 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the User: An Intent-Based Ranking Dataset
Aug 30, 2024As information retrieval systems continue to evolve, accurate evaluation and benchmarking of these systems become pivotal. Web search datasets, such as MS MARCO, primarily provide short keyword queries without accompanying intent or descriptions, posing a challenge in comprehending the underlying information need. This paper proposes an approach to augmenting such datasets to annotate informative query descriptions, with a focus on two prominent benchmark datasets: TREC-DL-21 and TREC-DL-22. Our methodology involves utilizing state-of-the-art LLMs to analyze and comprehend the implicit intent within individual queries from benchmark datasets. By extracting key semantic elements, we construct detailed and contextually rich descriptions for these queries. To validate the generated query descriptions, we employ crowdsourcing as a reliable means of obtaining diverse human perspectives on the accuracy and informativeness of the descriptions. This information can be used as an evaluation set for tasks such as ranking, query rewriting, or others.
The Surprising Effectiveness of Rankers Trained on Expanded Queries
Apr 03, 2024
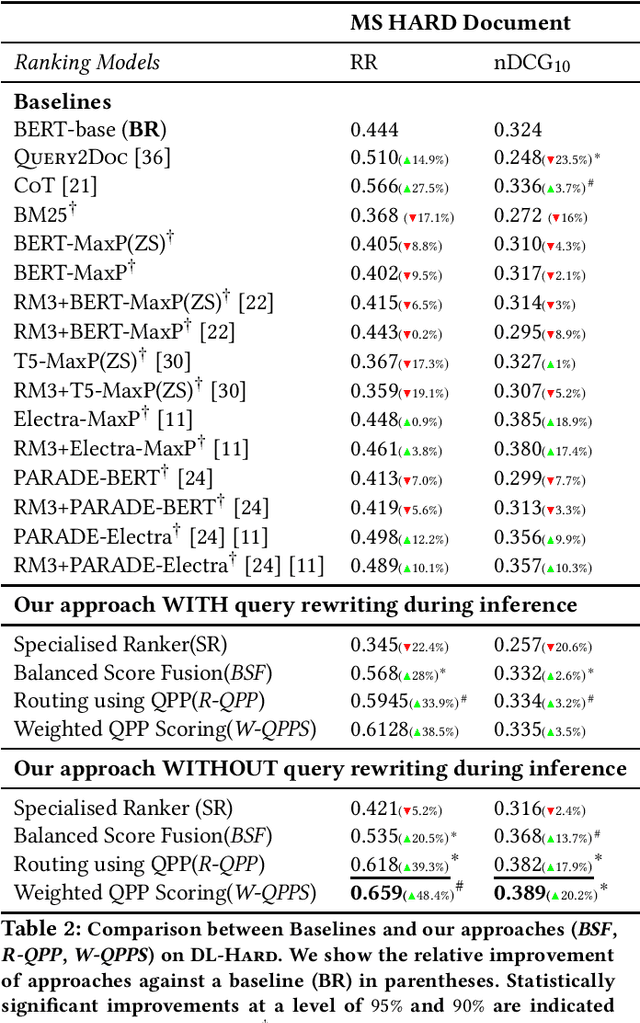
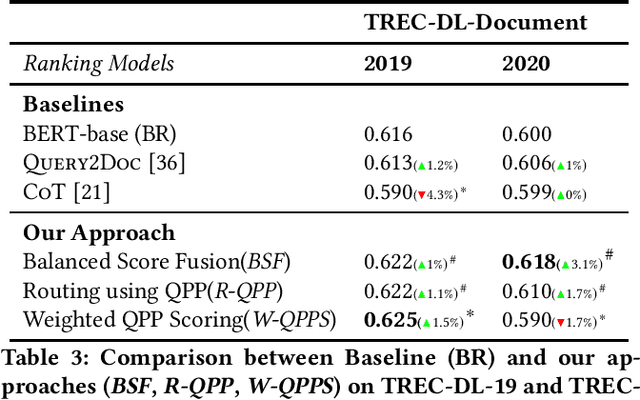
An important problem in text-ranking systems is handling the hard queries that form the tail end of the query distribution. The difficulty may arise due to the presence of uncommon, underspecified, or incomplete queries. In this work, we improve the ranking performance of hard or difficult queries without compromising the performance of other queries. Firstly, we do LLM based query enrichment for training queries using relevant documents. Next, a specialized ranker is fine-tuned only on the enriched hard queries instead of the original queries. We combine the relevance scores from the specialized ranker and the base ranker, along with a query performance score estimated for each query. Our approach departs from existing methods that usually employ a single ranker for all queries, which is biased towards easy queries, which form the majority of the query distribution. In our extensive experiments on the DL-Hard dataset, we find that a principled query performance based scoring method using base and specialized ranker offers a significant improvement of up to 25% on the passage ranking task and up to 48.4% on the document ranking task when compared to the baseline performance of using original queries, even outperforming SOTA model.
