 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Decision Making via Conformal VLM-generated Guidance
Apr 16, 2026Building on recent advances in AI, hybrid decision making (HDM) holds the promise of improving human decision quality and reducing cognitive load. We work in the context of learning to guide (LtG), a recently proposed HDM framework in which the human is always responsible for the final decision: rather than suggesting decisions, in LtG the AI supplies (textual) guidance useful for facilitating decision making. One limiting factor of existing approaches is that their guidance compounds information about all possible outcomes, and as a result it can be difficult to digest. We address this issue by introducing ConfGuide, a novel LtG approach that generates more succinct and targeted guidance. To this end, it employs conformal risk control to select a set of outcomes, ensuring a cap on the false negative rate. We demonstrate our approach on a real-world multi-label medical diagnosis task. Our empirical evaluation highlights the promise of ConfGuide.
Towards Reliable Retrieval in RAG Systems for Large Legal Datasets
Oct 08, 2025



Retrieval-Augmented Generation (RAG) is a promising approach to mitigate hallucinations in Large Language Models (LLMs) for legal applications, but its reliability is critically dependent on the accuracy of the retrieval step. This is particularly challenging in the legal domain, where large databases of structurally similar documents often cause retrieval systems to fail. In this paper, we address this challenge by first identifying and quantifying a critical failure mode we term Document-Level Retrieval Mismatch (DRM), where the retriever selects information from entirely incorrect source documents. To mitigate DRM, we investigate a simple and computationally efficient technique which we refer to as Summary-Augmented Chunking (SAC). This method enhances each text chunk with a document-level synthetic summary, thereby injecting crucial global context that would otherwise be lost during a standard chunking process. Our experiments on a diverse set of legal information retrieval tasks show that SAC greatly reduces DRM and, consequently, also improves text-level retrieval precision and recall. Interestingly, we find that a generic summarization strategy outperforms an approach that incorporates legal expert domain knowledge to target specific legal elements. Our work provides evidence that this practical, scalable, and easily integrable technique enhances the reliability of RAG systems when applied to large-scale legal document datasets.
Do LLMs Provide Consistent Answers to Health-Related Questions across Languages?
Jan 24, 2025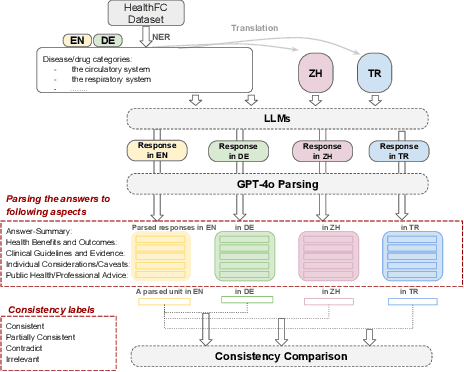
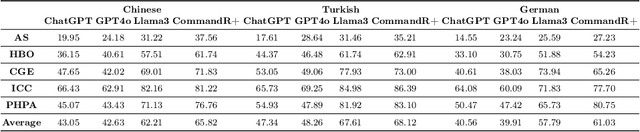

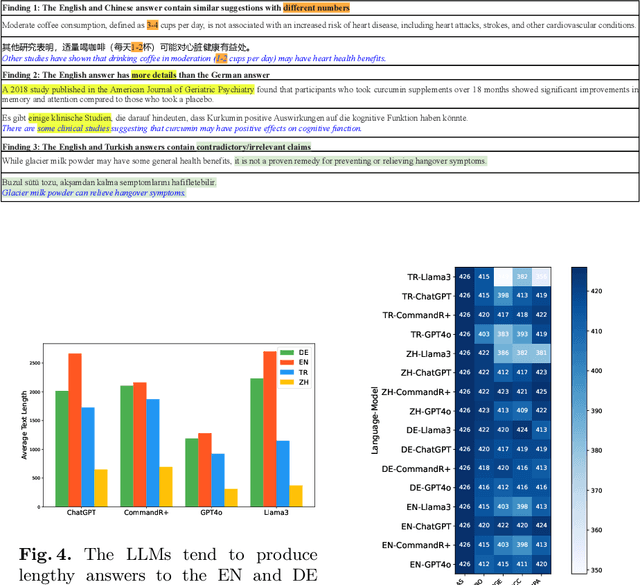
Equitable access to reliable health information is vital for public health, but the quality of online health resources varies by language, raising concerns about inconsistencies in Large Language Models (LLMs) for healthcare. In this study, we examine the consistency of responses provided by LLMs to health-related questions across English, German, Turkish, and Chinese. We largely expand the HealthFC dataset by categorizing health-related questions by disease type and broadening its multilingual scope with Turkish and Chinese translations. We reveal significant inconsistencies in responses that could spread healthcare misinformation. Our main contributions are 1) a multilingual health-related inquiry dataset with meta-information on disease categories, and 2) a novel prompt-based evaluation workflow that enables sub-dimensional comparisons between two languages through parsing. Our findings highlight key challenges in deploying LLM-based tools in multilingual contexts and emphasize the need for improved cross-lingual alignment to ensure accurate and equitable healthcare information.
