 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Brushstroke Generation with Diffusion Models for Oil Painting
Mar 01, 2026Many creative multimedia systems are built upon visual primitives such as strokes or textures, which are difficult to collect at scale and fundamentally different from natural image data. This data scarcity makes it challenging for modern generative models to learn expressive and controllable primitives, limiting their use in process-aware content creation. In this work, we study the problem of learning human-like brushstroke generation from a small set of hand-drawn samples (n=470) and propose StrokeDiff, a diffusion-based framework with Smooth Regularization (SmR). SmR injects stochastic visual priors during training, providing a simple mechanism to stabilize diffusion models under sparse supervision without altering the inference process. We further show how the learned primitives can be made controllable through a Bézier-based conditioning module and integrated into a complete stroke-based painting pipeline, including prediction, generation, ordering, and compositing. This demonstrates how data-efficient primitive modeling can support expressive and structured multimedia content creation. Experiments indicate that the proposed approach produces diverse and structurally coherent brushstrokes and enables paintings with richer texture and layering, validated by both automatic metrics and human evaluation.
Factory Operators' Perspectives on Cognitive Assistants for Knowledge Sharing: Challenges, Risks, and Impact on Work
Sep 30, 2024

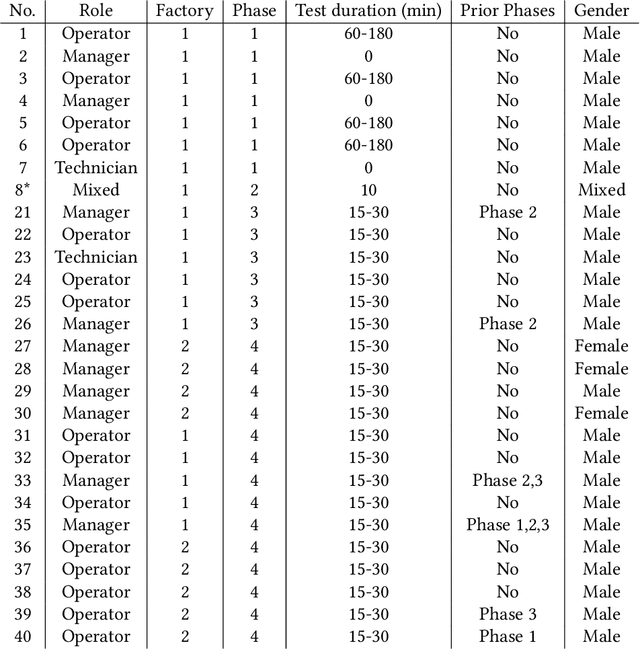

In the shift towards human-centered manufacturing, our two-year longitudinal study investigates the real-world impact of deploying Cognitive Assistants (CAs) in factories. The CAs were designed to facilitate knowledge sharing among factory operators. Our investigation focused on smartphone-based voice assistants and LLM-powered chatbots, examining their usability and utility in a real-world factory setting. Based on the qualitative feedback we collected during the deployments of CAs at the factories, we conducted a thematic analysis to investigate the perceptions, challenges, and overall impact on workflow and knowledge sharing. Our results indicate that while CAs have the potential to significantly improve efficiency through knowledge sharing and quicker resolution of production issues, they also introduce concerns around workplace surveillance, the types of knowledge that can be shared, and shortcomings compared to human-to-human knowledge sharing. Additionally, our findings stress the importance of addressing privacy, knowledge contribution burdens, and tensions between factory operators and their managers.
Model Selection with Model Zoo via Graph Learning
Apr 05, 2024



Pre-trained deep learning (DL) models are increasingly accessible in public repositories, i.e., model zoos. Given a new prediction task, finding the best model to fine-tune can be computationally intensive and costly, especially when the number of pre-trained models is large. Selecting the right pre-trained models is crucial, yet complicated by the diversity of models from various model families (like ResNet, Vit, Swin) and the hidden relationships between models and datasets. Existing methods, which utilize basic information from models and datasets to compute scores indicating model performance on target datasets, overlook the intrinsic relationships, limiting their effectiveness in model selection. In this study, we introduce TransferGraph, a novel framework that reformulates model selection as a graph learning problem. TransferGraph constructs a graph using extensive metadata extracted from models and datasets, while capturing their inherent relationships. Through comprehensive experiments across 16 real datasets, both images and texts, we demonstrate TransferGraph's effectiveness in capturing essential model-dataset relationships, yielding up to a 32% improvement in correlation between predicted performance and the actual fine-tuning results compared to the state-of-the-art methods.
