 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Aware Query Rewriting for Text Rankers using LLM
Paper and Code
Aug 31, 2023
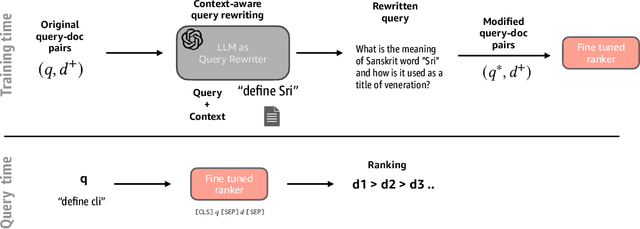


Query rewriting refers to an established family of approaches that are applied to underspecified and ambiguous queries to overcome the vocabulary mismatch problem in document ranking. Queries are typically rewritten during query processing time for better query modelling for the downstream ranker. With the advent of large-language models (LLMs), there have been initial investigations into using generative approaches to generate pseudo documents to tackle this inherent vocabulary gap. In this work, we analyze the utility of LLMs for improved query rewriting for text ranking tasks. We find that there are two inherent limitations of using LLMs as query re-writers -- concept drift when using only queries as prompts and large inference costs during query processing. We adopt a simple, yet surprisingly effective, approach called context aware query rewriting (CAR) to leverage the benefits of LLMs for query understanding. Firstly, we rewrite ambiguous training queries by context-aware prompting of LLMs, where we use only relevant documents as context.Unlike existing approaches, we use LLM-based query rewriting only during the training phase. Eventually, a ranker is fine-tuned on the rewritten queries instead of the original queries during training. In our extensive experiments, we find that fine-tuning a ranker using re-written queries offers a significant improvement of up to 33% on the passage ranking task and up to 28% on the document ranking task when compared to the baseline performance of using original queries.