 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLEF-2026 CheckThat! Lab: Advancing Multilingual Fact-Checking
Feb 10, 2026The CheckThat! lab aims to advance the development of innovative technologies combating disinformation and manipulation efforts in online communication across a multitude of languages and platforms. While in early editions the focus has been on core tasks of the verification pipeline (check-worthiness, evidence retrieval, and verification), in the past three editions, the lab added additional tasks linked to the verification process. In this year's edition, the verification pipeline is at the center again with the following tasks: Task 1 on source retrieval for scientific web claims (a follow-up of the 2025 edition), Task 2 on fact-checking numerical and temporal claims, which adds a reasoning component to the 2025 edition, and Task 3, which expands the verification pipeline with generation of full-fact-checking articles. These tasks represent challenging classification and retrieval problems as well as generation challenges at the document and span level, including multilingual settings.
Think Right, Not More: Test-Time Scaling for Numerical Claim Verification
Sep 26, 2025



Fact-checking real-world claims, particularly numerical claims, is inherently complex that require multistep reasoning and numerical reasoning for verifying diverse aspects of the claim. Although large language models (LLMs) including reasoning models have made tremendous advances, they still fall short on fact-checking real-world claims that require a combination of compositional and numerical reasoning. They are unable to understand nuance of numerical aspects, and are also susceptible to the reasoning drift issue, where the model is unable to contextualize diverse information resulting in misinterpretation and backtracking of reasoning process. In this work, we systematically explore scaling test-time compute (TTS) for LLMs on the task of fact-checking complex numerical claims, which entails eliciting multiple reasoning paths from an LLM. We train a verifier model (VERIFIERFC) to navigate this space of possible reasoning paths and select one that could lead to the correct verdict. We observe that TTS helps mitigate the reasoning drift issue, leading to significant performance gains for fact-checking numerical claims. To improve compute efficiency in TTS, we introduce an adaptive mechanism that performs TTS selectively based on the perceived complexity of the claim. This approach achieves 1.8x higher efficiency than standard TTS, while delivering a notable 18.8% performance improvement over single-shot claim verification methods. Our code and data can be found at https://github.com/VenkteshV/VerifierFC