Metadata Representations for Queryable ML Model Zoos
Jul 19, 2022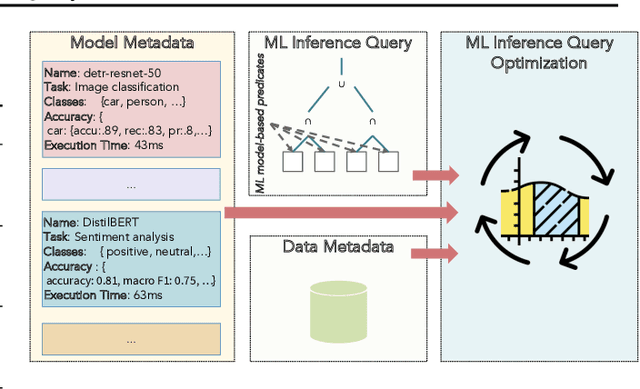
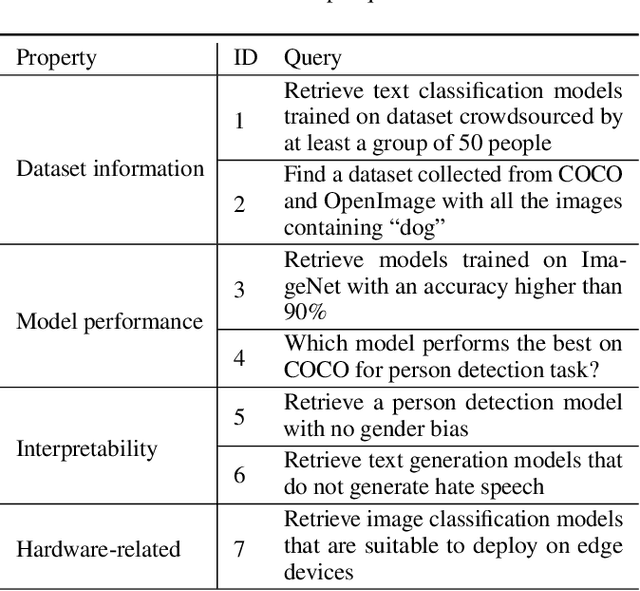
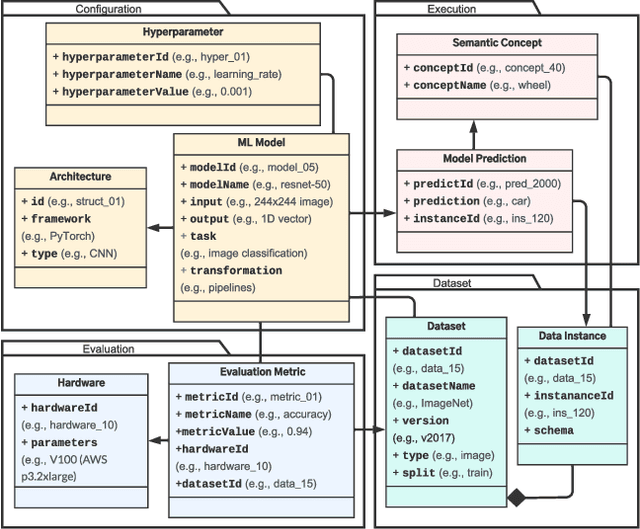
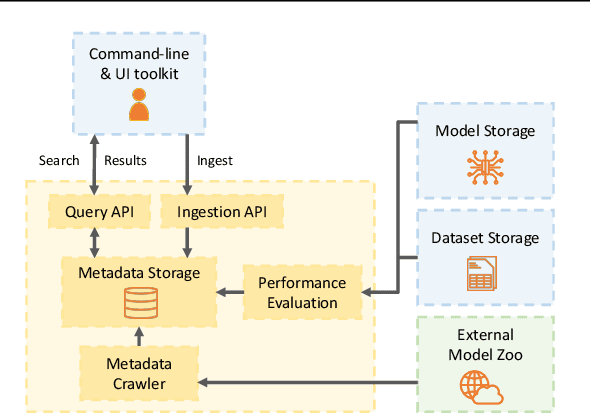
Machine learning (ML) practitioners and organizations are building model zoos of pre-trained models, containing metadata describing properties of the ML models and datasets that are useful for reporting, auditing, reproducibility, and interpretability purposes. The metatada is currently not standardised; its expressivity is limited; and there is no interoperable way to store and query it. Consequently, model search, reuse, comparison, and composition are hindered. In this paper, we advocate for standardized ML model meta-data representation and management, proposing a toolkit supported to help practitioners manage and query that metadata.
