 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Lens of the Telescope: Online Relevance Estimation over Large Retrieval Sets
Apr 12, 2025Advanced relevance models, such as those that use large language models (LLMs), provide highly accurate relevance estimations. However, their computational costs make them infeasible for processing large document corpora. To address this, retrieval systems often employ a telescoping approach, where computationally efficient but less precise lexical and semantic retrievers filter potential candidates for further ranking. However, this approach heavily depends on the quality of early-stage retrieval, which can potentially exclude relevant documents early in the process. In this work, we propose a novel paradigm for re-ranking called online relevance estimation that continuously updates relevance estimates for a query throughout the ranking process. Instead of re-ranking a fixed set of top-k documents in a single step, online relevance estimation iteratively re-scores smaller subsets of the most promising documents while adjusting relevance scores for the remaining pool based on the estimations from the final model using an online bandit-based algorithm. This dynamic process mitigates the recall limitations of telescoping systems by re-prioritizing documents initially deemed less relevant by earlier stages -- including those completely excluded by earlier-stage retrievers. We validate our approach on TREC benchmarks under two scenarios: hybrid retrieval and adaptive retrieval. Experimental results demonstrate that our method is sample-efficient and significantly improves recall, highlighting the effectiveness of our online relevance estimation framework for modern search systems.
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
FlashCheck: Exploration of Efficient Evidence Retrieval for Fast Fact-Checking
Feb 09, 2025


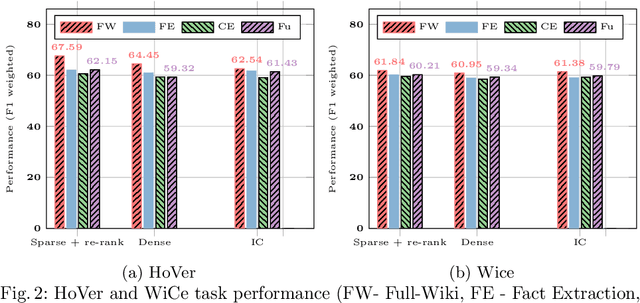
The advances in digital tools have led to the rampant spread of misinformation. While fact-checking aims to combat this, manual fact-checking is cumbersome and not scalable. It is essential for automated fact-checking to be efficient for aiding in combating misinformation in real-time and at the source. Fact-checking pipelines primarily comprise a knowledge retrieval component which extracts relevant knowledge to fact-check a claim from large knowledge sources like Wikipedia and a verification component. The existing works primarily focus on the fact-verification part rather than evidence retrieval from large data collections, which often face scalability issues for practical applications such as live fact-checking. In this study, we address this gap by exploring various methods for indexing a succinct set of factual statements from large collections like Wikipedia to enhance the retrieval phase of the fact-checking pipeline. We also explore the impact of vector quantization to further improve the efficiency of pipelines that employ dense retrieval approaches for first-stage retrieval. We study the efficiency and effectiveness of the approaches on fact-checking datasets such as HoVer and WiCE, leveraging Wikipedia as the knowledge source. We also evaluate the real-world utility of the efficient retrieval approaches by fact-checking 2024 presidential debate and also open source the collection of claims with corresponding labels identified in the debate. Through a combination of indexed facts together with Dense retrieval and Index compression, we achieve up to a 10.0x speedup on CPUs and more than a 20.0x speedup on GPUs compared to the classical fact-checking pipelines over large collections.
FactIR: A Real-World Zero-shot Open-Domain Retrieval Benchmark for Fact-Checking
Feb 09, 2025

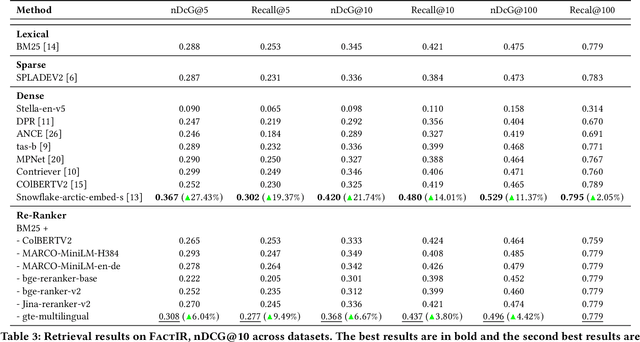
The field of automated fact-checking increasingly depends on retrieving web-based evidence to determine the veracity of claims in real-world scenarios. A significant challenge in this process is not only retrieving relevant information, but also identifying evidence that can both support and refute complex claims. Traditional retrieval methods may return documents that directly address claims or lean toward supporting them, but often struggle with more complex claims requiring indirect reasoning. While some existing benchmarks and methods target retrieval for fact-checking, a comprehensive real-world open-domain benchmark has been lacking. In this paper, we present a real-world retrieval benchmark FactIR, derived from Factiverse production logs, enhanced with human annotations. We rigorously evaluate state-of-the-art retrieval models in a zero-shot setup on FactIR and offer insights for developing practical retrieval systems for fact-checking. Code and data are available at https://github.com/factiverse/factIR.
