 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Factory Operators' Perspectives on Cognitive Assistants for Knowledge Sharing: Challenges, Risks, and Impact on Work
Sep 30, 2024

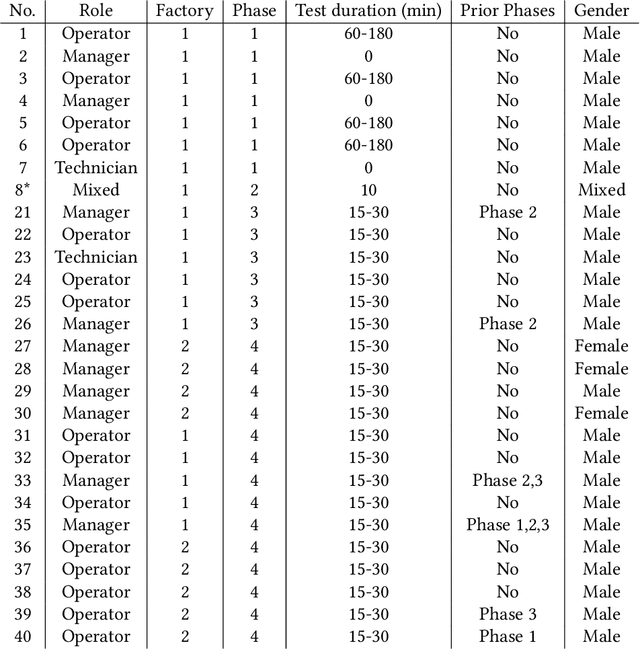

In the shift towards human-centered manufacturing, our two-year longitudinal study investigates the real-world impact of deploying Cognitive Assistants (CAs) in factories. The CAs were designed to facilitate knowledge sharing among factory operators. Our investigation focused on smartphone-based voice assistants and LLM-powered chatbots, examining their usability and utility in a real-world factory setting. Based on the qualitative feedback we collected during the deployments of CAs at the factories, we conducted a thematic analysis to investigate the perceptions, challenges, and overall impact on workflow and knowledge sharing. Our results indicate that while CAs have the potential to significantly improve efficiency through knowledge sharing and quicker resolution of production issues, they also introduce concerns around workplace surveillance, the types of knowledge that can be shared, and shortcomings compared to human-to-human knowledge sharing. Additionally, our findings stress the importance of addressing privacy, knowledge contribution burdens, and tensions between factory operators and their managers.
Chatbots in Knowledge-Intensive Contexts: Comparing Intent and LLM-Based Systems
Feb 07, 2024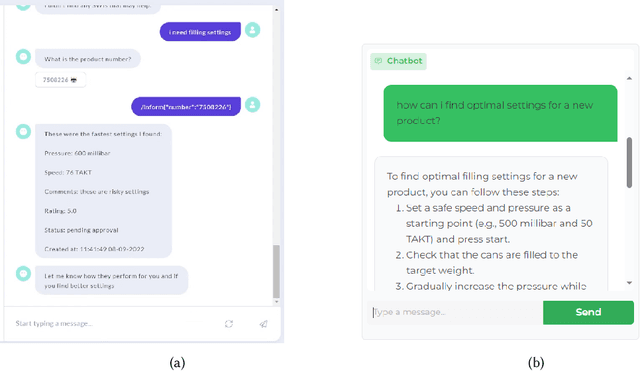


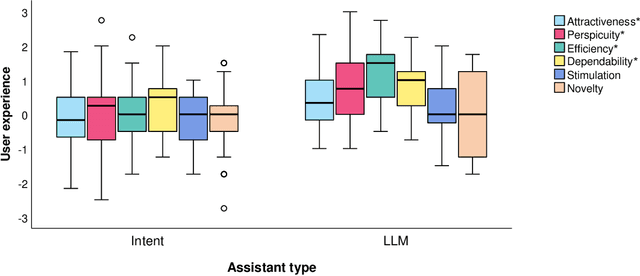
Cognitive assistants (CA) are chatbots that provide context-aware support to human workers in knowledge-intensive tasks. Traditionally, cognitive assistants respond in specific ways to predefined user intents and conversation patterns. However, this rigidness does not handle the diversity of natural language well. Recent advances in natural language processing (NLP), powering large language models (LLM) such as GPT-4, Llama2, and Gemini, could enable CAs to converse in a more flexible, human-like manner. However, the additional degrees of freedom may have unforeseen consequences, especially in knowledge-intensive contexts where accuracy is crucial. As a preliminary step to assessing the potential of using LLMs in these contexts, we conducted a user study comparing an LLM-based CA to an intent-based system regarding interaction efficiency, user experience, workload, and usability. This revealed that LLM-based CAs exhibited better user experience, task completion rate, usability, and perceived performance than intent-based systems, suggesting that switching NLP techniques should be investigated further.
Knowledge Sharing in Manufacturing using Large Language Models: User Evaluation and Model Benchmarking
Jan 10, 2024



