 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Student Perception on Gen AI Adoption in Higher Education: A Descriptive Study
Mar 29, 2026The rapid proliferation of Generative Artificial Intelligence (GenAI) is reshaping pedagogical practices and assessment models in higher education. While institutional and educator perspectives on GenAI integration are increasingly documented, the student perspective remains comparatively underexplored. This study examines how students perceive, use, and evaluate GenAI within their academic practices, focusing on usage patterns, perceived benefits, and expectations for institutional support. Data were collected through a questionnaire administered to 436 postgraduate Computer Science students at the University of Hertfordshire and analysed using descriptive methods. The findings reveal a Confidence-Competence Paradox: although more than 60% of students report high familiarity with tools such as ChatGPT, daily academic use remains limited and confidence in effective application is only moderate. Students primarily employ GenAI for cognitive scaffolding tasks, including concept clarification and brainstorming, rather than fully automated content generation. At the same time, respondents express concerns regarding data privacy, reliability of AI-generated information, and the potential erosion of critical thinking skills. The results also indicate strong student support for integrating AI literacy into curricula and programme Knowledge, Skills, and Behaviours (KSBs). Overall, the study suggests that universities should move beyond a policing approach to GenAI and adopt a pedagogical framework that emphasises AI literacy, ethical guidance, and equitable access to AI tools.
Accurate Shift Invariant Convolutional Neural Networks Using Gaussian-Hermite Moments
Mar 17, 2026The convolutional neural networks (CNNs) are not inherently shift invariant or equivariant. The downsampling operation, used in CNNs, is one of the key reasons which breaks the shift invariant property of a CNN. Conversely, downsampling operation is important to improve computational efficiency and increase the area of the receptive field for more contextual information. In this work, we propose Gaussian-Hermite Sampling (GHS), a novel downsampling strategy designed to achieve accurate shift invariance. GHS leverages Gaussian-Hermite polynomials to perform shift-consistent sampling, enabling CNN layers to maintain invariance to arbitrary spatial shifts prior to training. When integrated into standard CNN architectures, the proposed method embeds shift invariance directly at the layer level without requiring architectural modifications or additional training procedures. We evaluate the proposed approach on CIFAR-10, CIFAR-100, and MNIST-rot datasets. Experimental results demonstrate that GHS significantly improves shift consistency, achieving 100% classification consistency under spatial shifts, while also improving classification accuracy compared to baseline CNN models.
Interpretable Multimodal Gesture Recognition for Drone and Mobile Robot Teleoperation via Log-Likelihood Ratio Fusion
Mar 05, 2026Human operators are still frequently exposed to hazardous environments such as disaster zones and industrial facilities, where intuitive and reliable teleoperation of mobile robots and Unmanned Aerial Vehicles (UAVs) is essential. In this context, hands-free teleoperation enhances operator mobility and situational awareness, thereby improving safety in hazardous environments. While vision-based gesture recognition has been explored as one method for hands-free teleoperation, its performance often deteriorates under occlusions, lighting variations, and cluttered backgrounds, limiting its applicability in real-world operations. To overcome these limitations, we propose a multimodal gesture recognition framework that integrates inertial data (accelerometer, gyroscope, and orientation) from Apple Watches on both wrists with capacitive sensing signals from custom gloves. We design a late fusion strategy based on the log-likelihood ratio (LLR), which not only enhances recognition performance but also provides interpretability by quantifying modality-specific contributions. To support this research, we introduce a new dataset of 20 distinct gestures inspired by aircraft marshalling signals, comprising synchronized RGB video, IMU, and capacitive sensor data. Experimental results demonstrate that our framework achieves performance comparable to a state-of-the-art vision-based baseline while significantly reducing computational cost, model size, and training time, making it well suited for real-time robot control. We therefore underscore the potential of sensor-based multimodal fusion as a robust and interpretable solution for gesture-driven mobile robot and drone teleoperation.
Exploring the Effect of Robotic Embodiment and Empathetic Tone of LLMs on Empathy Elicitation
Mar 26, 2025This study investigates the elicitation of empathy toward a third party through interaction with social agents. Participants engaged with either a physical robot or a voice-enabled chatbot, both driven by a large language model (LLM) programmed to exhibit either an empathetic tone or remain neutral. The interaction is focused on a fictional character, Katie Banks, who is in a challenging situation and in need of financial donations. The willingness to help Katie, measured by the number of hours participants were willing to volunteer, along with their perceptions of the agent, were assessed for 60 participants. Results indicate that neither robotic embodiment nor empathetic tone significantly influenced participants' willingness to volunteer. While the LLM effectively simulated human empathy, fostering genuine empathetic responses in participants proved challenging.