EXPLORA: Efficient Exemplar Subset Selection for Complex Reasoning
Nov 06, 2024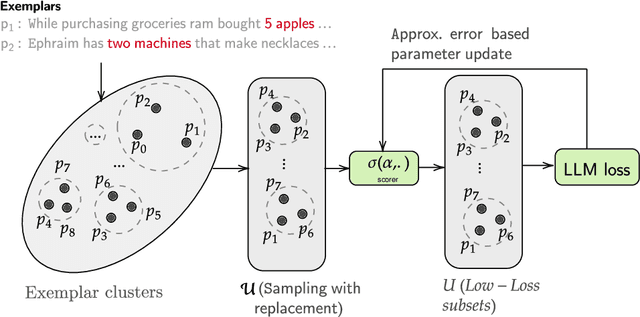


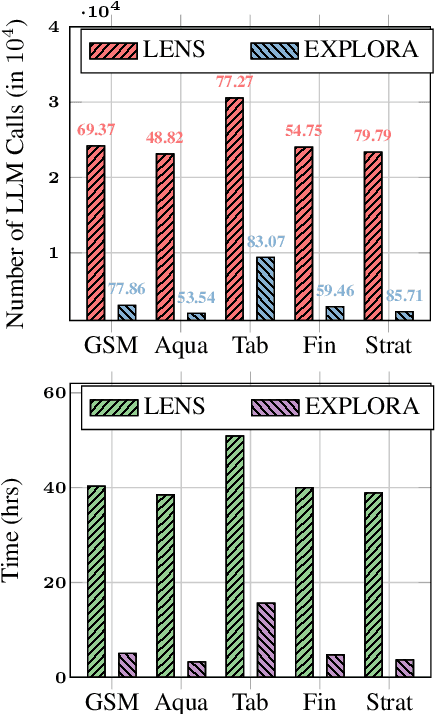
Answering reasoning-based complex questions over text and hybrid sources, including tables, is a challenging task. Recent advances in large language models (LLMs) have enabled in-context learning (ICL), allowing LLMs to acquire proficiency in a specific task using only a few demonstration samples (exemplars). A critical challenge in ICL is the selection of optimal exemplars, which can be either task-specific (static) or test-example-specific (dynamic). Static exemplars provide faster inference times and increased robustness across a distribution of test examples. In this paper, we propose an algorithm for static exemplar subset selection for complex reasoning tasks. We introduce EXPLORA, a novel exploration method designed to estimate the parameters of the scoring function, which evaluates exemplar subsets without incorporating confidence information. EXPLORA significantly reduces the number of LLM calls to ~11% of those required by state-of-the-art methods and achieves a substantial performance improvement of 12.24%. We open-source our code and data (https://github.com/kiranpurohit/EXPLORA).
LiveFC: A System for Live Fact-Checking of Audio Streams
Aug 14, 2024



The advances in the digital era have led to rapid dissemination of information. This has also aggravated the spread of misinformation and disinformation. This has potentially serious consequences, such as civil unrest. While fact-checking aims to combat this, manual fact-checking is cumbersome and not scalable. While automated fact-checking approaches exist, they do not operate in real-time and do not always account for spread of misinformation through different modalities. This is particularly important as proactive fact-checking on live streams in real-time can help people be informed of false narratives and prevent catastrophic consequences that may cause civil unrest. This is particularly relevant with the rapid dissemination of information through video on social media platforms or other streams like political rallies and debates. Hence, in this work we develop a platform named \name{}, that can aid in fact-checking live audio streams in real-time. \name{} has a user-friendly interface that displays the claims detected along with their veracity and evidence for live streams with associated speakers for claims from respective segments. The app can be accessed at http://livefc.factiverse.ai and a screen recording of the demo can be found at https://bit.ly/3WVAoIw.