NUMTEMP: A real-world benchmark to verify claims with statistical and temporal expressions
Mar 25, 2024
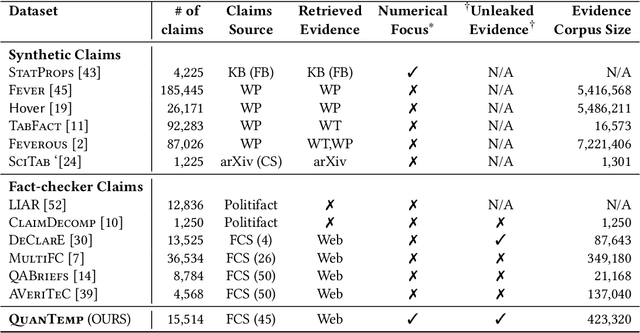
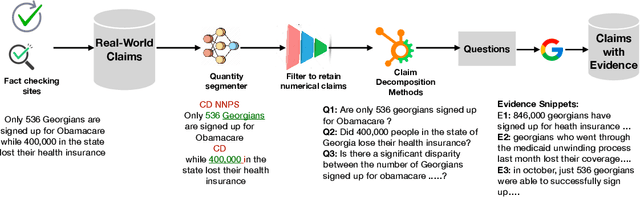
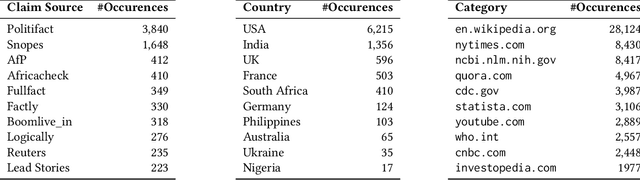
Automated fact checking has gained immense interest to tackle the growing misinformation in the digital era. Existing systems primarily focus on synthetic claims on Wikipedia, and noteworthy progress has also been made on real-world claims. In this work, we release Numtemp, a diverse, multi-domain dataset focused exclusively on numerical claims, encompassing temporal, statistical and diverse aspects with fine-grained metadata and an evidence collection without leakage. This addresses the challenge of verifying real-world numerical claims, which are complex and often lack precise information, not addressed by existing works that mainly focus on synthetic claims. We evaluate and quantify the limitations of existing solutions for the task of verifying numerical claims. We also evaluate claim decomposition based methods, numerical understanding based models and our best baselines achieves a macro-F1 of 58.32. This demonstrates that Numtemp serves as a challenging evaluation set for numerical claim verification.
Data Augmentation for Sample Efficient and Robust Document Ranking
Nov 26, 2023Contextual ranking models have delivered impressive performance improvements over classical models in the document ranking task. However, these highly over-parameterized models tend to be data-hungry and require large amounts of data even for fine-tuning. In this paper, we propose data-augmentation methods for effective and robust ranking performance. One of the key benefits of using data augmentation is in achieving sample efficiency or learning effectively when we have only a small amount of training data. We propose supervised and unsupervised data augmentation schemes by creating training data using parts of the relevant documents in the query-document pairs. We then adapt a family of contrastive losses for the document ranking task that can exploit the augmented data to learn an effective ranking model. Our extensive experiments on subsets of the MS MARCO and TREC-DL test sets show that data augmentation, along with the ranking-adapted contrastive losses, results in performance improvements under most dataset sizes. Apart from sample efficiency, we conclusively show that data augmentation results in robust models when transferred to out-of-domain benchmarks. Our performance improvements in in-domain and more prominently in out-of-domain benchmarks show that augmentation regularizes the ranking model and improves its robustness and generalization capability.