Sample Efficient Demonstration Selection for In-Context Learning
Jun 10, 2025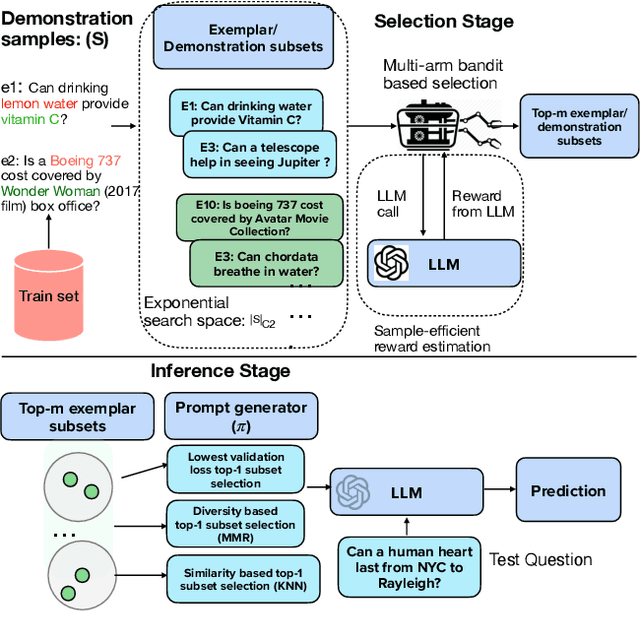
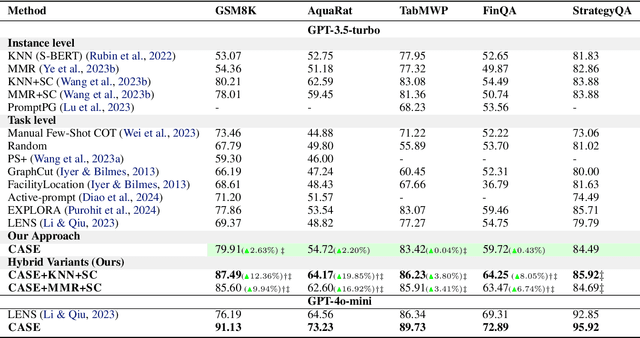
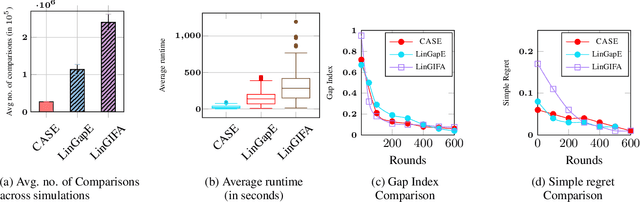
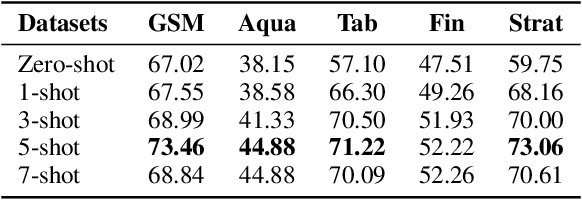
The in-context learning paradigm with LLMs has been instrumental in advancing a wide range of natural language processing tasks. The selection of few-shot examples (exemplars / demonstration samples) is essential for constructing effective prompts under context-length budget constraints. In this paper, we formulate the exemplar selection task as a top-m best arms identification problem. A key challenge in this setup is the exponentially large number of arms that need to be evaluated to identify the m-best arms. We propose CASE (Challenger Arm Sampling for Exemplar selection), a novel sample-efficient selective exploration strategy that maintains a shortlist of "challenger" arms, which are current candidates for the top-m arms. In each iteration, only one of the arms from this shortlist or the current topm set is pulled, thereby reducing sample complexity and, consequently, the number of LLM evaluations. Furthermore, we model the scores of exemplar subsets (arms) using a parameterized linear scoring function, leading to stochastic linear bandits setting. CASE achieves remarkable efficiency gains of up to 7x speedup in runtime while requiring 7x fewer LLM calls (87% reduction) without sacrificing performance compared to state-of-the-art exemplar selection methods. We release our code and data at https://github.com/kiranpurohit/CASE
It's High Time: A Survey of Temporal Information Retrieval and Question Answering
May 26, 2025Time plays a critical role in how information is generated, retrieved, and interpreted. In this survey, we provide a comprehensive overview of Temporal Information Retrieval and Temporal Question Answering, two research areas aimed at handling and understanding time-sensitive information. As the amount of time-stamped content from sources like news articles, web archives, and knowledge bases increases, systems must address challenges such as detecting temporal intent, normalizing time expressions, ordering events, and reasoning over evolving or ambiguous facts. These challenges are critical across many dynamic and time-sensitive domains, from news and encyclopedias to science, history, and social media. We review both traditional approaches and modern neural methods, including those that use transformer models and Large Language Models (LLMs). We also review recent advances in temporal language modeling, multi-hop reasoning, and retrieval-augmented generation (RAG), alongside benchmark datasets and evaluation strategies that test temporal robustness, recency awareness, and generalization.
