 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does Graph Structure Modulate Membership-Inference Risk for Graph Neural Networks?
Jan 23, 2026Graph neural networks (GNNs) have become the standard tool for encoding data and their complex relationships into continuous representations, improving prediction accuracy in several machine learning tasks like node classification and link prediction. However, their use in sensitive applications has raised concerns about the potential leakage of training data. Research on privacy leakage in GNNs has largely been shaped by findings from non-graph domains, such as images and tabular data. We emphasize the need of graph specific analysis and investigate the impact of graph structure on node level membership inference. We formalize MI over node-neighbourhood tuples and investigate two important dimensions: (i) training graph construction and (ii) inference-time edge access. Empirically, snowball's coverage bias often harms generalisation relative to random sampling, while enabling inter-train-test edges at inference improves test accuracy, shrinks the train-test gap, and yields the lowest membership advantage across most of the models and datasets. We further show that the generalisation gap empirically measured as the performance difference between the train and test nodes is an incomplete proxy for MI risk: access to edges dominates-MI can rise or fall independent of gap changes. Finally, we examine the auditability of differentially private GNNs, adapting the definition of statistical exchangeability of train-test data points for graph based models. We show that for node level tasks the inductive splits (random or snowball sampled) break exchangeability, limiting the applicability of standard bounds for membership advantage of differential private models.
Population-Scale Network Embeddings Expose Educational Divides in Network Structure Related to Right-Wing Populist Voting
Aug 28, 2025



Administrative registry data can be used to construct population-scale networks whose ties reflect shared social contexts between persons. With machine learning, such networks can be encoded into numerical representations -- embeddings -- that automatically capture individuals' position within the network. We created embeddings for all persons in the Dutch population from a population-scale network that represents five shared contexts: neighborhood, work, family, household, and school. To assess the informativeness of these embeddings, we used them to predict right-wing populist voting. Embeddings alone predicted right-wing populist voting above chance-level but performed worse than individual characteristics. Combining the best subset of embeddings with individual characteristics only slightly improved predictions. However, after transforming the embeddings to make their dimensions more sparse and orthogonal, we found that one embedding dimension was strongly associated with the outcome. Mapping this dimension back to the population network revealed differences in network structure related to right-wing populist voting between different school ties and achieved education levels. Our study contributes methodologically by demonstrating how population-scale network embeddings can be made interpretable, and substantively by linking structural network differences in education to right-wing populist voting.
GNN-MultiFix: Addressing the pitfalls for GNNs for multi-label node classification
Nov 21, 2024



Graph neural networks (GNNs) have emerged as powerful models for learning representations of graph data showing state of the art results in various tasks. Nevertheless, the superiority of these methods is usually supported by either evaluating their performance on small subset of benchmark datasets or by reasoning about their expressive power in terms of certain graph isomorphism tests. In this paper we critically analyse both these aspects through a transductive setting for the task of node classification. First, we delve deeper into the case of multi-label node classification which offers a more realistic scenario and has been ignored in most of the related works. Through analysing the training dynamics for GNN methods we highlight the failure of GNNs to learn over multi-label graph datasets even for the case of abundant training data. Second, we show that specifically for transductive node classification, even the most expressive GNN may fail to learn in absence of node attributes and without using explicit label information as input. To overcome this deficit, we propose a straightforward approach, referred to as GNN-MultiFix, that integrates the feature, label, and positional information of a node. GNN-MultiFix demonstrates significant improvement across all the multi-label datasets. We release our code at https://anonymous.4open.science/r/Graph-MultiFix-4121.
Disentangled and Self-Explainable Node Representation Learning
Oct 28, 2024



Node representations, or embeddings, are low-dimensional vectors that capture node properties, typically learned through unsupervised structural similarity objectives or supervised tasks. While recent efforts have focused on explaining graph model decisions, the interpretability of unsupervised node embeddings remains underexplored. To bridge this gap, we introduce DiSeNE (Disentangled and Self-Explainable Node Embedding), a framework that generates self-explainable embeddings in an unsupervised manner. Our method employs disentangled representation learning to produce dimension-wise interpretable embeddings, where each dimension is aligned with distinct topological structure of the graph. We formalize novel desiderata for disentangled and interpretable embeddings, which drive our new objective functions, optimizing simultaneously for both interpretability and disentanglement. Additionally, we propose several new metrics to evaluate representation quality and human interpretability. Extensive experiments across multiple benchmark datasets demonstrate the effectiveness of our approach.
A data-centric approach for assessing progress of Graph Neural Networks
Jun 18, 2024


Graph Neural Networks (GNNs) have achieved state-of-the-art results in node classification tasks. However, most improvements are in multi-class classification, with less focus on the cases where each node could have multiple labels. The first challenge in studying multi-label node classification is the scarcity of publicly available datasets. To address this, we collected and released three real-world biological datasets and developed a multi-label graph generator with tunable properties. We also argue that traditional notions of homophily and heterophily do not apply well to multi-label scenarios. Therefore, we define homophily and Cross-Class Neighborhood Similarity for multi-label classification and investigate $9$ collected multi-label datasets. Lastly, we conducted a large-scale comparative study with $8$ methods across nine datasets to evaluate current progress in multi-label node classification. We release our code at \url{https://github.com/Tianqi-py/MLGNC}.
Model Selection with Model Zoo via Graph Learning
Apr 05, 2024



