 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne LLM to Train Them All: Multi-Task Learning Framework for Fact-Checking
Jan 16, 2026Large language models (LLMs) are reshaping automated fact-checking (AFC) by enabling unified, end-to-end verification pipelines rather than isolated components. While large proprietary models achieve strong performance, their closed weights, complexity, and high costs limit sustainability. Fine-tuning smaller open weight models for individual AFC tasks can help but requires multiple specialized models resulting in high costs. We propose \textbf{multi-task learning (MTL)} as a more efficient alternative that fine-tunes a single model to perform claim detection, evidence ranking, and stance detection jointly. Using small decoder-only LLMs (e.g., Qwen3-4b), we explore three MTL strategies: classification heads, causal language modeling heads, and instruction-tuning, and evaluate them across model sizes, task orders, and standard non-LLM baselines. While multitask models do not universally surpass single-task baselines, they yield substantial improvements, achieving up to \textbf{44\%}, \textbf{54\%}, and \textbf{31\%} relative gains for claim detection, evidence re-ranking, and stance detection, respectively, over zero-/few-shot settings. Finally, we also provide practical, empirically grounded guidelines to help practitioners apply MTL with LLMs for automated fact-checking.
NumPert: Numerical Perturbations to Probe Language Models for Veracity Prediction
Nov 13, 2025Large language models show strong performance on knowledge intensive tasks such as fact-checking and question answering, yet they often struggle with numerical reasoning. We present a systematic evaluation of state-of-the-art models for veracity prediction on numerical claims and evidence pairs using controlled perturbations, including label-flipping probes, to test robustness. Our results indicate that even leading proprietary systems experience accuracy drops of up to 62\% under certain perturbations. No model proves to be robust across all conditions. We further find that increasing context length generally reduces accuracy, but when extended context is enriched with perturbed demonstrations, most models substantially recover. These findings highlight critical limitations in numerical fact-checking and suggest that robustness remains an open challenge for current language models.
Think Right, Not More: Test-Time Scaling for Numerical Claim Verification
Sep 26, 2025



Fact-checking real-world claims, particularly numerical claims, is inherently complex that require multistep reasoning and numerical reasoning for verifying diverse aspects of the claim. Although large language models (LLMs) including reasoning models have made tremendous advances, they still fall short on fact-checking real-world claims that require a combination of compositional and numerical reasoning. They are unable to understand nuance of numerical aspects, and are also susceptible to the reasoning drift issue, where the model is unable to contextualize diverse information resulting in misinterpretation and backtracking of reasoning process. In this work, we systematically explore scaling test-time compute (TTS) for LLMs on the task of fact-checking complex numerical claims, which entails eliciting multiple reasoning paths from an LLM. We train a verifier model (VERIFIERFC) to navigate this space of possible reasoning paths and select one that could lead to the correct verdict. We observe that TTS helps mitigate the reasoning drift issue, leading to significant performance gains for fact-checking numerical claims. To improve compute efficiency in TTS, we introduce an adaptive mechanism that performs TTS selectively based on the perceived complexity of the claim. This approach achieves 1.8x higher efficiency than standard TTS, while delivering a notable 18.8% performance improvement over single-shot claim verification methods. Our code and data can be found at https://github.com/VenkteshV/VerifierFC
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
FactIR: A Real-World Zero-shot Open-Domain Retrieval Benchmark for Fact-Checking
Feb 09, 2025

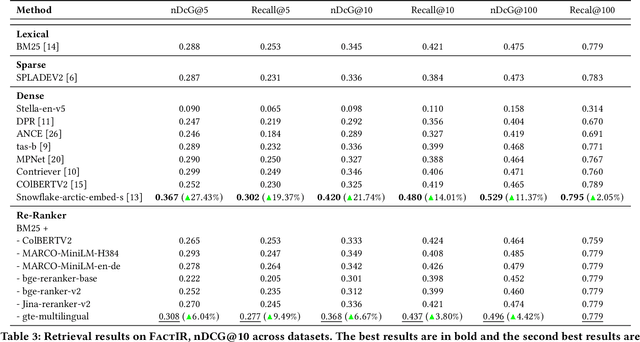
The field of automated fact-checking increasingly depends on retrieving web-based evidence to determine the veracity of claims in real-world scenarios. A significant challenge in this process is not only retrieving relevant information, but also identifying evidence that can both support and refute complex claims. Traditional retrieval methods may return documents that directly address claims or lean toward supporting them, but often struggle with more complex claims requiring indirect reasoning. While some existing benchmarks and methods target retrieval for fact-checking, a comprehensive real-world open-domain benchmark has been lacking. In this paper, we present a real-world retrieval benchmark FactIR, derived from Factiverse production logs, enhanced with human annotations. We rigorously evaluate state-of-the-art retrieval models in a zero-shot setup on FactIR and offer insights for developing practical retrieval systems for fact-checking. Code and data are available at https://github.com/factiverse/factIR.
FlashCheck: Exploration of Efficient Evidence Retrieval for Fast Fact-Checking
Feb 09, 2025


