 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
Jun 04, 2026Planning for real-world problems by language models often involves both world and user constraints, which may not be fully specified upfront and are progressively disclosed through interaction. However, existing benchmarks still underexplore adaptive planning under such progressively revealed dual constraints. To address this gap, we introduce AdaPlanBench, a dynamic interactive benchmark for evaluating whether Large Language Model (LLM) agents can adaptively plan and re-plan under progressively revealed world and user constraints. AdaPlanBench is built on 307 household tasks, with a scalable constraint construction pipeline that augments each task with dual constraints. At runtime, agents interact with the environment in a multi-turn protocol where hidden constraints are revealed only when the agent proposes a plan that violates them, requiring iterative plan revision under accumulating feedback. This makes planning challenging, as agents must infer and track constraints from feedback while re-planning effectively. Experiments on ten leading LLMs show that adaptive planning under dual constraints remains challenging, with the best model reaching only 67.75% accuracy. We further observe that performance degrades as more constraints accumulate, with user constraints posing a particularly large challenge and failures often stemming from weaker physical grounding and reduced effectiveness. These results establish AdaPlanBench as a testbed for dual-constrained interactive planning and highlight the challenge of reliable adaptation to dynamically revealed constraints in LLM agents.
KnowledgeBerg: Evaluating Systematic Knowledge Coverage and Compositional Reasoning in Large Language Models
Apr 19, 2026Many real-world questions appear deceptively simple yet implicitly demand two capabilities: (i) systematic coverage of a bounded knowledge universe and (ii) compositional set-based reasoning over that universe, a phenomenon we term "the tip of the iceberg." We formalize this challenge through two orthogonal dimensions: knowledge width, the cardinality of the required universe, and reasoning depth, the number of compositional set operations. We introduce KnowledgeBerg, a benchmark of 4,800 multiple-choice questions derived from 1,183 enumeration seeds spanning 10 domains and 17 languages, with universes grounded in authoritative sources to ensure reproducibility. Representative open-source LLMs demonstrate severe limitations, achieving only 5.26-36.88 F1 on universe enumeration and 16.00-44.19 accuracy on knowledge-grounded reasoning. Diagnostic analyses reveal three stages of failure: completeness, or missing knowledge; awareness, or failure to identify requirements; and application, or incorrect reasoning execution. This pattern persists across languages and model scales. Although test-time compute and retrieval augmentation yield measurable gains -- up to 4.35 and 3.78 points, respectively -- substantial gaps remain, exposing limitations in how current LLMs organize structured knowledge and execute compositional reasoning over bounded domains. The dataset is available at https://huggingface.co/datasets/2npc/KnowledgeBerg
Deep Learning based Cross-Receiver Radio Frequency Fingerprint Identification Under Varying Channels
Mar 09, 2026Radio frequency fingerprint identification (RFFI) exploits device-specific hardware impairments for transmitter recognition, but its performance is highly vulnerable to receiver variations and changing wireless channels in cross-receiver deployment. To address both challenges, this paper proposes a novel cross-receiver RFFI framework with channel robustness. In the enrollment stage, a channel-robust preprocessing method is developed to construct denoised spectral quotient (DSQ) sequences, and a DSQ-based convolutional neural network (DSQCNN) is trained using data collected from the source receiver. In the cross-receiver deployment stage, a calibration dataset is built from signals captured by both the source and target receivers, and a trainable calibration neural network (TCNN) is designed to learn the nonlinear mapping between them. The cascaded TCNN-DSQCNN framework then enables robust transmitter classification on the target receiver under varying channel conditions. To the best of our knowledge, this is the first work to jointly address channel and receiver portability through combined channel suppression and nonlinear receiver calibration. Simulations with twelve WiFi transmitters and three receivers show that the proposed method achieves reliable cross-receiver classification, reaching over 90\% accuracy at an SNR of 24 dB.
Benchmark Leakage Trap: Can We Trust LLM-based Recommendation?
Feb 14, 2026The expanding integration of Large Language Models (LLMs) into recommender systems poses critical challenges to evaluation reliability. This paper identifies and investigates a previously overlooked issue: benchmark data leakage in LLM-based recommendation. This phenomenon occurs when LLMs are exposed to and potentially memorize benchmark datasets during pre-training or fine-tuning, leading to artificially inflated performance metrics that fail to reflect true model performance. To validate this phenomenon, we simulate diverse data leakage scenarios by conducting continued pre-training of foundation models on strategically blended corpora, which include user-item interactions from both in-domain and out-of-domain sources. Our experiments reveal a dual-effect of data leakage: when the leaked data is domain-relevant, it induces substantial but spurious performance gains, misleadingly exaggerating the model's capability. In contrast, domain-irrelevant leakage typically degrades recommendation accuracy, highlighting the complex and contingent nature of this contamination. Our findings reveal that data leakage acts as a critical, previously unaccounted-for factor in LLM-based recommendation, which could impact the true model performance. We release our code at https://github.com/yusba1/LLMRec-Data-Leakage.
