 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOT: Bridging Natural Language and Geospatial Search for Investigative Journalists
Jun 16, 2025OpenStreetMap (OSM) is a vital resource for investigative journalists doing geolocation verification. However, existing tools to query OSM data such as Overpass Turbo require familiarity with complex query languages, creating barriers for non-technical users. We present SPOT, an open source natural language interface that makes OSM's rich, tag-based geographic data more accessible through intuitive scene descriptions. SPOT interprets user inputs as structured representations of geospatial object configurations using fine-tuned Large Language Models (LLMs), with results being displayed in an interactive map interface. While more general geospatial search tasks are conceivable, SPOT is specifically designed for use in investigative journalism, addressing real-world challenges such as hallucinations in model output, inconsistencies in OSM tagging, and the noisy nature of user input. It combines a novel synthetic data pipeline with a semantic bundling system to enable robust, accurate query generation. To our knowledge, SPOT is the first system to achieve reliable natural language access to OSM data at this level of accuracy. By lowering the technical barrier to geolocation verification, SPOT contributes a practical tool to the broader efforts to support fact-checking and combat disinformation.
Do LLMs Provide Consistent Answers to Health-Related Questions across Languages?
Jan 24, 2025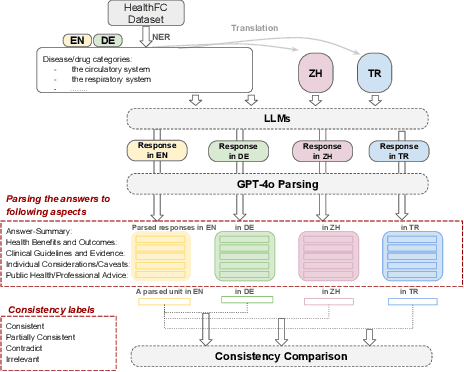
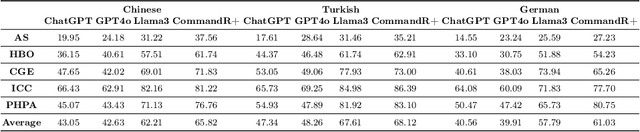