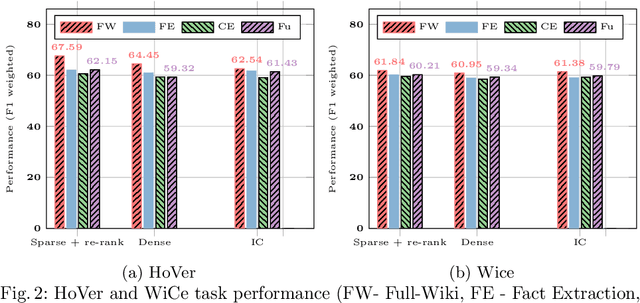
The advances in digital tools have led to the rampant spread of misinformation. While fact-checking aims to combat this, manual fact-checking is cumbersome and not scalable. It is essential for automated fact-checking to be efficient for aiding in combating misinformation in real-time and at the source. Fact-checking pipelines primarily comprise a knowledge retrieval component which extracts relevant knowledge to fact-check a claim from large knowledge sources like Wikipedia and a verification component. The existing works primarily focus on the fact-verification part rather than evidence retrieval from large data collections, which often face scalability issues for practical applications such as live fact-checking. In this study, we address this gap by exploring various methods for indexing a succinct set of factual statements from large collections like Wikipedia to enhance the retrieval phase of the fact-checking pipeline. We also explore the impact of vector quantization to further improve the efficiency of pipelines that employ dense retrieval approaches for first-stage retrieval. We study the efficiency and effectiveness of the approaches on fact-checking datasets such as HoVer and WiCE, leveraging Wikipedia as the knowledge source. We also evaluate the real-world utility of the efficient retrieval approaches by fact-checking 2024 presidential debate and also open source the collection of claims with corresponding labels identified in the debate. Through a combination of indexed facts together with Dense retrieval and Index compression, we achieve up to a 10.0x speedup on CPUs and more than a 20.0x speedup on GPUs compared to the classical fact-checking pipelines over large collections.
Annotation Tool and Dataset for Fact-Checking Podcasts
Feb 03, 2025



Podcasts are a popular medium on the web, featuring diverse and multilingual content that often includes unverified claims. Fact-checking podcasts is a challenging task, requiring transcription, annotation, and claim verification, all while preserving the contextual details of spoken content. Our tool offers a novel approach to tackle these challenges by enabling real-time annotation of podcasts during playback. This unique capability allows users to listen to the podcast and annotate key elements, such as check-worthy claims, claim spans, and contextual errors, simultaneously. By integrating advanced transcription models like OpenAI's Whisper and leveraging crowdsourced annotations, we create high-quality datasets to fine-tune multilingual transformer models such as XLM-RoBERTa for tasks like claim detection and stance classification. Furthermore, we release the annotated podcast transcripts and sample annotations with preliminary experiments.
DISCO: DISCovering Overfittings as Causal Rules for Text Classification Models
Nov 07, 2024



With the rapid advancement of neural language models, the deployment of over-parameterized models has surged, increasing the need for interpretable explanations comprehensible to human inspectors. Existing post-hoc interpretability methods, which often focus on unigram features of single input textual instances, fail to capture the models' decision-making process fully. Additionally, many methods do not differentiate between decisions based on spurious correlations and those based on a holistic understanding of the input. Our paper introduces DISCO, a novel method for discovering global, rule-based explanations by identifying causal n-gram associations with model predictions. This method employs a scalable sequence mining technique to extract relevant text spans from training data, associate them with model predictions, and conduct causality checks to distill robust rules that elucidate model behavior. These rules expose potential overfitting and provide insights into misleading feature combinations. We validate DISCO through extensive testing, demonstrating its superiority over existing methods in offering comprehensive insights into complex model behaviors. Our approach successfully identifies all shortcuts manually introduced into the training data (100% detection rate on the MultiRC dataset), resulting in an 18.8% regression in model performance -- a capability unmatched by any other method. Furthermore, DISCO supports interactive explanations, enabling human inspectors to distinguish spurious causes in the rule-based output. This alleviates the burden of abundant instance-wise explanations and helps assess the model's risk when encountering out-of-distribution (OOD) data.
LiveFC: A System for Live Fact-Checking of Audio Streams
Aug 14, 2024



The advances in the digital era have led to rapid dissemination of information. This has also aggravated the spread of misinformation and disinformation. This has potentially serious consequences, such as civil unrest. While fact-checking aims to combat this, manual fact-checking is cumbersome and not scalable. While automated fact-checking approaches exist, they do not operate in real-time and do not always account for spread of misinformation through different modalities. This is particularly important as proactive fact-checking on live streams in real-time can help people be informed of false narratives and prevent catastrophic consequences that may cause civil unrest. This is particularly relevant with the rapid dissemination of information through video on social media platforms or other streams like political rallies and debates. Hence, in this work we develop a platform named \name{}, that can aid in fact-checking live audio streams in real-time. \name{} has a user-friendly interface that displays the claims detected along with their veracity and evidence for live streams with associated speakers for claims from respective segments. The app can be accessed at http://livefc.factiverse.ai and a screen recording of the demo can be found at https://bit.ly/3WVAoIw.
IAI Group at CheckThat! 2024: Transformer Models and Data Augmentation for Checkworthy Claim Detection
Aug 02, 2024This paper describes IAI group's participation for automated check-worthiness estimation for claims, within the framework of the 2024 CheckThat! Lab "Task 1: Check-Worthiness Estimation". The task involves the automated detection of check-worthy claims in English, Dutch, and Arabic political debates and Twitter data. We utilized various pre-trained generative decoder and encoder transformer models, employing methods such as few-shot chain-of-thought reasoning, fine-tuning, data augmentation, and transfer learning from one language to another. Despite variable success in terms of performance, our models achieved notable placements on the organizer's leaderboard: ninth-best in English, third-best in Dutch, and the top placement in Arabic, utilizing multilingual datasets for enhancing the generalizability of check-worthiness detection. Despite a significant drop in performance on the unlabeled test dataset compared to the development test dataset, our findings contribute to the ongoing efforts in claim detection research, highlighting the challenges and potential of language-specific adaptations in claim verification systems.