Towards a multi-stakeholder value-based assessment framework for algorithmic systems
May 09, 2022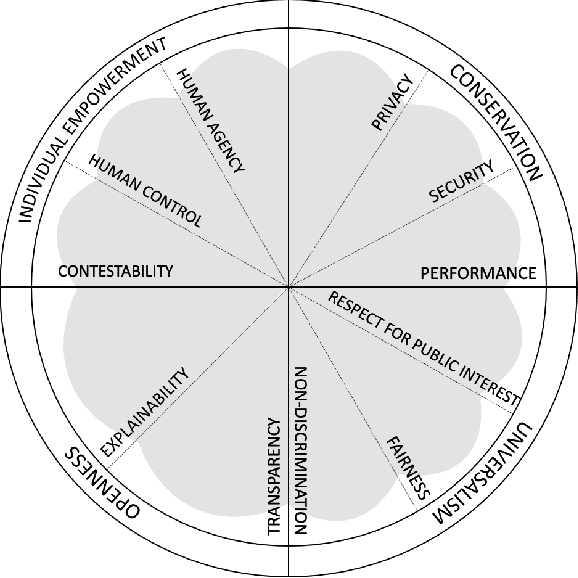

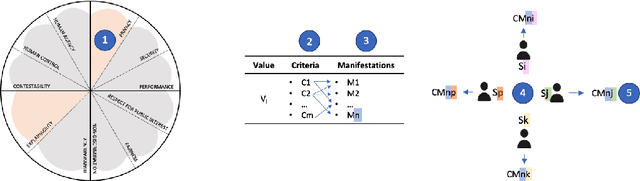
In an effort to regulate Machine Learning-driven (ML) systems, current auditing processes mostly focus on detecting harmful algorithmic biases. While these strategies have proven to be impactful, some values outlined in documents dealing with ethics in ML-driven systems are still underrepresented in auditing processes. Such unaddressed values mainly deal with contextual factors that cannot be easily quantified. In this paper, we develop a value-based assessment framework that is not limited to bias auditing and that covers prominent ethical principles for algorithmic systems. Our framework presents a circular arrangement of values with two bipolar dimensions that make common motivations and potential tensions explicit. In order to operationalize these high-level principles, values are then broken down into specific criteria and their manifestations. However, some of these value-specific criteria are mutually exclusive and require negotiation. As opposed to some other auditing frameworks that merely rely on ML researchers' and practitioners' input, we argue that it is necessary to include stakeholders that present diverse standpoints to systematically negotiate and consolidate value and criteria tensions. To that end, we map stakeholders with different insight needs, and assign tailored means for communicating value manifestations to them. We, therefore, contribute to current ML auditing practices with an assessment framework that visualizes closeness and tensions between values and we give guidelines on how to operationalize them, while opening up the evaluation and deliberation process to a wide range of stakeholders.
Empowering Local Communities Using Artificial Intelligence
Oct 05, 2021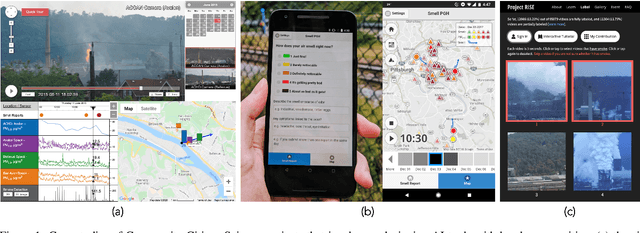
Many powerful Artificial Intelligence (AI) techniques have been engineered with the goals of high performance and accuracy. Recently, AI algorithms have been integrated into diverse and real-world applications. It has become an important topic to explore the impact of AI on society from a people-centered perspective. Previous works in citizen science have identified methods of using AI to engage the public in research, such as sustaining participation, verifying data quality, classifying and labeling objects, predicting user interests, and explaining data patterns. These works investigated the challenges regarding how scientists design AI systems for citizens to participate in research projects at a large geographic scale in a generalizable way, such as building applications for citizens globally to participate in completing tasks. In contrast, we are interested in another area that receives significantly less attention: how scientists co-design AI systems "with" local communities to influence a particular geographical region, such as community-based participatory projects. Specifically, this article discusses the challenges of applying AI in Community Citizen Science, a framework to create social impact through community empowerment at an intensely place-based local scale. We provide insights in this under-explored area of focus to connect scientific research closely to social issues and citizen needs.
