more successful at deducing entities from the Global North than the Global South, and the Global West than the Global East. While Wikipedia pageviews and pre-training corpus frequency correlate mildly with performance, they fail to fully explain these disparities. Notably, the language in which the game is played has minimal impact on performance gaps. These findings demonstrate the value of creative, free-form evaluation frameworks for uncovering subtle biases in LLMs that remain hidden in standard prompting setups. By analyzing how models initiate and pursue reasoning goals over multiple turns, we find geographic and cultural disparities embedded in their reasoning processes. We release the dataset (Geo20Q+) and code at https://sites.google.com/view/llmbias20q/home.
A Neural Network Model of Complementary Learning Systems: Pattern Separation and Completion for Continual Learning
Jul 15, 2025Learning new information without forgetting prior knowledge is central to human intelligence. In contrast, neural network models suffer from catastrophic forgetting: a significant degradation in performance on previously learned tasks when acquiring new information. The Complementary Learning Systems (CLS) theory offers an explanation for this human ability, proposing that the brain has distinct systems for pattern separation (encoding distinct memories) and pattern completion (retrieving complete memories from partial cues). To capture these complementary functions, we leverage the representational generalization capabilities of variational autoencoders (VAEs) and the robust memory storage properties of Modern Hopfield networks (MHNs), combining them into a neurally plausible continual learning model. We evaluate this model on the Split-MNIST task, a popular continual learning benchmark, and achieve close to state-of-the-art accuracy (~90%), substantially reducing forgetting. Representational analyses empirically confirm the functional dissociation: the VAE underwrites pattern completion, while the MHN drives pattern separation. By capturing pattern separation and completion in scalable architectures, our work provides a functional template for modeling memory consolidation, generalization, and continual learning in both biological and artificial systems.
TN-Eval: Rubric and Evaluation Protocols for Measuring the Quality of Behavioral Therapy Notes
Mar 26, 2025