* *Liza Darwesh, Jaspreet Singh, Marin Marian, and Eduard Alexa contributed equally to this work.*
Data Augmentation for Sample Efficient and Robust Document Ranking
Nov 26, 2023Contextual ranking models have delivered impressive performance improvements over classical models in the document ranking task. However, these highly over-parameterized models tend to be data-hungry and require large amounts of data even for fine-tuning. In this paper, we propose data-augmentation methods for effective and robust ranking performance. One of the key benefits of using data augmentation is in achieving sample efficiency or learning effectively when we have only a small amount of training data. We propose supervised and unsupervised data augmentation schemes by creating training data using parts of the relevant documents in the query-document pairs. We then adapt a family of contrastive losses for the document ranking task that can exploit the augmented data to learn an effective ranking model. Our extensive experiments on subsets of the MS MARCO and TREC-DL test sets show that data augmentation, along with the ranking-adapted contrastive losses, results in performance improvements under most dataset sizes. Apart from sample efficiency, we conclusively show that data augmentation results in robust models when transferred to out-of-domain benchmarks. Our performance improvements in in-domain and more prominently in out-of-domain benchmarks show that augmentation regularizes the ranking model and improves its robustness and generalization capability.
Earthquake Magnitude and b value prediction model using Extreme Learning Machine
Jan 23, 2023



Earthquake prediction has been a challenging research area for many decades, where the future occurrence of this highly uncertain calamity is predicted. In this paper, several parametric and non-parametric features were calculated, where the non-parametric features were calculated using the parametric features. $8$ seismic features were calculated using Gutenberg-Richter law, the total recurrence, and the seismic energy release. Additionally, criterions such as Maximum Relevance and Maximum Redundancy were applied to choose the pertinent features. These features along with others were used as input for an Extreme Learning Machine (ELM) Regression Model. Magnitude and time data of $5$ decades from the Assam-Guwahati region were used to create this model for magnitude prediction. The Testing Accuracy and Testing Speed were computed taking the Root Mean Squared Error (RMSE) as the parameter for evaluating the mode. As confirmed by the results, ELM shows better scalability with much faster training and testing speed (up to a thousand times faster) than traditional Support Vector Machines. The testing RMSE came out to be around $0.097$. To further test the model's robustness -- magnitude-time data from California was used to calculate the seismic indicators which were then fed into an ELM and then tested on the Assam-Guwahati region. The model proves to be robust and can be implemented in early warning systems as it continues to be a major part of Disaster Response and management.
Learning Invariant Representations for Equivariant Neural Networks Using Orthogonal Moments
Sep 22, 2022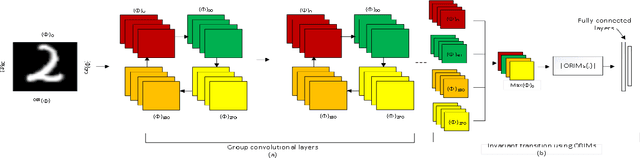
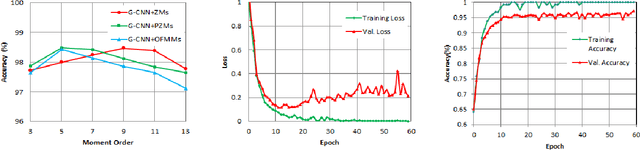


The convolutional layers of standard convolutional neural networks (CNNs) are equivariant to translation. However, the convolution and fully-connected layers are not equivariant or invariant to other affine geometric transformations. Recently, a new class of CNNs is proposed in which the conventional layers of CNNs are replaced with equivariant convolution, pooling, and batch-normalization layers. The final classification layer in equivariant neural networks is invariant to different affine geometric transformations such as rotation, reflection and translation, and the scalar value is obtained by either eliminating the spatial dimensions of filter responses using convolution and down-sampling throughout the network or average is taken over the filter responses. In this work, we propose to integrate the orthogonal moments which gives the high-order statistics of the function as an effective means for encoding global invariance with respect to rotation, reflection and translation in fully-connected layers. As a result, the intermediate layers of the network become equivariant while the classification layer becomes invariant. The most widely used Zernike, pseudo-Zernike and orthogonal Fourier-Mellin moments are considered for this purpose. The effectiveness of the proposed work is evaluated by integrating the invariant transition and fully-connected layer in the architecture of group-equivariant CNNs (G-CNNs) on rotated MNIST and CIFAR10 datasets.