RankSteer: Activation Steering for Pointwise LLM Ranking
Feb 03, 2026Large language models (LLMs) have recently shown strong performance as zero-shot rankers, yet their effectiveness is highly sensitive to prompt formulation, particularly role-play instructions. Prior analyses suggest that role-related signals are encoded along activation channels that are largely separate from query-document representations, raising the possibility of steering ranking behavior directly at the activation level rather than through brittle prompt engineering. In this work, we propose RankSteer, a post-hoc activation steering framework for zero-shot pointwise LLM ranking. We characterize ranking behavior through three disentangled and steerable directions in representation space: a \textbf{decision direction} that maps hidden states to relevance scores, an \textbf{evidence direction} that captures relevance signals not directly exploited by the decision head, and a \textbf{role direction} that modulates model behavior without injecting relevance information. Using projection-based interventions at inference time, RankSteer jointly controls these directions to calibrate ranking behavior without modifying model weights or introducing explicit cross-document comparisons. Experiments on TREC DL 20 and multiple BEIR benchmarks show that RankSteer consistently improves ranking quality using only a small number of anchor queries, demonstrating that substantial ranking capacity remains under-utilized in pointwise LLM rankers. We further provide a geometric analysis revealing that steering improves ranking by stabilizing ranking geometry and reducing dispersion, offering new insight into how LLMs internally represent and calibrate relevance judgments.
Needle in the Web: A Benchmark for Retrieving Targeted Web Pages in the Wild
Dec 18, 2025Large Language Models (LLMs) have evolved from simple chatbots into sophisticated agents capable of automating complex real-world tasks, where browsing and reasoning over live web content is key to assessing retrieval and cognitive skills. Existing benchmarks like BrowseComp and xBench-DeepSearch emphasize complex reasoning searches requiring multi-hop synthesis but neglect Fuzzy Exploratory Search, namely queries that are vague and multifaceted, where users seek the most relevant webpage rather than a single factual answer. To address this gap, we introduce Needle in the Web, a novel benchmark specifically designed to evaluate modern search agents and LLM-based systems on their ability to retrieve and reason over real-world web content in response to ambiguous, exploratory queries under varying levels of difficulty. Needle in the Web comprises 663 questions spanning seven distinct domains. To ensure high query quality and answer uniqueness, we employ a flexible methodology that reliably generates queries of controllable difficulty based on factual claims of web contents. We benchmark three leading LLMs and three agent-based search systems on Needle in the Web, finding that most models struggle: many achieve below 35% accuracy, and none consistently excel across domains or difficulty levels. These findings reveal that Needle in the Web presents a significant challenge for current search systems and highlights the open problem of effective fuzzy retrieval under semantic ambiguity.
Meta-Learning Based Few-Shot Graph-Level Anomaly Detection
Oct 09, 2025Graph-level anomaly detection aims to identify anomalous graphs or subgraphs within graph datasets, playing a vital role in various fields such as fraud detection, review classification, and biochemistry. While Graph Neural Networks (GNNs) have made significant progress in this domain, existing methods rely heavily on large amounts of labeled data, which is often unavailable in real-world scenarios. Additionally, few-shot anomaly detection methods based on GNNs are prone to noise interference, resulting in poor embedding quality and reduced model robustness. To address these challenges, we propose a novel meta-learning-based graph-level anomaly detection framework (MA-GAD), incorporating a graph compression module that reduces the graph size, mitigating noise interference while retaining essential node information. We also leverage meta-learning to extract meta-anomaly information from similar networks, enabling the learning of an initialization model that can rapidly adapt to new tasks with limited samples. This improves the anomaly detection performance on target graphs, and a bias network is used to enhance the distinction between anomalous and normal nodes. Our experimental results, based on four real-world biochemical datasets, demonstrate that MA-GAD outperforms existing state-of-the-art methods in graph-level anomaly detection under few-shot conditions. Experiments on both graph anomaly and subgraph anomaly detection tasks validate the framework's effectiveness on real-world datasets.
