 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Audit of Personalisation Drift in Polarising Topics on TikTok
Mar 21, 2026Social media platforms have become an integral part of everyday life, serving as a primary source of news and information for many users. These platforms increasingly rely on personalised recommendation systems that shape what users see and engage with. While these systems are optimised for engagement, concerns have emerged that they may also drive users toward more polarised perspectives, particularly in contested domains such as politics, climate change, vaccines, and conspiracy theories. In this paper, we present an algorithmic audit of personalisation drift on TikTok in these polarising topics. Using controlled accounts designed to simulate users with interests aligned with or opposed to different polarising topics, we systematically measure the extent to which TikTok steers content exposure toward specific topics and polarities over time. Specifically, we investigated: 1) a preference-aligned drift (showing a strong personalisation towards user interests), 2) a polarisation-topic drift (showing a strong neutralising effect for misinformation-themed topics, and a high preference and reinforcement of interest of US politic topic); and 3) a polarisation-stance drift (showing a preference of oppose stance towards US politics topic and a general reinforcement of users' stance by recommending items aligned with their stance towards polarising topics). Overall, our findings provide evidence that recommendation trajectories differ markedly across topics, with some pathways amplifying polarised viewpoints more strongly than others and offer insights for platform governance, transparency and user awareness.
BLUFF: Benchmarking the Detection of False and Synthetic Content across 58 Low-Resource Languages
Feb 28, 2026Multilingual falsehoods threaten information integrity worldwide, yet detection benchmarks remain confined to English or a few high-resource languages, leaving low-resource linguistic communities without robust defense tools. We introduce BLUFF, a comprehensive benchmark for detecting false and synthetic content, spanning 79 languages with over 202K samples, combining human-written fact-checked content (122K+ samples across 57 languages) and LLM-generated content (79K+ samples across 71 languages). BLUFF uniquely covers both high-resource "big-head" (20) and low-resource "long-tail" (59) languages, addressing critical gaps in multilingual research on detecting false and synthetic content. Our dataset features four content types (human-written, LLM-generated, LLM-translated, and hybrid human-LLM text), bidirectional translation (English$\leftrightarrow$X), 39 textual modification techniques (36 manipulation tactics for fake news, 3 AI-editing strategies for real news), and varying edit intensities generated using 19 diverse LLMs. We present AXL-CoI (Adversarial Cross-Lingual Agentic Chainof-Interactions), a novel multi-agentic framework for controlled fake/real news generation, paired with mPURIFY, a quality filtering pipeline ensuring dataset integrity. Experiments reveal state-of-theart detectors suffer up to 25.3% F1 degradation on low-resource versus high-resource languages. BLUFF provides the research community with a multilingual benchmark, extensive linguistic-oriented benchmark evaluation, comprehensive documentation, and opensource tools to advance equitable falsehood detection. Dataset and code are available at: https://jsl5710.github.io/BLUFF/
MultiCW: A Large-Scale Balanced Benchmark Dataset for Training Robust Check-Worthiness Detection Models
Feb 18, 2026Large Language Models (LLMs) are beginning to reshape how media professionals verify information, yet automated support for detecting check-worthy claims a key step in the fact-checking process remains limited. We introduce the Multi-Check-Worthy (MultiCW) dataset, a balanced multilingual benchmark for check-worthy claim detection spanning 16 languages, 7 topical domains, and 2 writing styles. It consists of 123,722 samples, evenly distributed between noisy (informal) and structured (formal) texts, with balanced representation of check-worthy and non-check-worthy classes across all languages. To probe robustness, we also introduce an equally balanced out-of-distribution evaluation set of 27,761 samples in 4 additional languages. To provide baselines, we benchmark 3 common fine-tuned multilingual transformers against a diverse set of 15 commercial and open LLMs under zero-shot settings. Our findings show that fine-tuned models consistently outperform zero-shot LLMs on claim classification and show strong out-of-distribution generalization across languages, domains, and styles. MultiCW provides a rigorous multilingual resource for advancing automated fact-checking and enables systematic comparisons between fine-tuned models and cutting-edge LLMs on the check-worthy claim detection task.
Beyond the Checkbox: Strengthening DSA Compliance Through Social Media Algorithmic Auditing
Jan 26, 2026Algorithms of online platforms are required under the Digital Services Act (DSA) to comply with specific obligations concerning algorithmic transparency, user protection and privacy. To verify compliance with these requirements, DSA mandates platforms to undergo independent audits. Little is known about current auditing practices and their effectiveness in ensuring such compliance. To this end, we bridge regulatory and technical perspectives by critically examining selected audit reports across three critical algorithmic-related provisions: restrictions on profiling minors, transparency in recommender systems, and limitations on targeted advertising using sensitive data. Our analysis shows significant inconsistencies in methodologies and lack of technical depth when evaluating AI-powered systems. To enhance the depth, scale, and independence of compliance assessments, we propose to employ algorithmic auditing -- a process of behavioural assessment of AI algorithms by means of simulating user behaviour, observing algorithm responses and analysing them for audited phenomena.
Better as Generators Than Classifiers: Leveraging LLMs and Synthetic Data for Low-Resource Multilingual Classification
Jan 22, 2026Large Language Models (LLMs) have demonstrated remarkable multilingual capabilities, making them promising tools in both high- and low-resource languages. One particularly valuable use case is generating synthetic samples that can be used to train smaller models in low-resource scenarios where human-labelled data is scarce. In this work, we investigate whether these synthetic data generation capabilities can serve as a form of distillation, producing smaller models that perform on par with or even better than massive LLMs across languages and tasks. To this end, we use a state-of-the-art multilingual LLM to generate synthetic datasets covering 11 languages and 4 classification tasks. These datasets are then used to train smaller models via fine-tuning or instruction tuning, or as synthetic in-context examples for compact LLMs. Our experiments show that even small amounts of synthetic data enable smaller models to outperform the large generator itself, particularly in low-resource languages. Overall, the results suggest that LLMs are best utilised as generators (teachers) rather than classifiers, producing data that empowers smaller and more efficient multilingual models.
SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
May 15, 2025The rapid spread of online disinformation presents a global challenge, and machine learning has been widely explored as a potential solution. However, multilingual settings and low-resource languages are often neglected in this field. To address this gap, we conducted a shared task on multilingual claim retrieval at SemEval 2025, aimed at identifying fact-checked claims that match newly encountered claims expressed in social media posts across different languages. The task includes two subtracks: (1) a monolingual track, where social posts and claims are in the same language, and (2) a crosslingual track, where social posts and claims might be in different languages. A total of 179 participants registered for the task contributing to 52 test submissions. 23 out of 31 teams have submitted their system papers. In this paper, we report the best-performing systems as well as the most common and the most effective approaches across both subtracks. This shared task, along with its dataset and participating systems, provides valuable insights into multilingual claim retrieval and automated fact-checking, supporting future research in this field.
Revisiting Algorithmic Audits of TikTok: Poor Reproducibility and Short-term Validity of Findings
Apr 25, 2025Social media platforms are constantly shifting towards algorithmically curated content based on implicit or explicit user feedback. Regulators, as well as researchers, are calling for systematic social media algorithmic audits as this shift leads to enclosing users in filter bubbles and leading them to more problematic content. An important aspect of such audits is the reproducibility and generalisability of their findings, as it allows to draw verifiable conclusions and audit potential changes in algorithms over time. In this work, we study the reproducibility of the existing sockpuppeting audits of TikTok recommender systems, and the generalizability of their findings. In our efforts to reproduce the previous works, we find multiple challenges stemming from social media platform changes and content evolution, but also the research works themselves. These drawbacks limit the audit reproducibility and require an extensive effort altogether with inevitable adjustments to the auditing methodology. Our experiments also reveal that these one-shot audit findings often hold only in the short term, implying that the reproducibility and generalizability of the audits heavily depend on the methodological choices and the state of algorithms and content on the platform. This highlights the importance of reproducible audits that allow us to determine how the situation changes in time.
Beyond speculation: Measuring the growing presence of LLM-generated texts in multilingual disinformation
Mar 29, 2025Increased sophistication of large language models (LLMs) and the consequent quality of generated multilingual text raises concerns about potential disinformation misuse. While humans struggle to distinguish LLM-generated content from human-written texts, the scholarly debate about their impact remains divided. Some argue that heightened fears are overblown due to natural ecosystem limitations, while others contend that specific "longtail" contexts face overlooked risks. Our study bridges this debate by providing the first empirical evidence of LLM presence in the latest real-world disinformation datasets, documenting the increase of machine-generated content following ChatGPT's release, and revealing crucial patterns across languages, platforms, and time periods.
Increasing the Robustness of the Fine-tuned Multilingual Machine-Generated Text Detectors
Mar 19, 2025
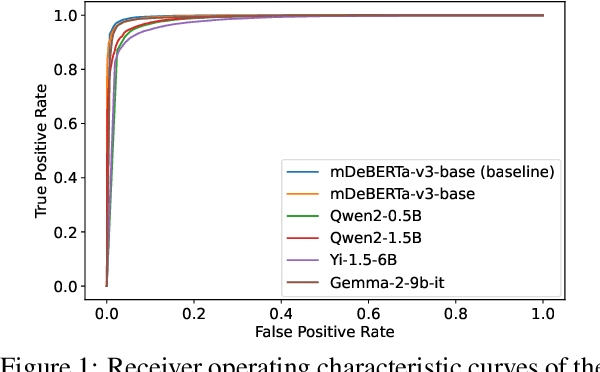


Since the proliferation of LLMs, there have been concerns about their misuse for harmful content creation and spreading. Recent studies justify such fears, providing evidence of LLM vulnerabilities and high potential of their misuse. Humans are no longer able to distinguish between high-quality machine-generated and authentic human-written texts. Therefore, it is crucial to develop automated means to accurately detect machine-generated content. It would enable to identify such content in online information space, thus providing an additional information about its credibility. This work addresses the problem by proposing a robust fine-tuning process of LLMs for the detection task, making the detectors more robust against obfuscation and more generalizable to out-of-distribution data.
Evaluation of LLM Vulnerabilities to Being Misused for Personalized Disinformation Generation
Dec 18, 2024



The capabilities of recent large language models (LLMs) to generate high-quality content indistinguishable by humans from human-written texts rises many concerns regarding their misuse. Previous research has shown that LLMs can be effectively misused for generating disinformation news articles following predefined narratives. Their capabilities to generate personalized (in various aspects) content have also been evaluated and mostly found usable. However, a combination of personalization and disinformation abilities of LLMs has not been comprehensively studied yet. Such a dangerous combination should trigger integrated safety filters of the LLMs, if there are some. This study fills this gap by evaluation of vulnerabilities of recent open and closed LLMs, and their willingness to generate personalized disinformation news articles in English. We further explore whether the LLMs can reliably meta-evaluate the personalization quality and whether the personalization affects the generated-texts detectability. Our results demonstrate the need for stronger safety-filters and disclaimers, as those are not properly functioning in most of the evaluated LLMs. Additionally, our study revealed that the personalization actually reduces the safety-filter activations; thus effectively functioning as a jailbreak. Such behavior must be urgently addressed by LLM developers and service providers.