Managing knowledge efficiently is crucial for organizational success. In manufacturing, operating factories has become increasing knowledge-intensive putting strain on the factory's capacity to train and support new operators. In this paper, we introduce a Large Language Model (LLM)-based system designed to use the extensive knowledge contained in factory documentation. The system aims to efficiently answer queries from operators and facilitate the sharing of new knowledge. To assess its effectiveness, we conducted an evaluation in a factory setting. The results of this evaluation demonstrated the system's benefits; namely, in enabling quicker information retrieval and more efficient resolution of issues. However, the study also highlighted a preference for learning from a human expert when such an option is available. Furthermore, we benchmarked several closed and open-sourced LLMs for this system. GPT-4 consistently outperformed its counterparts, with open-source models like StableBeluga2 trailing closely, presenting an attractive option given its data privacy and customization benefits. Overall, this work offers preliminary insights for factories considering using LLM-tools for knowledge management.
Heterogeneous Graph Tree Networks
Sep 01, 2022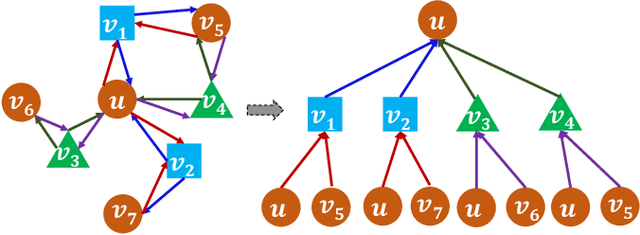
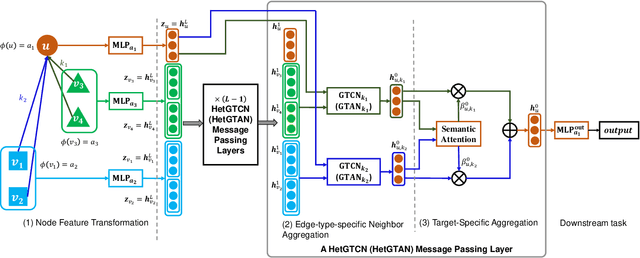
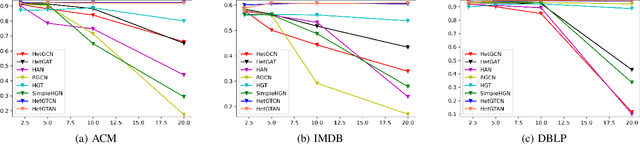
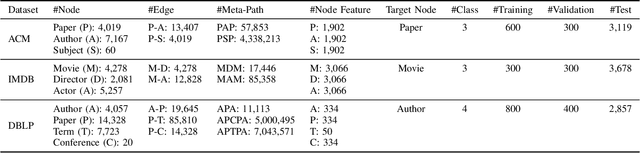
Heterogeneous graph neural networks (HGNNs) have attracted increasing research interest in recent three years. Most existing HGNNs fall into two classes. One class is meta-path-based HGNNs which either require domain knowledge to handcraft meta-paths or consume huge amount of time and memory to automatically construct meta-paths. The other class does not rely on meta-path construction. It takes homogeneous convolutional graph neural networks (Conv-GNNs) as backbones and extend them to heterogeneous graphs by introducing node-type- and edge-type-dependent parameters. Regardless of the meta-path dependency, most existing HGNNs employ shallow Conv-GNNs such as GCN and GAT to aggregate neighborhood information, and may have limited capability to capture information from high-order neighborhood. In this work, we propose two heterogeneous graph tree network models: Heterogeneous Graph Tree Convolutional Network (HetGTCN) and Heterogeneous Graph Tree Attention Network (HetGTAN), which do not rely on meta-paths to encode heterogeneity in both node features and graph structure. Extensive experiments on three real-world heterogeneous graph data demonstrate that the proposed HetGTCN and HetGTAN are efficient and consistently outperform all state-of-the-art HGNN baselines on semi-supervised node classification tasks, and can go deep without compromising performance.
GTNet: A Tree-Based Deep Graph Learning Architecture
Apr 27, 2022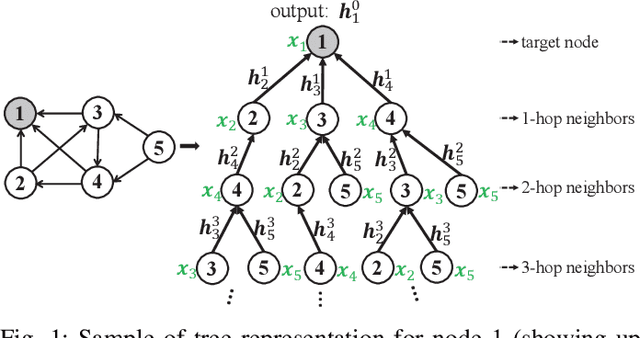

