 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
IRONIC: Coherence-Aware Reasoning Chains for Multi-Modal Sarcasm Detection
May 22, 2025Interpreting figurative language such as sarcasm across multi-modal inputs presents unique challenges, often requiring task-specific fine-tuning and extensive reasoning steps. However, current Chain-of-Thought approaches do not efficiently leverage the same cognitive processes that enable humans to identify sarcasm. We present IRONIC, an in-context learning framework that leverages Multi-modal Coherence Relations to analyze referential, analogical and pragmatic image-text linkages. Our experiments show that IRONIC achieves state-of-the-art performance on zero-shot Multi-modal Sarcasm Detection across different baselines. This demonstrates the need for incorporating linguistic and cognitive insights into the design of multi-modal reasoning strategies. Our code is available at: https://github.com/aashish2000/IRONIC
Beyond speculation: Measuring the growing presence of LLM-generated texts in multilingual disinformation
Mar 29, 2025Increased sophistication of large language models (LLMs) and the consequent quality of generated multilingual text raises concerns about potential disinformation misuse. While humans struggle to distinguish LLM-generated content from human-written texts, the scholarly debate about their impact remains divided. Some argue that heightened fears are overblown due to natural ecosystem limitations, while others contend that specific "longtail" contexts face overlooked risks. Our study bridges this debate by providing the first empirical evidence of LLM presence in the latest real-world disinformation datasets, documenting the increase of machine-generated content following ChatGPT's release, and revealing crucial patterns across languages, platforms, and time periods.
RONA: Pragmatically Diverse Image Captioning with Coherence Relations
Mar 14, 2025Writing Assistants (e.g., Grammarly, Microsoft Copilot) traditionally generate diverse image captions by employing syntactic and semantic variations to describe image components. However, human-written captions prioritize conveying a central message alongside visual descriptions using pragmatic cues. To enhance pragmatic diversity, it is essential to explore alternative ways of communicating these messages in conjunction with visual content. To address this challenge, we propose RONA, a novel prompting strategy for Multi-modal Large Language Models (MLLM) that leverages Coherence Relations as an axis for variation. We demonstrate that RONA generates captions with better overall diversity and ground-truth alignment, compared to MLLM baselines across multiple domains. Our code is available at: https://github.com/aashish2000/RONA
From Intentions to Techniques: A Comprehensive Taxonomy and Challenges in Text Watermarking for Large Language Models
Jun 17, 2024With the rapid growth of Large Language Models (LLMs), safeguarding textual content against unauthorized use is crucial. Text watermarking offers a vital solution, protecting both - LLM-generated and plain text sources. This paper presents a unified overview of different perspectives behind designing watermarking techniques, through a comprehensive survey of the research literature. Our work has two key advantages, (1) we analyze research based on the specific intentions behind different watermarking techniques, evaluation datasets used, watermarking addition, and removal methods to construct a cohesive taxonomy. (2) We highlight the gaps and open challenges in text watermarking to promote research in protecting text authorship. This extensive coverage and detailed analysis sets our work apart, offering valuable insights into the evolving landscape of text watermarking in language models.
ANCHOR: LLM-driven News Subject Conditioning for Text-to-Image Synthesis
Apr 15, 2024



Text-to-Image (T2I) Synthesis has made tremendous strides in enhancing synthesized image quality, but current datasets evaluate model performance only on descriptive, instruction-based prompts. Real-world news image captions take a more pragmatic approach, providing high-level situational and Named-Entity (NE) information and limited physical object descriptions, making them abstractive. To evaluate the ability of T2I models to capture intended subjects from news captions, we introduce the Abstractive News Captions with High-level cOntext Representation (ANCHOR) dataset, containing 70K+ samples sourced from 5 different news media organizations. With Large Language Models (LLM) achieving success in language and commonsense reasoning tasks, we explore the ability of different LLMs to identify and understand key subjects from abstractive captions. Our proposed method Subject-Aware Finetuning (SAFE), selects and enhances the representation of key subjects in synthesized images by leveraging LLM-generated subject weights. It also adapts to the domain distribution of news images and captions through custom Domain Fine-tuning, outperforming current T2I baselines on ANCHOR. By launching the ANCHOR dataset, we hope to motivate research in furthering the Natural Language Understanding (NLU) capabilities of T2I models.
ANNA: Abstractive Text-to-Image Synthesis with Filtered News Captions
Jan 05, 2023
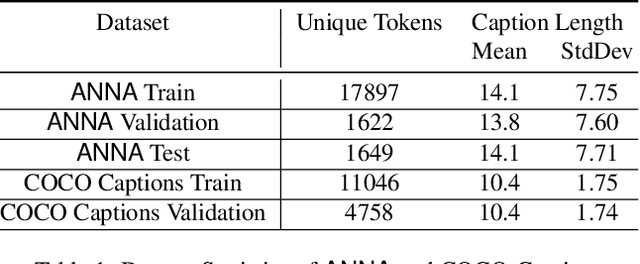
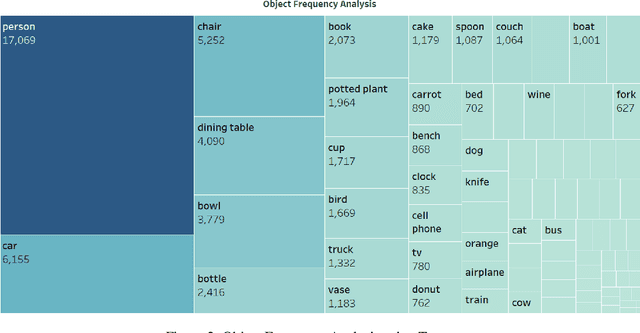

Advancements in Text-to-Image synthesis over recent years have focused more on improving the quality of generated samples on datasets with descriptive captions. However, real-world image-caption pairs present in domains such as news data do not use simple and directly descriptive captions. With captions containing information on both the image content and underlying contextual cues, they become abstractive in nature. In this paper, we launch ANNA, an Abstractive News captioNs dAtaset extracted from online news articles in a variety of different contexts. We explore the capabilities of current Text-to-Image synthesis models to generate news domain-specific images using abstractive captions by benchmarking them on ANNA, in both standard training and transfer learning settings. The generated images are judged on the basis of contextual relevance, visual quality, and perceptual similarity to ground-truth image-caption pairs. Through our experiments, we show that techniques such as transfer learning achieve limited success in understanding abstractive captions but still fail to consistently learn the relationships between content and context features.