Efficient Neural Ranking using Forward Indexes and Lightweight Encoders
Nov 02, 2023Dual-encoder-based dense retrieval models have become the standard in IR. They employ large Transformer-based language models, which are notoriously inefficient in terms of resources and latency. We propose Fast-Forward indexes -- vector forward indexes which exploit the semantic matching capabilities of dual-encoder models for efficient and effective re-ranking. Our framework enables re-ranking at very high retrieval depths and combines the merits of both lexical and semantic matching via score interpolation. Furthermore, in order to mitigate the limitations of dual-encoders, we tackle two main challenges: Firstly, we improve computational efficiency by either pre-computing representations, avoiding unnecessary computations altogether, or reducing the complexity of encoders. This allows us to considerably improve ranking efficiency and latency. Secondly, we optimize the memory footprint and maintenance cost of indexes; we propose two complementary techniques to reduce the index size and show that, by dynamically dropping irrelevant document tokens, the index maintenance efficiency can be improved substantially. We perform evaluation to show the effectiveness and efficiency of Fast-Forward indexes -- our method has low latency and achieves competitive results without the need for hardware acceleration, such as GPUs.
Context Aware Query Rewriting for Text Rankers using LLM
Aug 31, 2023
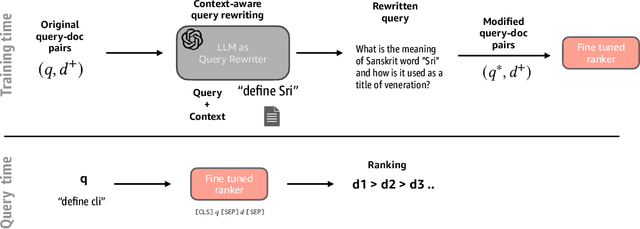


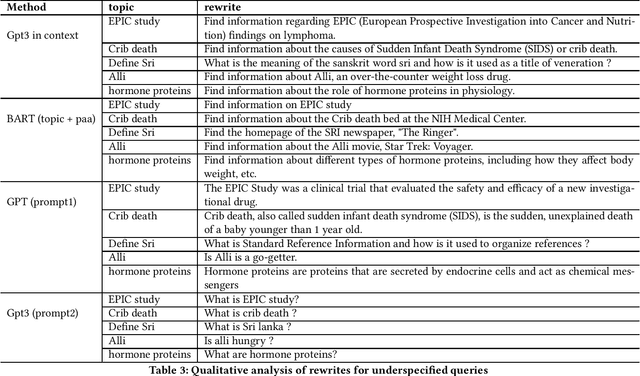
Query rewriting refers to an established family of approaches that are applied to underspecified and ambiguous queries to overcome the vocabulary mismatch problem in document ranking. Queries are typically rewritten during query processing time for better query modelling for the downstream ranker. With the advent of large-language models (LLMs), there have been initial investigations into using generative approaches to generate pseudo documents to tackle this inherent vocabulary gap. In this work, we analyze the utility of LLMs for improved query rewriting for text ranking tasks. We find that there are two inherent limitations of using LLMs as query re-writers -- concept drift when using only queries as prompts and large inference costs during query processing. We adopt a simple, yet surprisingly effective, approach called context aware query rewriting (CAR) to leverage the benefits of LLMs for query understanding. Firstly, we rewrite ambiguous training queries by context-aware prompting of LLMs, where we use only relevant documents as context.Unlike existing approaches, we use LLM-based query rewriting only during the training phase. Eventually, a ranker is fine-tuned on the rewritten queries instead of the original queries during training. In our extensive experiments, we find that fine-tuning a ranker using re-written queries offers a significant improvement of up to 33% on the passage ranking task and up to 28% on the document ranking task when compared to the baseline performance of using original queries.