Towards Axiomatic Explanations for Neural Ranking Models
Jul 11, 2021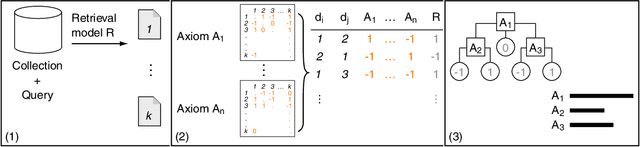
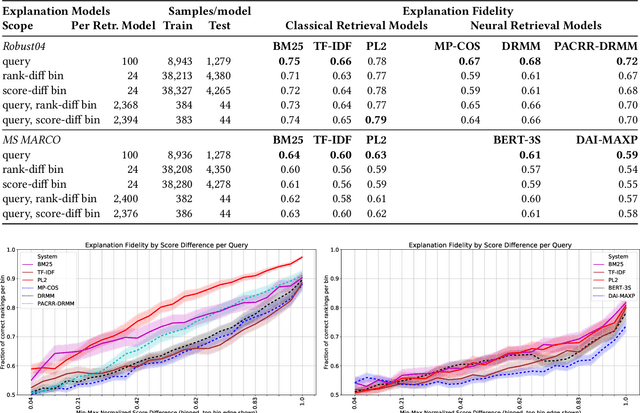
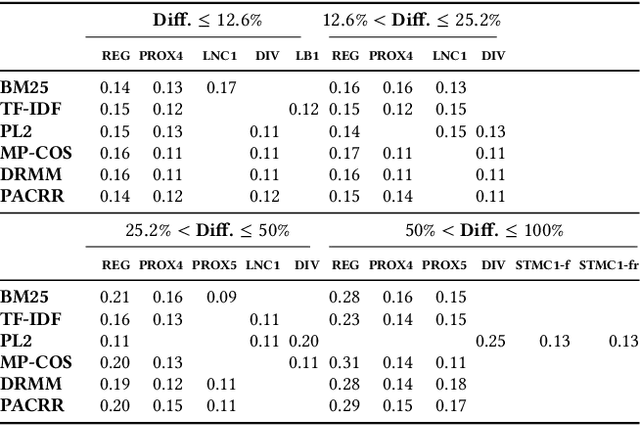
Recently, neural networks have been successfully employed to improve upon state-of-the-art performance in ad-hoc retrieval tasks via machine-learned ranking functions. While neural retrieval models grow in complexity and impact, little is understood about their correspondence with well-studied IR principles. Recent work on interpretability in machine learning has provided tools and techniques to understand neural models in general, yet there has been little progress towards explaining ranking models. We investigate whether one can explain the behavior of neural ranking models in terms of their congruence with well understood principles of document ranking by using established theories from axiomatic IR. Axiomatic analysis of information retrieval models has formalized a set of constraints on ranking decisions that reasonable retrieval models should fulfill. We operationalize this axiomatic thinking to reproduce rankings based on combinations of elementary constraints. This allows us to investigate to what extent the ranking decisions of neural rankers can be explained in terms of retrieval axioms, and which axioms apply in which situations. Our experimental study considers a comprehensive set of axioms over several representative neural rankers. While the existing axioms can already explain the particularly confident ranking decisions rather well, future work should extend the axiom set to also cover the other still "unexplainable" neural IR rank decisions.