Active Hybrid Classification
Jan 21, 2021
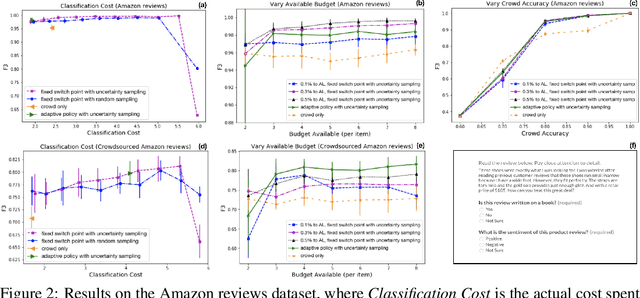
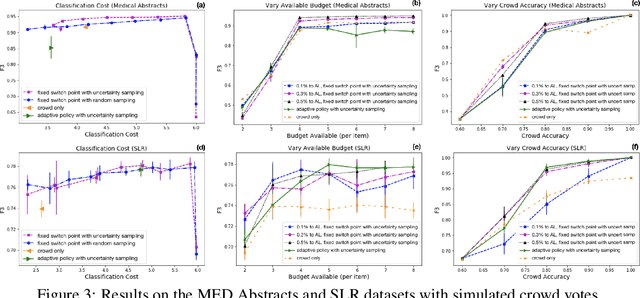
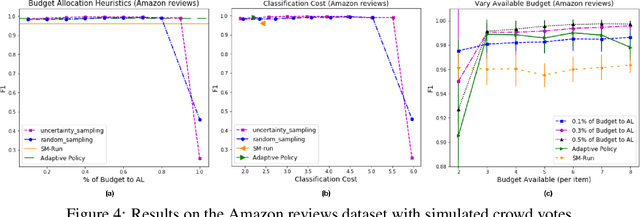
Hybrid crowd-machine classifiers can achieve superior performance by combining the cost-effectiveness of automatic classification with the accuracy of human judgment. This paper shows how crowd and machines can support each other in tackling classification problems. Specifically, we propose an architecture that orchestrates active learning and crowd classification and combines them in a virtuous cycle. We show that when the pool of items to classify is finite we face learning vs. exploitation trade-off in hybrid classification, as we need to balance crowd tasks optimized for creating a training dataset with tasks optimized for classifying items in the pool. We define the problem, propose a set of heuristics and evaluate the approach on three real-world datasets with different characteristics in terms of machine and crowd classification performance, showing that our active hybrid approach significantly outperforms baselines.
Active Learning from Crowd in Document Screening
Nov 11, 2020

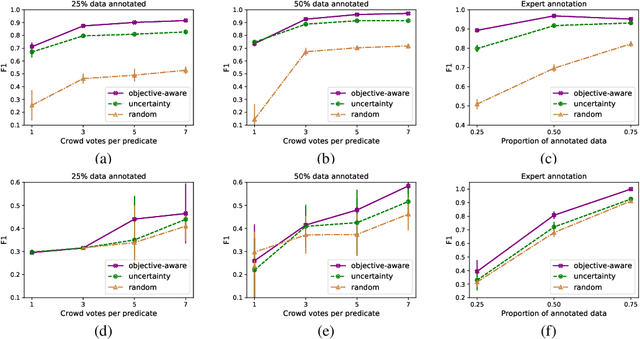
In this paper, we explore how to efficiently combine crowdsourcing and machine intelligence for the problem of document screening, where we need to screen documents with a set of machine-learning filters. Specifically, we focus on building a set of machine learning classifiers that evaluate documents, and then screen them efficiently. It is a challenging task since the budget is limited and there are countless number of ways to spend the given budget on the problem. We propose a multi-label active learning screening specific sampling technique -- objective-aware sampling -- for querying unlabelled documents for annotating. Our algorithm takes a decision on which machine filter need more training data and how to choose unlabeled items to annotate in order to minimize the risk of overall classification errors rather than minimizing a single filter error. We demonstrate that objective-aware sampling significantly outperforms the state of the art active learning sampling strategies.
