 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Dense Passage Retrieval with Temporal Information
Feb 28, 2025Temporal awareness is crucial in many information retrieval tasks, particularly in scenarios where the relevance of documents depends on their alignment with the query's temporal context. Traditional retrieval methods such as BM25 and Dense Passage Retrieval (DPR) excel at capturing lexical and semantic relevance but fall short in addressing time-sensitive queries. To bridge this gap, we introduce the temporal retrieval model that integrates explicit temporal signals by incorporating query timestamps and document dates into the representation space. Our approach ensures that retrieved passages are not only topically relevant but also temporally aligned with user intent. We evaluate our approach on two large-scale benchmark datasets, ArchivalQA and ChroniclingAmericaQA, achieving substantial performance gains over standard retrieval baselines. In particular, our model improves Top-1 retrieval accuracy by 6.63% and NDCG@10 by 3.79% on ArchivalQA, while yielding a 9.56% boost in Top-1 retrieval accuracy and 4.68% in NDCG@10 on ChroniclingAmericaQA. Additionally, we introduce a time-sensitive negative sampling strategy, which refines the model's ability to distinguish between temporally relevant and irrelevant documents during training. Our findings highlight the importance of explicitly modeling time in retrieval systems and set a new standard for handling temporally grounded queries.
Correctness is not Faithfulness in RAG Attributions
Dec 23, 2024Retrieving relevant context is a common approach to reduce hallucinations and enhance answer reliability. Explicitly citing source documents allows users to verify generated responses and increases trust. Prior work largely evaluates citation correctness - whether cited documents support the corresponding statements. But citation correctness alone is insufficient. To establish trust in attributed answers, we must examine both citation correctness and citation faithfulness. In this work, we first disentangle the notions of citation correctness and faithfulness, which have been applied inconsistently in previous studies. Faithfulness ensures that the model's reliance on cited documents is genuine, reflecting actual reference use rather than superficial alignment with prior beliefs, which we call post-rationalization. We design an experiment that reveals the prevalent issue of post-rationalization, which undermines reliable attribution and may result in misplaced trust. Our findings suggest that current attributed answers often lack citation faithfulness (up to 57 percent of the citations), highlighting the need to evaluate correctness and faithfulness for trustworthy attribution in language models.
Temporal Blind Spots in Large Language Models
Jan 22, 2024Large language models (LLMs) have recently gained significant attention due to their unparalleled ability to perform various natural language processing tasks. These models, benefiting from their advanced natural language understanding capabilities, have demonstrated impressive zero-shot performance. However, the pre-training data utilized in LLMs is often confined to a specific corpus, resulting in inherent freshness and temporal scope limitations. Consequently, this raises concerns regarding the effectiveness of LLMs for tasks involving temporal intents. In this study, we aim to investigate the underlying limitations of general-purpose LLMs when deployed for tasks that require a temporal understanding. We pay particular attention to handling factual temporal knowledge through three popular temporal QA datasets. Specifically, we observe low performance on detailed questions about the past and, surprisingly, for rather new information. In manual and automatic testing, we find multiple temporal errors and characterize the conditions under which QA performance deteriorates. Our analysis contributes to understanding LLM limitations and offers valuable insights into developing future models that can better cater to the demands of temporally-oriented tasks. The code is available\footnote{https://github.com/jwallat/temporalblindspots}.
GeneMask: Fast Pretraining of Gene Sequences to Enable Few-Shot Learning
Jul 29, 2023Large-scale language models such as DNABert and LOGO aim to learn optimal gene representations and are trained on the entire Human Reference Genome. However, standard tokenization schemes involve a simple sliding window of tokens like k-mers that do not leverage any gene-based semantics and thus may lead to (trivial) masking of easily predictable sequences and subsequently inefficient Masked Language Modeling (MLM) training. Therefore, we propose a novel masking algorithm, GeneMask, for MLM training of gene sequences, where we randomly identify positions in a gene sequence as mask centers and locally select the span around the mask center with the highest Normalized Pointwise Mutual Information (NPMI) to mask. We observe that in the absence of human-understandable semantics in the genomics domain (in contrast, semantic units like words and phrases are inherently available in NLP), GeneMask-based models substantially outperform the SOTA models (DNABert and LOGO) over four benchmark gene sequence classification datasets in five few-shot settings (10 to 1000-shot). More significantly, the GeneMask-based DNABert model is trained for less than one-tenth of the number of epochs of the original SOTA model. We also observe a strong correlation between top-ranked PMI tokens and conserved DNA sequence motifs, which may indicate the incorporation of latent genomic information. The codes (including trained models) and datasets are made publicly available at https://github.com/roysoumya/GeneMask.