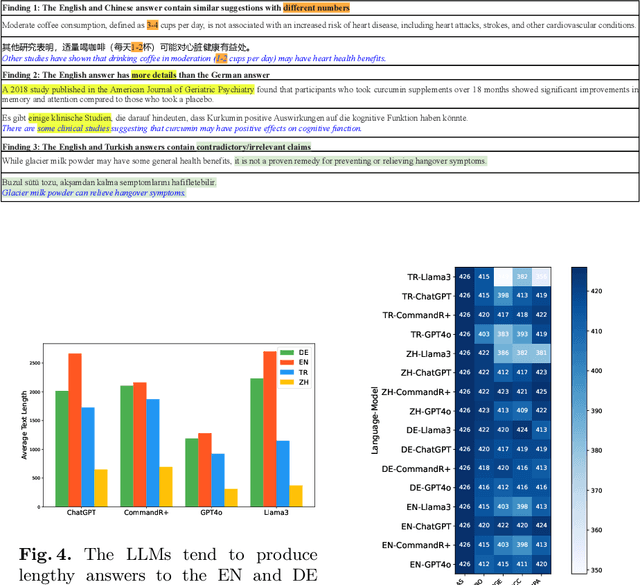
Equitable access to reliable health information is vital for public health, but the quality of online health resources varies by language, raising concerns about inconsistencies in Large Language Models (LLMs) for healthcare. In this study, we examine the consistency of responses provided by LLMs to health-related questions across English, German, Turkish, and Chinese. We largely expand the HealthFC dataset by categorizing health-related questions by disease type and broadening its multilingual scope with Turkish and Chinese translations. We reveal significant inconsistencies in responses that could spread healthcare misinformation. Our main contributions are 1) a multilingual health-related inquiry dataset with meta-information on disease categories, and 2) a novel prompt-based evaluation workflow that enables sub-dimensional comparisons between two languages through parsing. Our findings highlight key challenges in deploying LLM-based tools in multilingual contexts and emphasize the need for improved cross-lingual alignment to ensure accurate and equitable healthcare information.
A Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024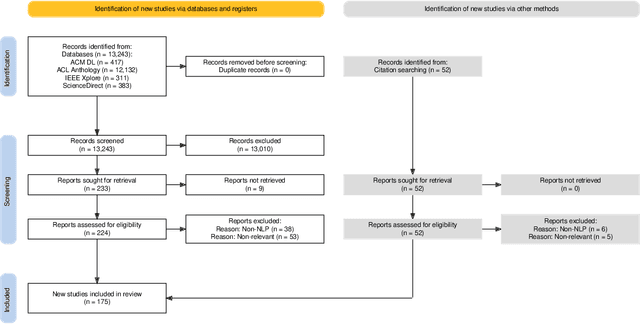
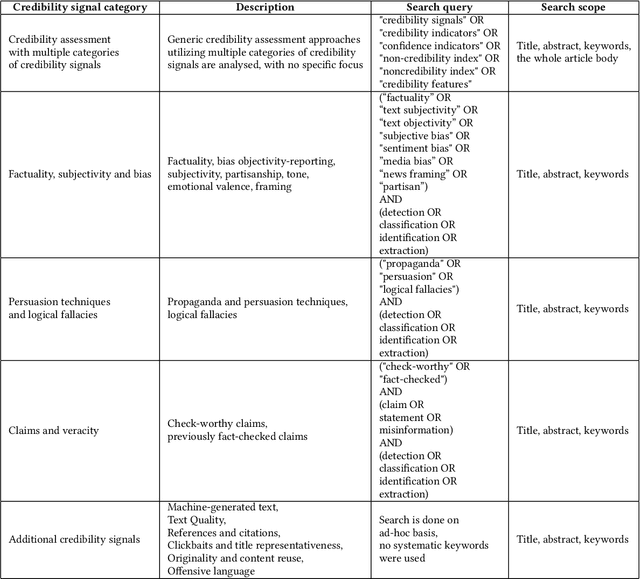
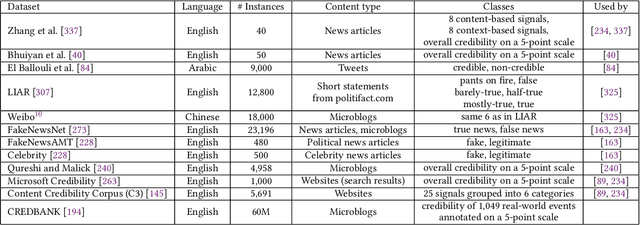
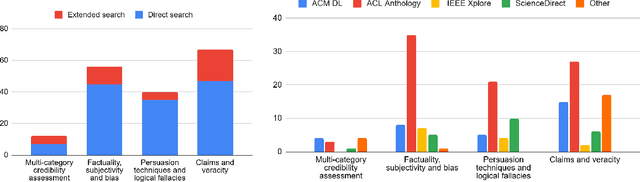
In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.
Pitfalls of Conversational LLMs on News Debiasing
Apr 09, 2024



This paper addresses debiasing in news editing and evaluates the effectiveness of conversational Large Language Models in this task. We designed an evaluation checklist tailored to news editors' perspectives, obtained generated texts from three popular conversational models using a subset of a publicly available dataset in media bias, and evaluated the texts according to the designed checklist. Furthermore, we examined the models as evaluator for checking the quality of debiased model outputs. Our findings indicate that none of the LLMs are perfect in debiasing. Notably, some models, including ChatGPT, introduced unnecessary changes that may impact the author's style and create misinformation. Lastly, we show that the models do not perform as proficiently as domain experts in evaluating the quality of debiased outputs.
Spot: A Natural Language Interface for Geospatial Searches in OSM
Nov 14, 2023
Investigative journalists and fact-checkers have found OpenStreetMap (OSM) to be an invaluable resource for their work due to its extensive coverage and intricate details of various locations, which play a crucial role in investigating news scenes. Despite its value, OSM's complexity presents considerable accessibility and usability challenges, especially for those without a technical background. To address this, we introduce 'Spot', a user-friendly natural language interface for querying OSM data. Spot utilizes a semantic mapping from natural language to OSM tags, leveraging artificially generated sentence queries and a T5 transformer. This approach enables Spot to extract relevant information from user-input sentences and display candidate locations matching the descriptions on a map. To foster collaboration and future advancement, all code and generated data is available as an open-source repository.
DWReCO at CheckThat! 2023: Enhancing Subjectivity Detection through Style-based Data Sampling
Jul 07, 2023