Designing Evaluations of Machine Learning Models for Subjective Inference: The Case of Sentence Toxicity
Nov 06, 2019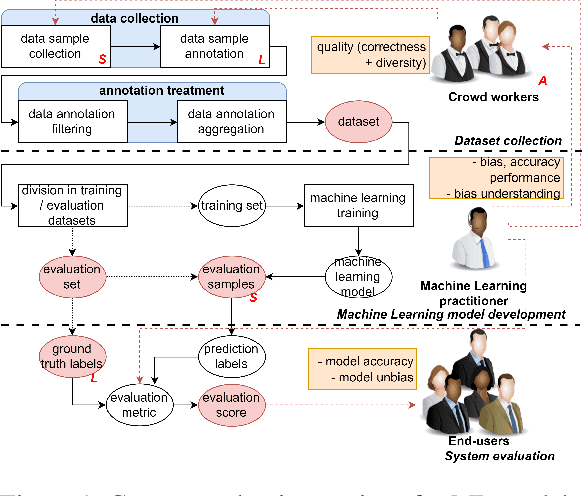

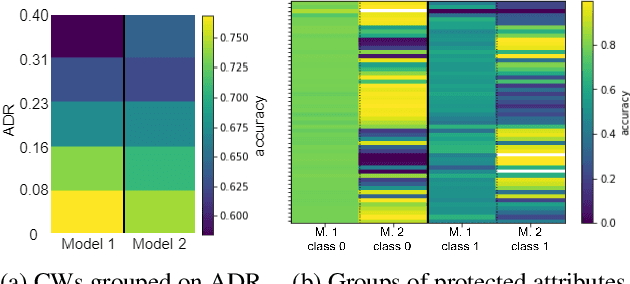
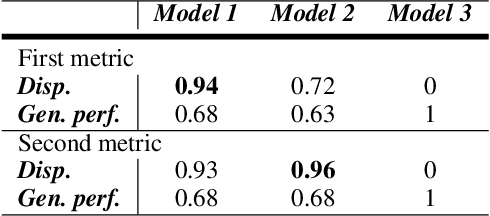
Machine Learning (ML) is increasingly applied in real-life scenarios, raising concerns about bias in automatic decision making. We focus on bias as a notion of opinion exclusion, that stems from the direct application of traditional ML pipelines to infer subjective properties. We argue that such ML systems should be evaluated with subjectivity and bias in mind. Considering the lack of evaluation standards yet to create evaluation benchmarks, we propose an initial list of specifications to define prior to creating evaluation datasets, in order to later accurately evaluate the biases. With the example of a sentence toxicity inference system, we illustrate how the specifications support the analysis of biases related to subjectivity. We highlight difficulties in instantiating these specifications and list future work for the crowdsourcing community to help the creation of appropriate evaluation datasets.
Unfairness towards subjective opinions in Machine Learning
Nov 06, 2019
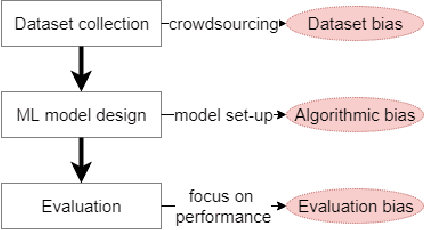
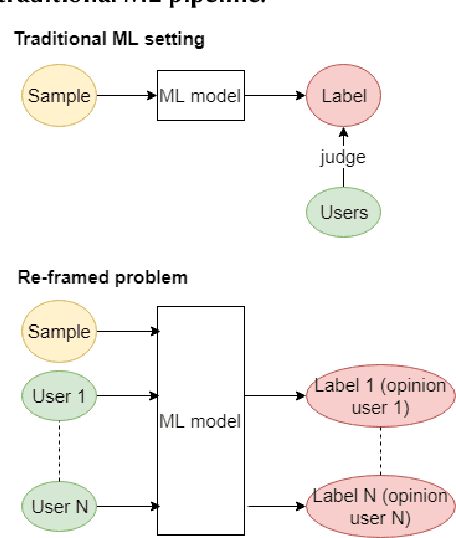
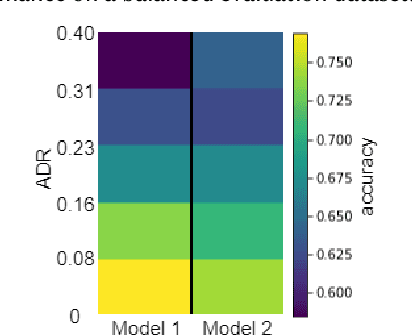
Despite the high interest for Machine Learning (ML) in academia and industry, many issues related to the application of ML to real-life problems are yet to be addressed. Here we put forward one limitation which arises from a lack of adaptation of ML models and datasets to specific applications. We formalise a new notion of unfairness as exclusion of opinions. We propose ways to quantify this unfairness, and aid understanding its causes through visualisation. These insights into the functioning of ML-based systems hint at methods to mitigate unfairness.