Can LLMs Correct Physicians, Yet? Investigating Effective Interaction Methods in the Medical Domain
Mar 29, 2024



We explore the potential of Large Language Models (LLMs) to assist and potentially correct physicians in medical decision-making tasks. We evaluate several LLMs, including Meditron, Llama2, and Mistral, to analyze the ability of these models to interact effectively with physicians across different scenarios. We consider questions from PubMedQA and several tasks, ranging from binary (yes/no) responses to long answer generation, where the answer of the model is produced after an interaction with a physician. Our findings suggest that prompt design significantly influences the downstream accuracy of LLMs and that LLMs can provide valuable feedback to physicians, challenging incorrect diagnoses and contributing to more accurate decision-making. For example, when the physician is accurate 38% of the time, Mistral can produce the correct answer, improving accuracy up to 74% depending on the prompt being used, while Llama2 and Meditron models exhibit greater sensitivity to prompt choice. Our analysis also uncovers the challenges of ensuring that LLM-generated suggestions are pertinent and useful, emphasizing the need for further research in this area.
Learning To Guide Human Decision Makers With Vision-Language Models
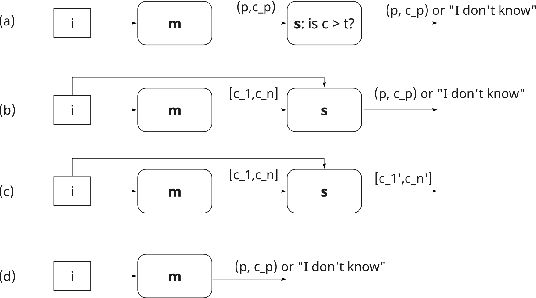
Mar 28, 2024There is increasing interest in developing AIs for assisting human decision-making in high-stakes tasks, such as medical diagnosis, for the purpose of improving decision quality and reducing cognitive strain. Mainstream approaches team up an expert with a machine learning model to which safer decisions are offloaded, thus letting the former focus on cases that demand their attention. his separation of responsibilities setup, however, is inadequate for high-stakes scenarios. On the one hand, the expert may end up over-relying on the machine's decisions due to anchoring bias, thus losing the human oversight that is increasingly being required by regulatory agencies to ensure trustworthy AI. On the other hand, the expert is left entirely unassisted on the (typically hardest) decisions on which the model abstained. As a remedy, we introduce learning to guide (LTG), an alternative framework in which - rather than taking control from the human expert - the machine provides guidance useful for decision making, and the human is entirely responsible for coming up with a decision. In order to ensure guidance is interpretable} and task-specific, we develop SLOG, an approach for turning any vision-language model into a capable generator of textual guidance by leveraging a modicum of human feedback. Our empirical evaluation highlights the promise of \method on a challenging, real-world medical diagnosis task.
Rethinking and Recomputing the Value of ML Models
Sep 30, 2022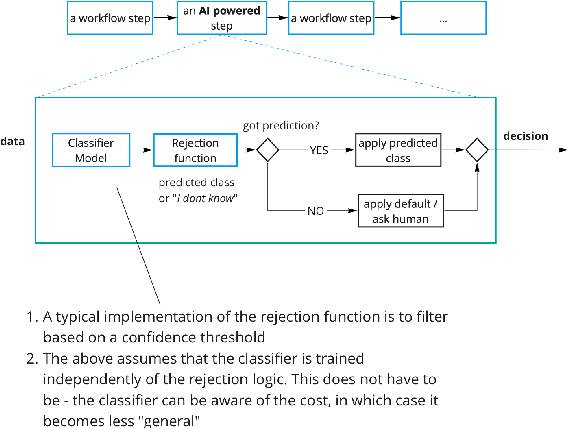
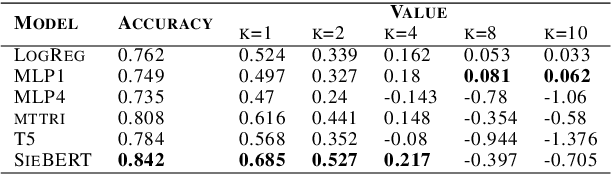
In this paper, we argue that the way we have been training and evaluating ML models has largely forgotten the fact that they are applied in an organization or societal context as they provide value to people. We show that with this perspective we fundamentally change how we evaluate, select and deploy ML models - and to some extent even what it means to learn. Specifically, we stress that the notion of value plays a central role in learning and evaluating, and different models may require different learning practices and provide different values based on the application context they are applied. We also show that this concretely impacts how we select and embed models into human workflows based on experimental datasets. Nothing of what is presented here is hard: to a large extent is a series of fairly trivial observations with massive practical implications.