This paper describes our submission for the subjectivity detection task at the CheckThat! Lab. To tackle class imbalances in the task, we have generated additional training materials with GPT-3 models using prompts of different styles from a subjectivity checklist based on journalistic perspective. We used the extended training set to fine-tune language-specific transformer models. Our experiments in English, German and Turkish demonstrate that different subjective styles are effective across all languages. In addition, we observe that the style-based oversampling is better than paraphrasing in Turkish and English. Lastly, the GPT-3 models sometimes produce lacklustre results when generating style-based texts in non-English languages.
Multilingual Detection of Check-Worthy Claims using World Languages and Adapter Fusion
Jan 13, 2023



Check-worthiness detection is the task of identifying claims, worthy to be investigated by fact-checkers. Resource scarcity for non-world languages and model learning costs remain major challenges for the creation of models supporting multilingual check-worthiness detection. This paper proposes cross-training adapters on a subset of world languages, combined by adapter fusion, to detect claims emerging globally in multiple languages. (1) With a vast number of annotators available for world languages and the storage-efficient adapter models, this approach is more cost efficient. Models can be updated more frequently and thus stay up-to-date. (2) Adapter fusion provides insights and allows for interpretation regarding the influence of each adapter model on a particular language. The proposed solution often outperformed the top multilingual approaches in our benchmark tasks.
UPV at TREC Health Misinformation Track 2021 Ranking with SBERT and Quality Estimators
Dec 11, 2021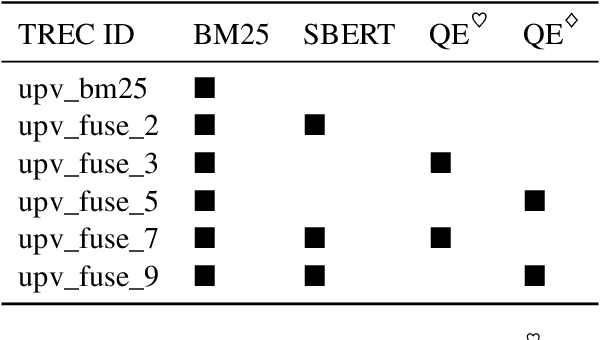



Health misinformation on search engines is a significant problem that could negatively affect individuals or public health. To mitigate the problem, TREC organizes a health misinformation track. This paper presents our submissions to this track. We use a BM25 and a domain-specific semantic search engine for retrieving initial documents. Later, we examine a health news schema for quality assessment and apply it to re-rank documents. We merge the scores from the different components by using reciprocal rank fusion. Finally, we discuss the results and conclude with future works.
Sexism Prediction in Spanish and English Tweets Using Monolingual and Multilingual BERT and Ensemble Models
Nov 08, 2021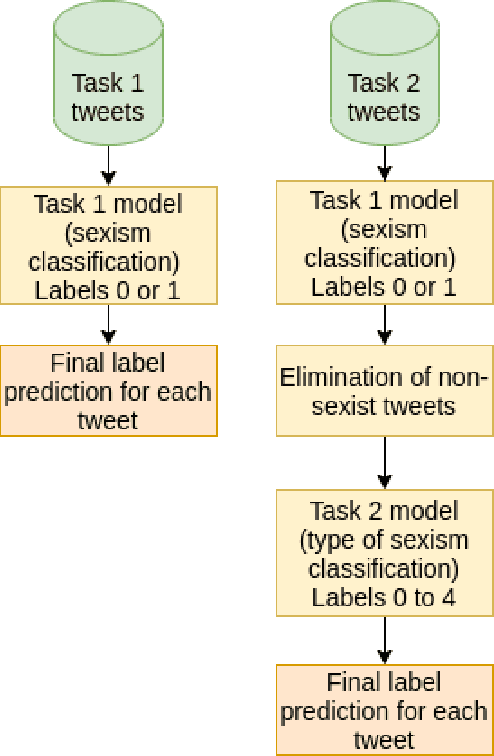
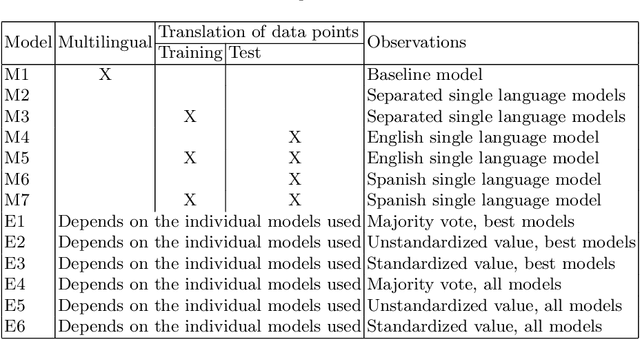
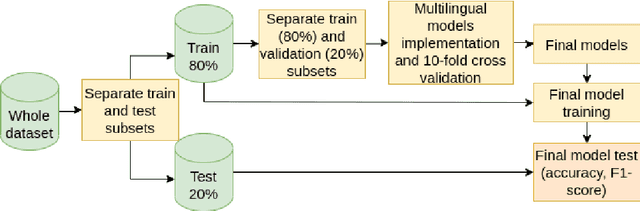