The Surprising Effectiveness of Rankers Trained on Expanded Queries
Apr 03, 2024
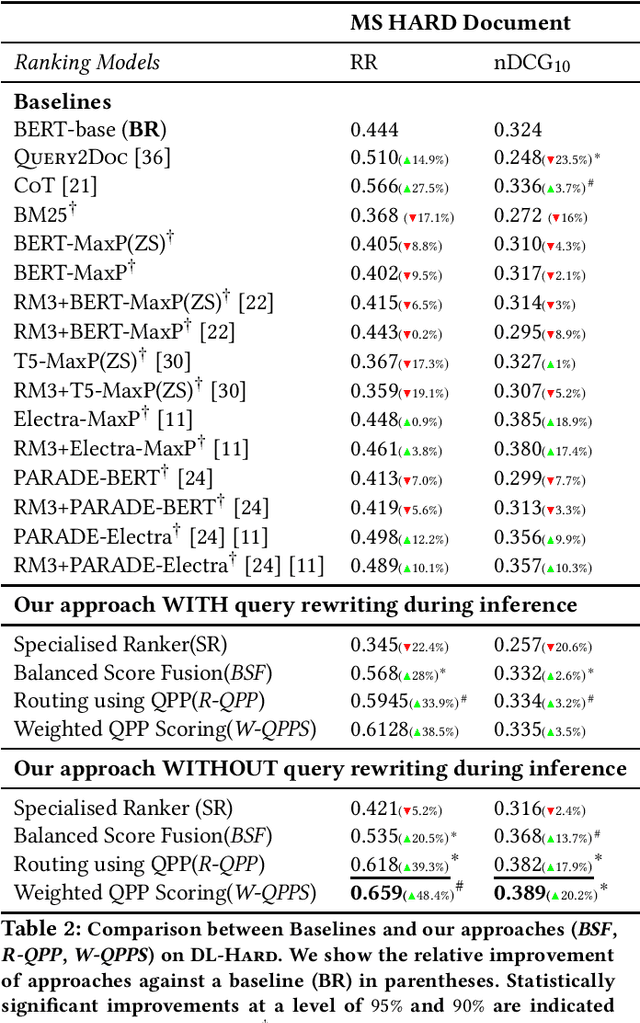
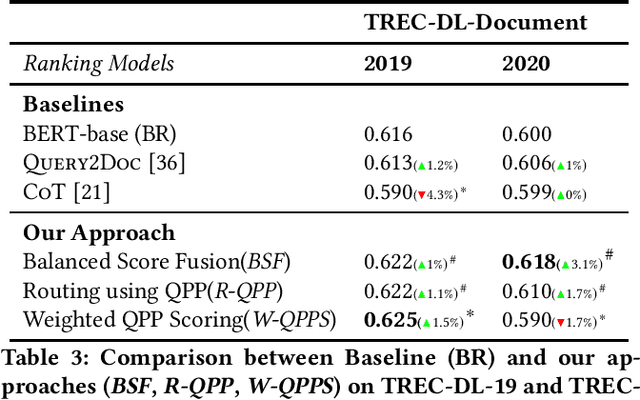
An important problem in text-ranking systems is handling the hard queries that form the tail end of the query distribution. The difficulty may arise due to the presence of uncommon, underspecified, or incomplete queries. In this work, we improve the ranking performance of hard or difficult queries without compromising the performance of other queries. Firstly, we do LLM based query enrichment for training queries using relevant documents. Next, a specialized ranker is fine-tuned only on the enriched hard queries instead of the original queries. We combine the relevance scores from the specialized ranker and the base ranker, along with a query performance score estimated for each query. Our approach departs from existing methods that usually employ a single ranker for all queries, which is biased towards easy queries, which form the majority of the query distribution. In our extensive experiments on the DL-Hard dataset, we find that a principled query performance based scoring method using base and specialized ranker offers a significant improvement of up to 25% on the passage ranking task and up to 48.4% on the document ranking task when compared to the baseline performance of using original queries, even outperforming SOTA model.