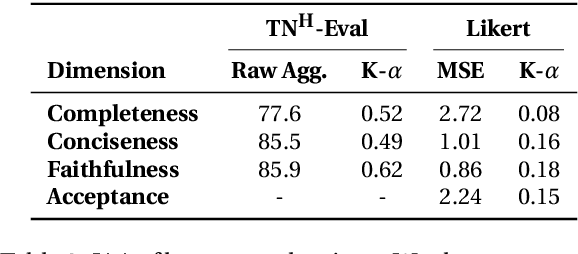

Behavioral therapy notes are important for both legal compliance and patient care. Unlike progress notes in physical health, quality standards for behavioral therapy notes remain underdeveloped. To address this gap, we collaborated with licensed therapists to design a comprehensive rubric for evaluating therapy notes across key dimensions: completeness, conciseness, and faithfulness. Further, we extend a public dataset of behavioral health conversations with therapist-written notes and LLM-generated notes, and apply our evaluation framework to measure their quality. We find that: (1) A rubric-based manual evaluation protocol offers more reliable and interpretable results than traditional Likert-scale annotations. (2) LLMs can mimic human evaluators in assessing completeness and conciseness but struggle with faithfulness. (3) Therapist-written notes often lack completeness and conciseness, while LLM-generated notes contain hallucination. Surprisingly, in a blind test, therapists prefer and judge LLM-generated notes to be superior to therapist-written notes.
Understanding Graphical Perception in Data Visualization through Zero-shot Prompting of Vision-Language Models
Oct 31, 2024Vision Language Models (VLMs) have been successful at many chart comprehension tasks that require attending to both the images of charts and their accompanying textual descriptions. However, it is not well established how VLM performance profiles map to human-like behaviors. If VLMs can be shown to have human-like chart comprehension abilities, they can then be applied to a broader range of tasks, such as designing and evaluating visualizations for human readers. This paper lays the foundations for such applications by evaluating the accuracy of zero-shot prompting of VLMs on graphical perception tasks with established human performance profiles. Our findings reveal that VLMs perform similarly to humans under specific task and style combinations, suggesting that they have the potential to be used for modeling human performance. Additionally, variations to the input stimuli show that VLM accuracy is sensitive to stylistic changes such as fill color and chart contiguity, even when the underlying data and data mappings are the same.
Development of Cognitive Intelligence in Pre-trained Language Models
Jul 01, 2024Recent studies show evidence for emergent cognitive abilities in Large Pre-trained Language Models (PLMs). The increasing cognitive alignment of these models has made them candidates for cognitive science theories. Prior research into the emergent cognitive abilities of PLMs has largely been path-independent to model training, i.e., has focused on the final model weights and not the intermediate steps. However, building plausible models of human cognition using PLMs would benefit from considering the developmental alignment of their performance during training to the trajectories of children's thinking. Guided by psychometric tests of human intelligence, we choose four sets of tasks to investigate the alignment of ten popular families of PLMs and evaluate their available intermediate and final training steps. These tasks are Numerical ability, Linguistic abilities, Conceptual understanding, and Fluid reasoning. We find a striking regularity: regardless of model size, the developmental trajectories of PLMs consistently exhibit a window of maximal alignment to human cognitive development. Before that window, training appears to endow "blank slate" models with the requisite structure to be poised to rapidly learn from experience. After that window, training appears to serve the engineering goal of reducing loss but not the scientific goal of increasing alignment with human cognition.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024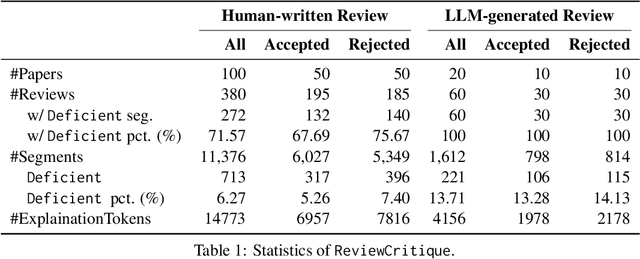
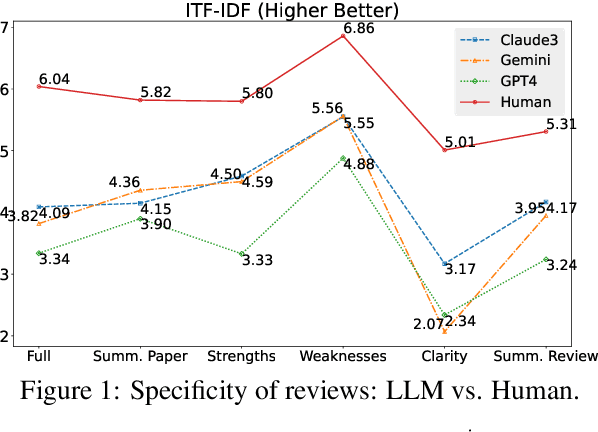

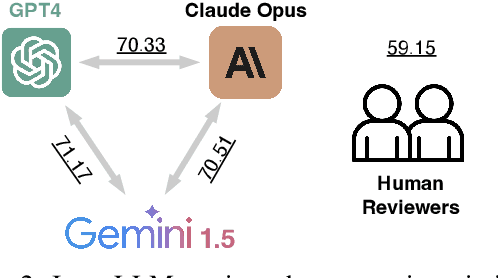
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
From Intentions to Techniques: A Comprehensive Taxonomy and Challenges in Text Watermarking for Large Language Models
Jun 17, 2024With the rapid growth of Large Language Models (LLMs), safeguarding textual content against unauthorized use is crucial. Text watermarking offers a vital solution, protecting both - LLM-generated and plain text sources. This paper presents a unified overview of different perspectives behind designing watermarking techniques, through a comprehensive survey of the research literature. Our work has two key advantages, (1) we analyze research based on the specific intentions behind different watermarking techniques, evaluation datasets used, watermarking addition, and removal methods to construct a cohesive taxonomy. (2) We highlight the gaps and open challenges in text watermarking to promote research in protecting text authorship. This extensive coverage and detailed analysis sets our work apart, offering valuable insights into the evolving landscape of text watermarking in language models.