Query Understanding in the Age of Large Language Models
Jun 28, 2023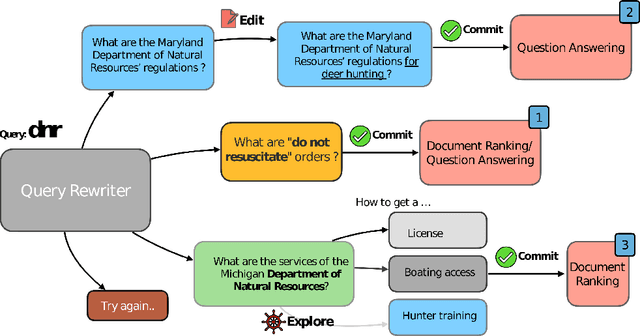
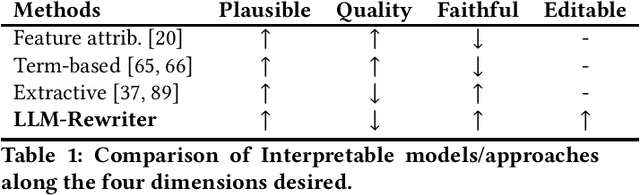

Querying, conversing, and controlling search and information-seeking interfaces using natural language are fast becoming ubiquitous with the rise and adoption of large-language models (LLM). In this position paper, we describe a generic framework for interactive query-rewriting using LLMs. Our proposal aims to unfold new opportunities for improved and transparent intent understanding while building high-performance retrieval systems using LLMs. A key aspect of our framework is the ability of the rewriter to fully specify the machine intent by the search engine in natural language that can be further refined, controlled, and edited before the final retrieval phase. The ability to present, interact, and reason over the underlying machine intent in natural language has profound implications on transparency, ranking performance, and a departure from the traditional way in which supervised signals were collected for understanding intents. We detail the concept, backed by initial experiments, along with open questions for this interactive query understanding framework.
Supervised Contrastive Learning Approach for Contextual Ranking
Jul 07, 2022
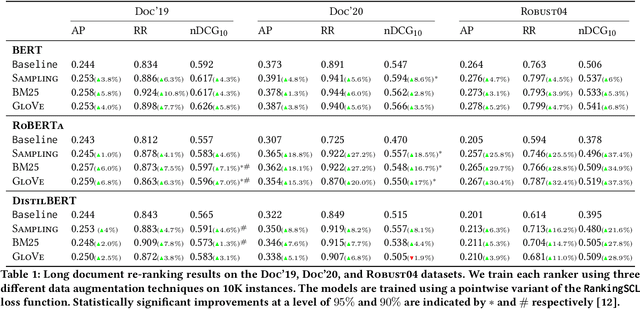
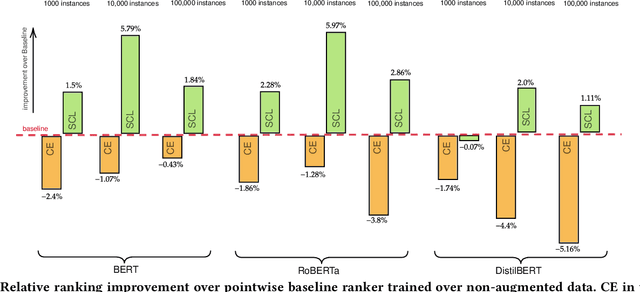
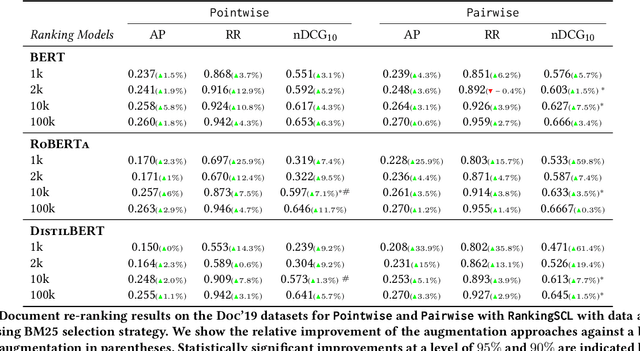
Contextual ranking models have delivered impressive performance improvements over classical models in the document ranking task. However, these highly over-parameterized models tend to be data-hungry and require large amounts of data even for fine tuning. This paper proposes a simple yet effective method to improve ranking performance on smaller datasets using supervised contrastive learning for the document ranking problem. We perform data augmentation by creating training data using parts of the relevant documents in the query-document pairs. We then use a supervised contrastive learning objective to learn an effective ranking model from the augmented dataset. Our experiments on subsets of the TREC-DL dataset show that, although data augmentation leads to an increasing the training data sizes, it does not necessarily improve the performance using existing pointwise or pairwise training objectives. However, our proposed supervised contrastive loss objective leads to performance improvements over the standard non-augmented setting showcasing the utility of data augmentation using contrastive losses. Finally, we show the real benefit of using supervised contrastive learning objectives by showing marked improvements in smaller ranking datasets relating to news (Robust04), finance (FiQA), and scientific fact checking (SciFact).