NUMTEMP: A real-world benchmark to verify claims with statistical and temporal expressions
Mar 25, 2024
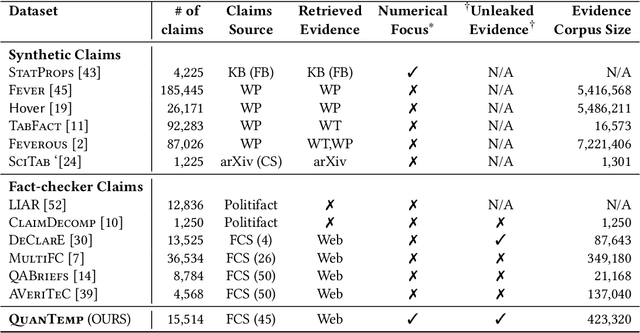
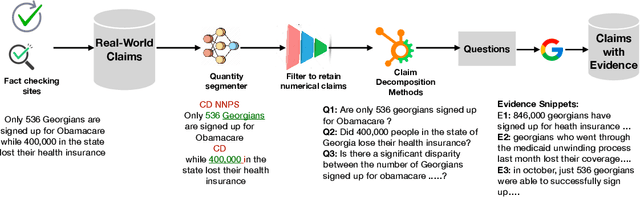
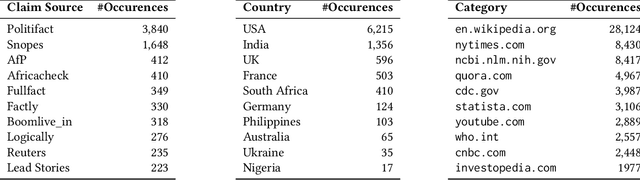
Automated fact checking has gained immense interest to tackle the growing misinformation in the digital era. Existing systems primarily focus on synthetic claims on Wikipedia, and noteworthy progress has also been made on real-world claims. In this work, we release Numtemp, a diverse, multi-domain dataset focused exclusively on numerical claims, encompassing temporal, statistical and diverse aspects with fine-grained metadata and an evidence collection without leakage. This addresses the challenge of verifying real-world numerical claims, which are complex and often lack precise information, not addressed by existing works that mainly focus on synthetic claims. We evaluate and quantify the limitations of existing solutions for the task of verifying numerical claims. We also evaluate claim decomposition based methods, numerical understanding based models and our best baselines achieves a macro-F1 of 58.32. This demonstrates that Numtemp serves as a challenging evaluation set for numerical claim verification.
In-Context Ability Transfer for Question Decomposition in Complex QA
Oct 26, 2023



Answering complex questions is a challenging task that requires question decomposition and multistep reasoning for arriving at the solution. While existing supervised and unsupervised approaches are specialized to a certain task and involve training, recently proposed prompt-based approaches offer generalizable solutions to tackle a wide variety of complex question-answering (QA) tasks. However, existing prompt-based approaches that are effective for complex QA tasks involve expensive hand annotations from experts in the form of rationales and are not generalizable to newer complex QA scenarios and tasks. We propose, icat (In-Context Ability Transfer) which induces reasoning capabilities in LLMs without any LLM fine-tuning or manual annotation of in-context samples. We transfer the ability to decompose complex questions to simpler questions or generate step-by-step rationales to LLMs, by careful selection from available data sources of related tasks. We also propose an automated uncertainty-aware exemplar selection approach for selecting examples from transfer data sources. Finally, we conduct large-scale experiments on a variety of complex QA tasks involving numerical reasoning, compositional complex QA, and heterogeneous complex QA which require decomposed reasoning. We show that ICAT convincingly outperforms existing prompt-based solutions without involving any model training, showcasing the benefits of re-using existing abilities.
Context Aware Query Rewriting for Text Rankers using LLM
Aug 31, 2023
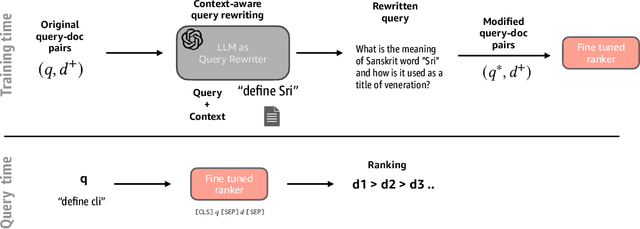


Query rewriting refers to an established family of approaches that are applied to underspecified and ambiguous queries to overcome the vocabulary mismatch problem in document ranking. Queries are typically rewritten during query processing time for better query modelling for the downstream ranker. With the advent of large-language models (LLMs), there have been initial investigations into using generative approaches to generate pseudo documents to tackle this inherent vocabulary gap. In this work, we analyze the utility of LLMs for improved query rewriting for text ranking tasks. We find that there are two inherent limitations of using LLMs as query re-writers -- concept drift when using only queries as prompts and large inference costs during query processing. We adopt a simple, yet surprisingly effective, approach called context aware query rewriting (CAR) to leverage the benefits of LLMs for query understanding. Firstly, we rewrite ambiguous training queries by context-aware prompting of LLMs, where we use only relevant documents as context.Unlike existing approaches, we use LLM-based query rewriting only during the training phase. Eventually, a ranker is fine-tuned on the rewritten queries instead of the original queries during training. In our extensive experiments, we find that fine-tuning a ranker using re-written queries offers a significant improvement of up to 33% on the passage ranking task and up to 28% on the document ranking task when compared to the baseline performance of using original queries.