The Effect of Masking Strategies on Knowledge Retention by Language Models
Jun 12, 2023



Language models retain a significant amount of world knowledge from their pre-training stage. This allows knowledgeable models to be applied to knowledge-intensive tasks prevalent in information retrieval, such as ranking or question answering. Understanding how and which factual information is acquired by our models is necessary to build responsible models. However, limited work has been done to understand the effect of pre-training tasks on the amount of knowledge captured and forgotten by language models during pre-training. Building a better understanding of knowledge acquisition is the goal of this paper. Therefore, we utilize a selection of pre-training tasks to infuse knowledge into our model. In the following steps, we test the model's knowledge retention by measuring its ability to answer factual questions. Our experiments show that masking entities and principled masking of correlated spans based on pointwise mutual information lead to more factual knowledge being retained than masking random tokens. Our findings demonstrate that, like the ability to perform a task, the (factual) knowledge acquired from being trained on that task is forgotten when a model is trained to perform another task (catastrophic forgetting) and how to prevent this phenomenon. To foster reproducibility, the code, as well as the data used in this paper, are openly available.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023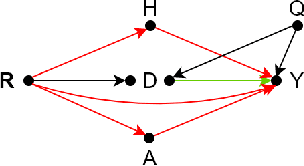
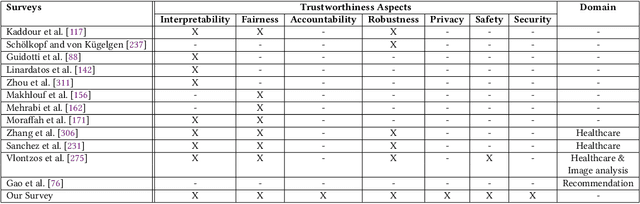
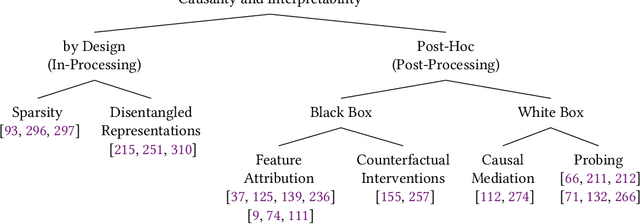
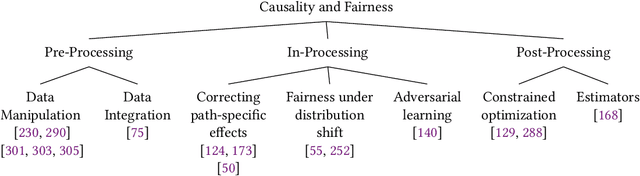
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.
Explainable Information Retrieval: A Survey
Nov 04, 2022Explainable information retrieval is an emerging research area aiming to make transparent and trustworthy information retrieval systems. Given the increasing use of complex machine learning models in search systems, explainability is essential in building and auditing responsible information retrieval models. This survey fills a vital gap in the otherwise topically diverse literature of explainable information retrieval. It categorizes and discusses recent explainability methods developed for different application domains in information retrieval, providing a common framework and unifying perspectives. In addition, it reflects on the common concern of evaluating explanations and highlights open challenges and opportunities.
BERTnesia: Investigating the capture and forgetting of knowledge in BERT
Jun 05, 2021
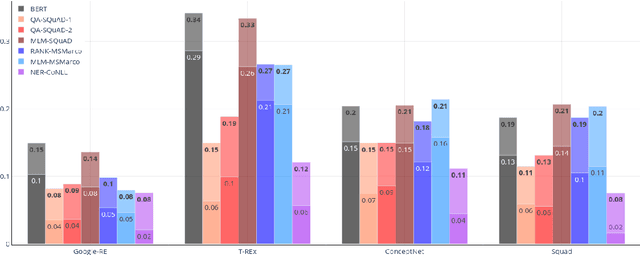
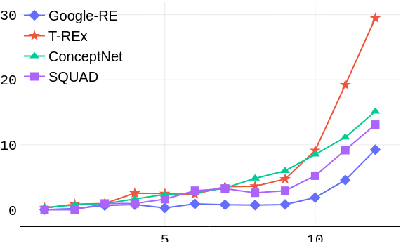
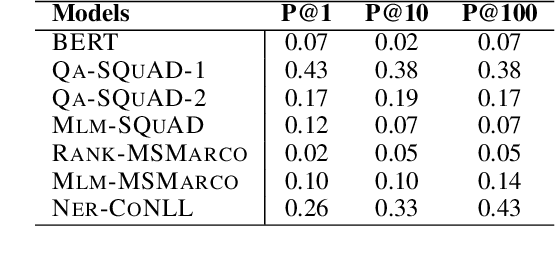
Probing complex language models has recently revealed several insights into linguistic and semantic patterns found in the learned representations. In this article, we probe BERT specifically to understand and measure the relational knowledge it captures in its parametric memory. While probing for linguistic understanding is commonly applied to all layers of BERT as well as fine-tuned models, this has not been done for factual knowledge. We utilize existing knowledge base completion tasks (LAMA) to probe every layer of pre-trained as well as fine-tuned BERT models(ranking, question answering, NER). Our findings show that knowledge is not just contained in BERT's final layers. Intermediate layers contribute a significant amount (17-60%) to the total knowledge found. Probing intermediate layers also reveals how different types of knowledge emerge at varying rates. When BERT is fine-tuned, relational knowledge is forgotten. The extent of forgetting is impacted by the fine-tuning objective and the training data. We found that ranking models forget the least and retain more knowledge in their final layer compared to masked language modeling and question-answering. However, masked language modeling performed the best at acquiring new knowledge from the training data. When it comes to learning facts, we found that capacity and fact density are key factors. We hope this initial work will spur further research into understanding the parametric memory of language models and the effect of training objectives on factual knowledge. The code to repeat the experiments is publicly available on GitHub.