Fast Forward Indexes for Efficient Document Ranking
Oct 12, 2021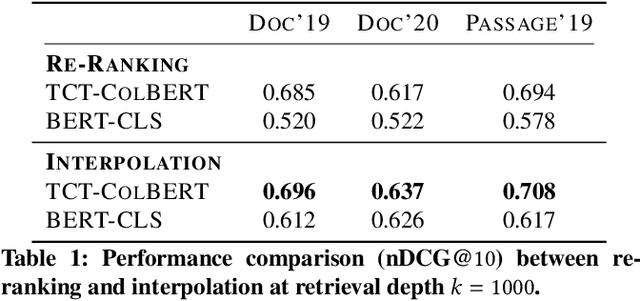

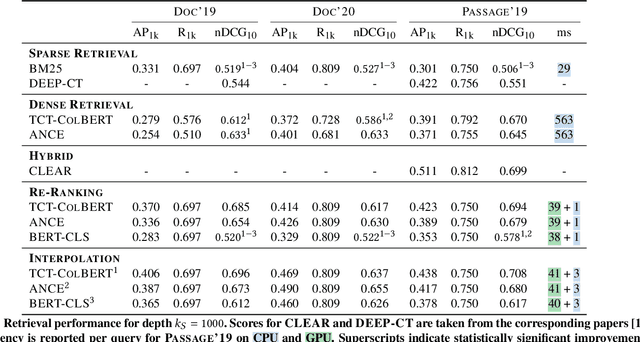
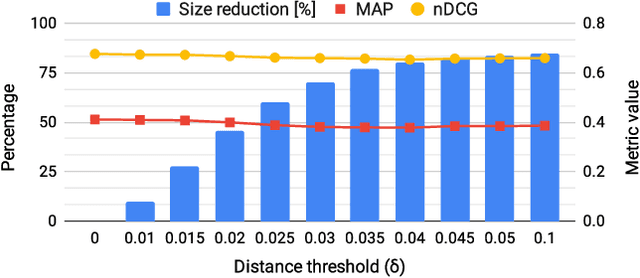
Neural approaches, specifically transformer models, for ranking documents have delivered impressive gains in ranking performance. However, query processing using such over-parameterized models is both resource and time intensive. Consequently, to keep query processing costs manageable, trade-offs are made to reduce the number of documents to be re-ranked or consider leaner models with fewer parameters. In this paper, we propose the fast-forward index -- a simple vector forward index that facilitates ranking documents using interpolation-based ranking models. Fast-forward indexes pre-compute the dense transformer-based vector representations of documents and passages for fast CPU-based semantic similarity computation during query processing. We propose theoretically grounded index pruning and early stopping techniques to improve the query-processing throughput using fast-forward indexes. We conduct extensive large-scale experiments over the TREC-DL datasets and show up to 75% improvement in query-processing performance over hybrid indexes using only CPUs. Along with the efficiency benefits, we show that fast-forward indexes can deliver superior ranking performance due to the complementary benefits of interpolation between lexical and semantic similarities.