BERTnesia: Investigating the capture and forgetting of knowledge in BERT
Jun 05, 2021
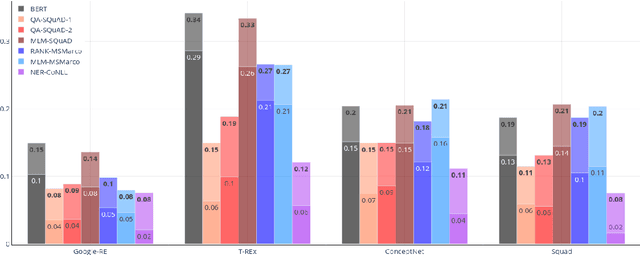
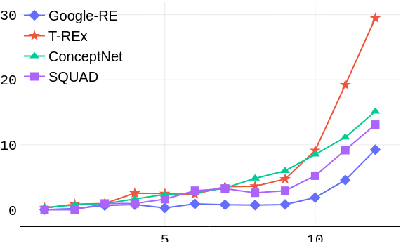
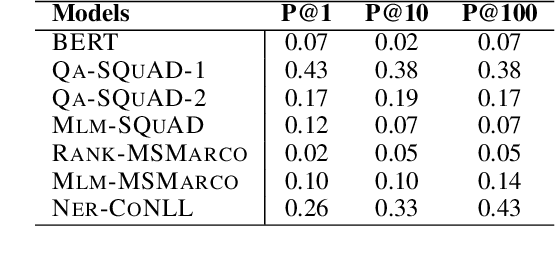
Probing complex language models has recently revealed several insights into linguistic and semantic patterns found in the learned representations. In this article, we probe BERT specifically to understand and measure the relational knowledge it captures in its parametric memory. While probing for linguistic understanding is commonly applied to all layers of BERT as well as fine-tuned models, this has not been done for factual knowledge. We utilize existing knowledge base completion tasks (LAMA) to probe every layer of pre-trained as well as fine-tuned BERT models(ranking, question answering, NER). Our findings show that knowledge is not just contained in BERT's final layers. Intermediate layers contribute a significant amount (17-60%) to the total knowledge found. Probing intermediate layers also reveals how different types of knowledge emerge at varying rates. When BERT is fine-tuned, relational knowledge is forgotten. The extent of forgetting is impacted by the fine-tuning objective and the training data. We found that ranking models forget the least and retain more knowledge in their final layer compared to masked language modeling and question-answering. However, masked language modeling performed the best at acquiring new knowledge from the training data. When it comes to learning facts, we found that capacity and fact density are key factors. We hope this initial work will spur further research into understanding the parametric memory of language models and the effect of training objectives on factual knowledge. The code to repeat the experiments is publicly available on GitHub.
Dissonance Between Human and Machine Understanding
Jan 18, 2021
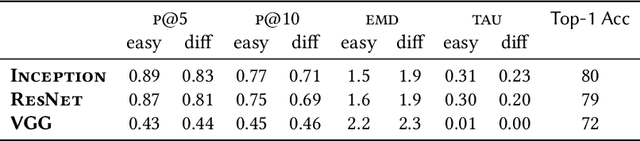
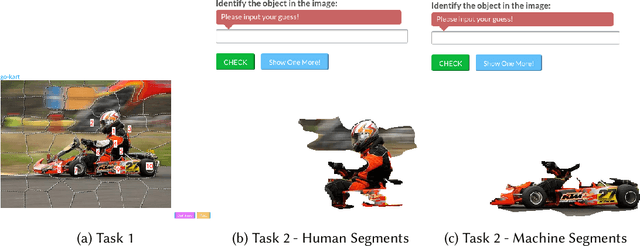
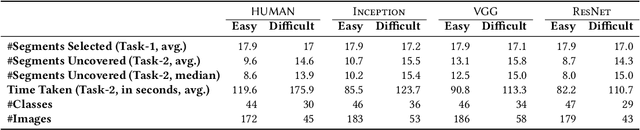
Complex machine learning models are deployed in several critical domains including healthcare and autonomous vehicles nowadays, albeit as functional black boxes. Consequently, there has been a recent surge in interpreting decisions of such complex models in order to explain their actions to humans. Models that correspond to human interpretation of a task are more desirable in certain contexts and can help attribute liability, build trust, expose biases and in turn build better models. It is, therefore, crucial to understand how and which models conform to human understanding of tasks. In this paper, we present a large-scale crowdsourcing study that reveals and quantifies the dissonance between human and machine understanding, through the lens of an image classification task. In particular, we seek to answer the following questions: Which (well-performing) complex ML models are closer to humans in their use of features to make accurate predictions? How does task difficulty affect the feature selection capability of machines in comparison to humans? Are humans consistently better at selecting features that make image recognition more accurate? Our findings have important implications on human-machine collaboration, considering that a long term goal in the field of artificial intelligence is to make machines capable of learning and reasoning like humans.
* 23 pages, 5 figures