Pre-trained deep learning (DL) models are increasingly accessible in public repositories, i.e., model zoos. Given a new prediction task, finding the best model to fine-tune can be computationally intensive and costly, especially when the number of pre-trained models is large. Selecting the right pre-trained models is crucial, yet complicated by the diversity of models from various model families (like ResNet, Vit, Swin) and the hidden relationships between models and datasets. Existing methods, which utilize basic information from models and datasets to compute scores indicating model performance on target datasets, overlook the intrinsic relationships, limiting their effectiveness in model selection. In this study, we introduce TransferGraph, a novel framework that reformulates model selection as a graph learning problem. TransferGraph constructs a graph using extensive metadata extracted from models and datasets, while capturing their inherent relationships. Through comprehensive experiments across 16 real datasets, both images and texts, we demonstrate TransferGraph's effectiveness in capturing essential model-dataset relationships, yielding up to a 32% improvement in correlation between predicted performance and the actual fine-tuning results compared to the state-of-the-art methods.
Efficient Neural Ranking using Forward Indexes and Lightweight Encoders
Nov 02, 2023Dual-encoder-based dense retrieval models have become the standard in IR. They employ large Transformer-based language models, which are notoriously inefficient in terms of resources and latency. We propose Fast-Forward indexes -- vector forward indexes which exploit the semantic matching capabilities of dual-encoder models for efficient and effective re-ranking. Our framework enables re-ranking at very high retrieval depths and combines the merits of both lexical and semantic matching via score interpolation. Furthermore, in order to mitigate the limitations of dual-encoders, we tackle two main challenges: Firstly, we improve computational efficiency by either pre-computing representations, avoiding unnecessary computations altogether, or reducing the complexity of encoders. This allows us to considerably improve ranking efficiency and latency. Secondly, we optimize the memory footprint and maintenance cost of indexes; we propose two complementary techniques to reduce the index size and show that, by dynamically dropping irrelevant document tokens, the index maintenance efficiency can be improved substantially. We perform evaluation to show the effectiveness and efficiency of Fast-Forward indexes -- our method has low latency and achieves competitive results without the need for hardware acceleration, such as GPUs.
DINE: Dimensional Interpretability of Node Embeddings
Oct 02, 2023

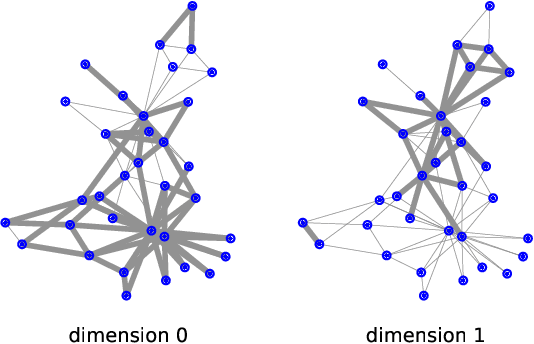

Graphs are ubiquitous due to their flexibility in representing social and technological systems as networks of interacting elements. Graph representation learning methods, such as node embeddings, are powerful approaches to map nodes into a latent vector space, allowing their use for various graph tasks. Despite their success, only few studies have focused on explaining node embeddings locally. Moreover, global explanations of node embeddings remain unexplored, limiting interpretability and debugging potentials. We address this gap by developing human-understandable explanations for dimensions in node embeddings. Towards that, we first develop new metrics that measure the global interpretability of embedding vectors based on the marginal contribution of the embedding dimensions to predicting graph structure. We say that an embedding dimension is more interpretable if it can faithfully map to an understandable sub-structure in the input graph - like community structure. Having observed that standard node embeddings have low interpretability, we then introduce DINE (Dimension-based Interpretable Node Embedding), a novel approach that can retrofit existing node embeddings by making them more interpretable without sacrificing their task performance. We conduct extensive experiments on synthetic and real-world graphs and show that we can simultaneously learn highly interpretable node embeddings with effective performance in link prediction.
Does Black-box Attribute Inference Attacks on Graph Neural Networks Constitute Privacy Risk?
Jun 01, 2023



Graph neural networks (GNNs) have shown promising results on real-life datasets and applications, including healthcare, finance, and education. However, recent studies have shown that GNNs are highly vulnerable to attacks such as membership inference attack and link reconstruction attack. Surprisingly, attribute inference attacks has received little attention. In this paper, we initiate the first investigation into attribute inference attack where an attacker aims to infer the sensitive user attributes based on her public or non-sensitive attributes. We ask the question whether black-box attribute inference attack constitutes a significant privacy risk for graph-structured data and their corresponding GNN model. We take a systematic approach to launch the attacks by varying the adversarial knowledge and assumptions. Our findings reveal that when an attacker has black-box access to the target model, GNNs generally do not reveal significantly more information compared to missing value estimation techniques. Code is available.
Multi-label Node Classification On Graph-Structured Data
Apr 20, 2023Graph Neural Networks (GNNs) have shown state-of-the-art improvements in node classification tasks on graphs. While these improvements have been largely demonstrated in a multi-class classification scenario, a more general and realistic scenario in which each node could have multiple labels has so far received little attention. The first challenge in conducting focused studies on multi-label node classification is the limited number of publicly available multi-label graph datasets. Therefore, as our first contribution, we collect and release three real-world biological datasets and develop a multi-label graph generator to generate datasets with tunable properties. While high label similarity (high homophily) is usually attributed to the success of GNNs, we argue that a multi-label scenario does not follow the usual semantics of homophily and heterophily so far defined for a multi-class scenario. As our second contribution, besides defining homophily for the multi-label scenario, we develop a new approach that dynamically fuses the feature and label correlation information to learn label-informed representations. Finally, we perform a large-scale comparative study with $10$ methods and $9$ datasets which also showcase the effectiveness of our approach. We release our benchmark at \url{https://anonymous.4open.science/r/LFLF-5D8C/}.