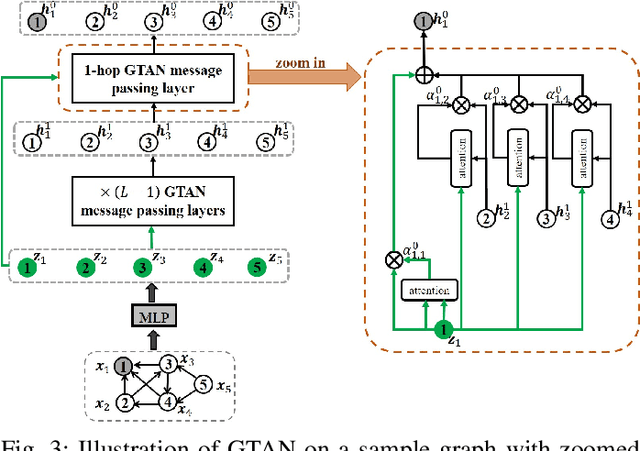
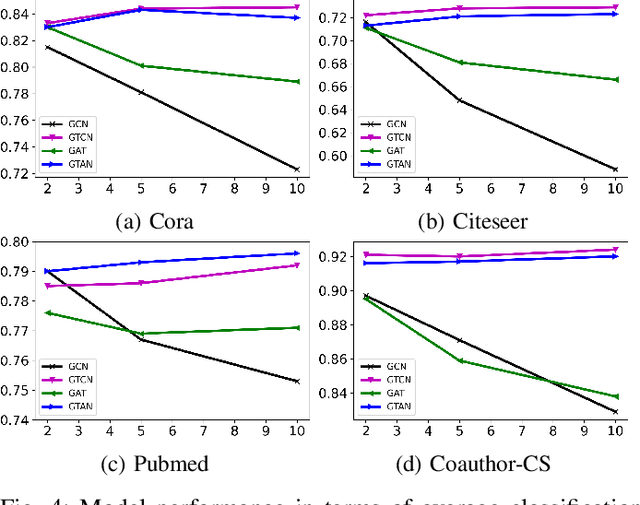
We propose Graph Tree Networks (GTNets), a deep graph learning architecture with a new general message passing scheme that originates from the tree representation of graphs. In the tree representation, messages propagate upward from the leaf nodes to the root node, and each node preserves its initial information prior to receiving information from its child nodes (neighbors). We formulate a general propagation rule following the nature of message passing in the tree to update a node's feature by aggregating its initial feature and its neighbor nodes' updated features. Two graph representation learning models are proposed within this GTNet architecture - Graph Tree Attention Network (GTAN) and Graph Tree Convolution Network (GTCN), with experimentally demonstrated state-of-the-art performance on several popular benchmark datasets. Unlike the vanilla Graph Attention Network (GAT) and Graph Convolution Network (GCN) which have the "over-smoothing" issue, the proposed GTAN and GTCN models can go deep as demonstrated by comprehensive experiments and rigorous theoretical analysis.