The Science of Rejection: A Research Area for Human Computation
Nov 11, 2021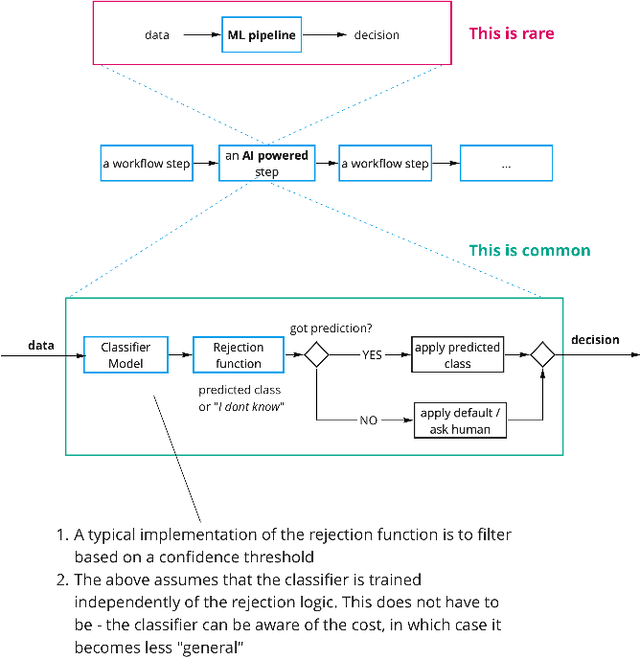
We motivate why the science of learning to reject model predictions is central to ML, and why human computation has a lead role in this effort.
Active Learning from Crowd in Document Screening
Nov 11, 2020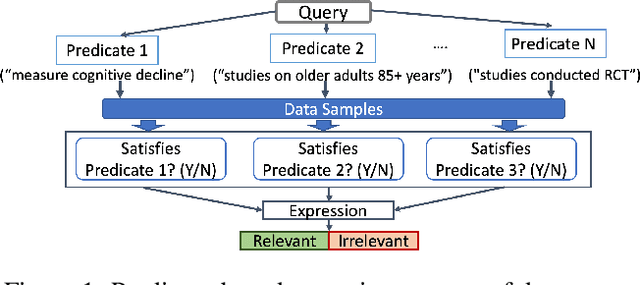

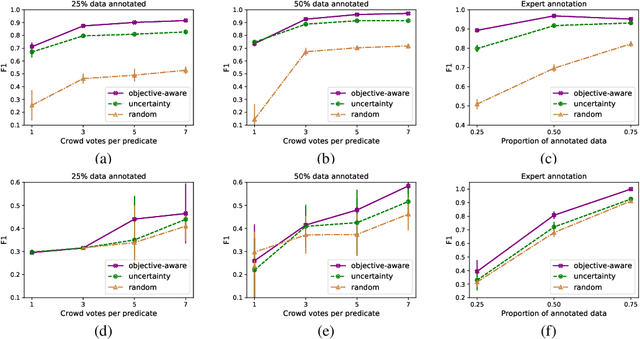
In this paper, we explore how to efficiently combine crowdsourcing and machine intelligence for the problem of document screening, where we need to screen documents with a set of machine-learning filters. Specifically, we focus on building a set of machine learning classifiers that evaluate documents, and then screen them efficiently. It is a challenging task since the budget is limited and there are countless number of ways to spend the given budget on the problem. We propose a multi-label active learning screening specific sampling technique -- objective-aware sampling -- for querying unlabelled documents for annotating. Our algorithm takes a decision on which machine filter need more training data and how to choose unlabeled items to annotate in order to minimize the risk of overall classification errors rather than minimizing a single filter error. We demonstrate that objective-aware sampling significantly outperforms the state of the art active learning sampling strategies.