Breaking the Lens of the Telescope: Online Relevance Estimation over Large Retrieval Sets
Apr 12, 2025



Advanced relevance models, such as those that use large language models (LLMs), provide highly accurate relevance estimations. However, their computational costs make them infeasible for processing large document corpora. To address this, retrieval systems often employ a telescoping approach, where computationally efficient but less precise lexical and semantic retrievers filter potential candidates for further ranking. However, this approach heavily depends on the quality of early-stage retrieval, which can potentially exclude relevant documents early in the process. In this work, we propose a novel paradigm for re-ranking called online relevance estimation that continuously updates relevance estimates for a query throughout the ranking process. Instead of re-ranking a fixed set of top-k documents in a single step, online relevance estimation iteratively re-scores smaller subsets of the most promising documents while adjusting relevance scores for the remaining pool based on the estimations from the final model using an online bandit-based algorithm. This dynamic process mitigates the recall limitations of telescoping systems by re-prioritizing documents initially deemed less relevant by earlier stages -- including those completely excluded by earlier-stage retrievers. We validate our approach on TREC benchmarks under two scenarios: hybrid retrieval and adaptive retrieval. Experimental results demonstrate that our method is sample-efficient and significantly improves recall, highlighting the effectiveness of our online relevance estimation framework for modern search systems.
Extending Dense Passage Retrieval with Temporal Information
Feb 28, 2025Temporal awareness is crucial in many information retrieval tasks, particularly in scenarios where the relevance of documents depends on their alignment with the query's temporal context. Traditional retrieval methods such as BM25 and Dense Passage Retrieval (DPR) excel at capturing lexical and semantic relevance but fall short in addressing time-sensitive queries. To bridge this gap, we introduce the temporal retrieval model that integrates explicit temporal signals by incorporating query timestamps and document dates into the representation space. Our approach ensures that retrieved passages are not only topically relevant but also temporally aligned with user intent. We evaluate our approach on two large-scale benchmark datasets, ArchivalQA and ChroniclingAmericaQA, achieving substantial performance gains over standard retrieval baselines. In particular, our model improves Top-1 retrieval accuracy by 6.63% and NDCG@10 by 3.79% on ArchivalQA, while yielding a 9.56% boost in Top-1 retrieval accuracy and 4.68% in NDCG@10 on ChroniclingAmericaQA. Additionally, we introduce a time-sensitive negative sampling strategy, which refines the model's ability to distinguish between temporally relevant and irrelevant documents during training. Our findings highlight the importance of explicitly modeling time in retrieval systems and set a new standard for handling temporally grounded queries.
FlashCheck: Exploration of Efficient Evidence Retrieval for Fast Fact-Checking
Feb 09, 2025


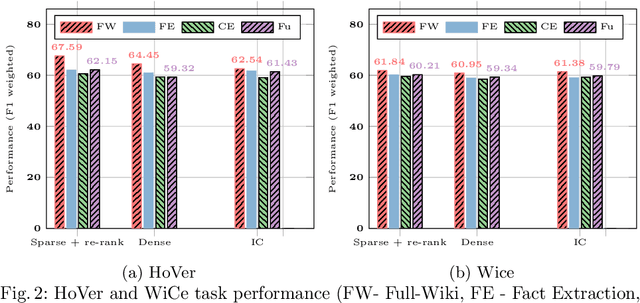
The advances in digital tools have led to the rampant spread of misinformation. While fact-checking aims to combat this, manual fact-checking is cumbersome and not scalable. It is essential for automated fact-checking to be efficient for aiding in combating misinformation in real-time and at the source. Fact-checking pipelines primarily comprise a knowledge retrieval component which extracts relevant knowledge to fact-check a claim from large knowledge sources like Wikipedia and a verification component. The existing works primarily focus on the fact-verification part rather than evidence retrieval from large data collections, which often face scalability issues for practical applications such as live fact-checking. In this study, we address this gap by exploring various methods for indexing a succinct set of factual statements from large collections like Wikipedia to enhance the retrieval phase of the fact-checking pipeline. We also explore the impact of vector quantization to further improve the efficiency of pipelines that employ dense retrieval approaches for first-stage retrieval. We study the efficiency and effectiveness of the approaches on fact-checking datasets such as HoVer and WiCE, leveraging Wikipedia as the knowledge source. We also evaluate the real-world utility of the efficient retrieval approaches by fact-checking 2024 presidential debate and also open source the collection of claims with corresponding labels identified in the debate. Through a combination of indexed facts together with Dense retrieval and Index compression, we achieve up to a 10.0x speedup on CPUs and more than a 20.0x speedup on GPUs compared to the classical fact-checking pipelines over large collections.