The popularity of social media has created problems such as hate speech and sexism. The identification and classification of sexism in social media are very relevant tasks, as they would allow building a healthier social environment. Nevertheless, these tasks are considerably challenging. This work proposes a system to use multilingual and monolingual BERT and data points translation and ensemble strategies for sexism identification and classification in English and Spanish. It was conducted in the context of the sEXism Identification in Social neTworks shared 2021 (EXIST 2021) task, proposed by the Iberian Languages Evaluation Forum (IberLEF). The proposed system and its main components are described, and an in-depth hyperparameters analysis is conducted. The main results observed were: (i) the system obtained better results than the baseline model (multilingual BERT); (ii) ensemble models obtained better results than monolingual models; and (iii) an ensemble model considering all individual models and the best standardized values obtained the best accuracies and F1-scores for both tasks. This work obtained first place in both tasks at EXIST, with the highest accuracies (0.780 for task 1 and 0.658 for task 2) and F1-scores (F1-binary of 0.780 for task 1 and F1-macro of 0.579 for task 2).
AI-UPV at IberLEF-2021 DETOXIS task: Toxicity Detection in Immigration-Related Web News Comments Using Transformers and Statistical Models
Nov 08, 2021
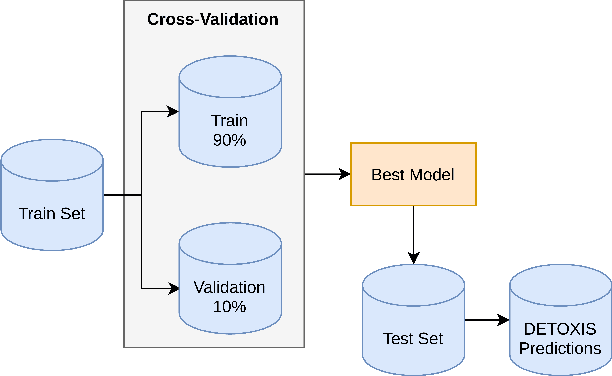
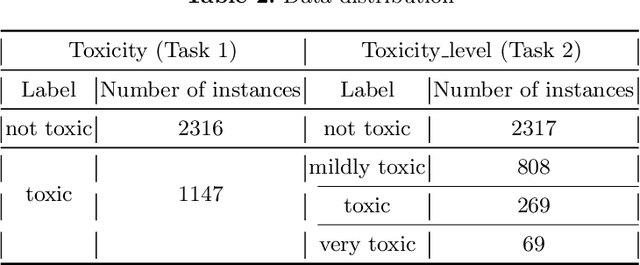

This paper describes our participation in the DEtection of TOXicity in comments In Spanish (DETOXIS) shared task 2021 at the 3rd Workshop on Iberian Languages Evaluation Forum. The shared task is divided into two related classification tasks: (i) Task 1: toxicity detection and; (ii) Task 2: toxicity level detection. They focus on the xenophobic problem exacerbated by the spread of toxic comments posted in different online news articles related to immigration. One of the necessary efforts towards mitigating this problem is to detect toxicity in the comments. Our main objective was to implement an accurate model to detect xenophobia in comments about web news articles within the DETOXIS shared task 2021, based on the competition's official metrics: the F1-score for Task 1 and the Closeness Evaluation Metric (CEM) for Task 2. To solve the tasks, we worked with two types of machine learning models: (i) statistical models and (ii) Deep Bidirectional Transformers for Language Understanding (BERT) models. We obtained our best results in both tasks using BETO, an BERT model trained on a big Spanish corpus. We obtained the 3rd place in Task 1 official ranking with the F1-score of 0.5996, and we achieved the 6th place in Task 2 official ranking with the CEM of 0.7142. Our results suggest: (i) BERT models obtain better results than statistical models for toxicity detection in text comments; (ii) Monolingual BERT models have an advantage over multilingual BERT models in toxicity detection in text comments in their pre-trained language.