Guiding Retrieval using LLM-based Listwise Rankers
Jan 15, 2025Large Language Models (LLMs) have shown strong promise as rerankers, especially in ``listwise'' settings where an LLM is prompted to rerank several search results at once. However, this ``cascading'' retrieve-and-rerank approach is limited by the bounded recall problem: relevant documents not retrieved initially are permanently excluded from the final ranking. Adaptive retrieval techniques address this problem, but do not work with listwise rerankers because they assume a document's score is computed independently from other documents. In this paper, we propose an adaptation of an existing adaptive retrieval method that supports the listwise setting and helps guide the retrieval process itself (thereby overcoming the bounded recall problem for LLM rerankers). Specifically, our proposed algorithm merges results both from the initial ranking and feedback documents provided by the most relevant documents seen up to that point. Through extensive experiments across diverse LLM rerankers, first stage retrievers, and feedback sources, we demonstrate that our method can improve nDCG@10 by up to 13.23% and recall by 28.02%--all while keeping the total number of LLM inferences constant and overheads due to the adaptive process minimal. The work opens the door to leveraging LLM-based search in settings where the initial pool of results is limited, e.g., by legacy systems, or by the cost of deploying a semantic first-stage.
Correctness is not Faithfulness in RAG Attributions
Dec 23, 2024Retrieving relevant context is a common approach to reduce hallucinations and enhance answer reliability. Explicitly citing source documents allows users to verify generated responses and increases trust. Prior work largely evaluates citation correctness - whether cited documents support the corresponding statements. But citation correctness alone is insufficient. To establish trust in attributed answers, we must examine both citation correctness and citation faithfulness. In this work, we first disentangle the notions of citation correctness and faithfulness, which have been applied inconsistently in previous studies. Faithfulness ensures that the model's reliance on cited documents is genuine, reflecting actual reference use rather than superficial alignment with prior beliefs, which we call post-rationalization. We design an experiment that reveals the prevalent issue of post-rationalization, which undermines reliable attribution and may result in misplaced trust. Our findings suggest that current attributed answers often lack citation faithfulness (up to 57 percent of the citations), highlighting the need to evaluate correctness and faithfulness for trustworthy attribution in language models.
DISCO: DISCovering Overfittings as Causal Rules for Text Classification Models
Nov 07, 2024



With the rapid advancement of neural language models, the deployment of over-parameterized models has surged, increasing the need for interpretable explanations comprehensible to human inspectors. Existing post-hoc interpretability methods, which often focus on unigram features of single input textual instances, fail to capture the models' decision-making process fully. Additionally, many methods do not differentiate between decisions based on spurious correlations and those based on a holistic understanding of the input. Our paper introduces DISCO, a novel method for discovering global, rule-based explanations by identifying causal n-gram associations with model predictions. This method employs a scalable sequence mining technique to extract relevant text spans from training data, associate them with model predictions, and conduct causality checks to distill robust rules that elucidate model behavior. These rules expose potential overfitting and provide insights into misleading feature combinations. We validate DISCO through extensive testing, demonstrating its superiority over existing methods in offering comprehensive insights into complex model behaviors. Our approach successfully identifies all shortcuts manually introduced into the training data (100% detection rate on the MultiRC dataset), resulting in an 18.8% regression in model performance -- a capability unmatched by any other method. Furthermore, DISCO supports interactive explanations, enabling human inspectors to distinguish spurious causes in the rule-based output. This alleviates the burden of abundant instance-wise explanations and helps assess the model's risk when encountering out-of-distribution (OOD) data.