Addressing Graph Anomaly Detection via Causal Edge Separation and Spectrum
Aug 20, 2025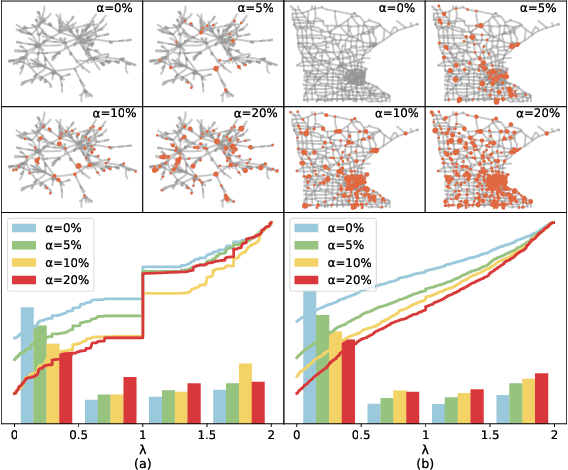
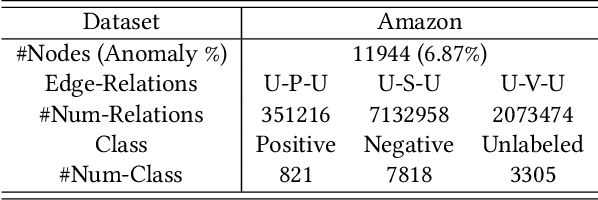
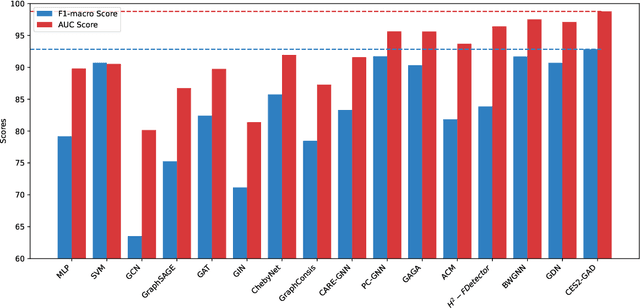
In the real world, anomalous entities often add more legitimate connections while hiding direct links with other anomalous entities, leading to heterophilic structures in anomalous networks that most GNN-based techniques fail to address. Several works have been proposed to tackle this issue in the spatial domain. However, these methods overlook the complex relationships between node structure encoding, node features, and their contextual environment and rely on principled guidance, research on solving spectral domain heterophilic problems remains limited. This study analyzes the spectral distribution of nodes with different heterophilic degrees and discovers that the heterophily of anomalous nodes causes the spectral energy to shift from low to high frequencies. To address the above challenges, we propose a spectral neural network CES2-GAD based on causal edge separation for anomaly detection on heterophilic graphs. Firstly, CES2-GAD will separate the original graph into homophilic and heterophilic edges using causal interventions. Subsequently, various hybrid-spectrum filters are used to capture signals from the segmented graphs. Finally, representations from multiple signals are concatenated and input into a classifier to predict anomalies. Extensive experiments with real-world datasets have proven the effectiveness of the method we proposed.
Diversity-Enhanced Reasoning for Subjective Questions
Jul 27, 2025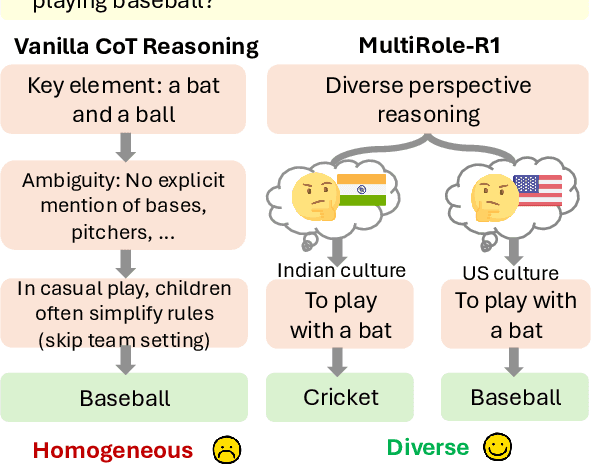
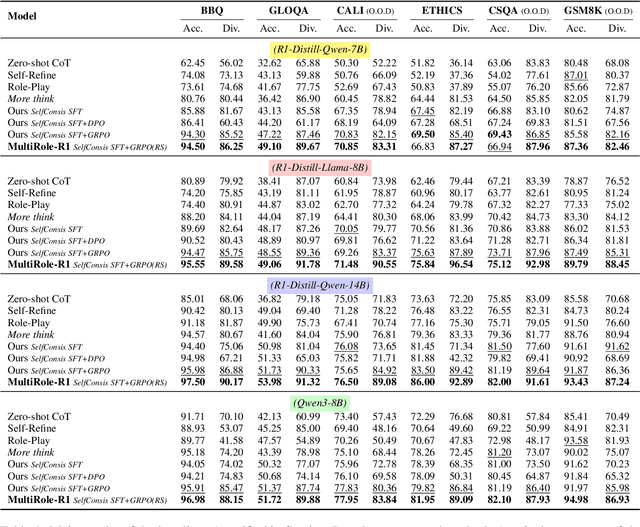
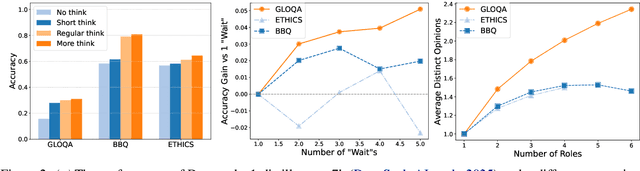
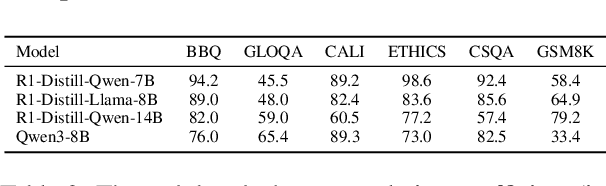
Large reasoning models (LRM) with long chain-of-thought (CoT) capabilities have shown strong performance on objective tasks, such as math reasoning and coding. However, their effectiveness on subjective questions that may have different responses from different perspectives is still limited by a tendency towards homogeneous reasoning, introduced by the reliance on a single ground truth in supervised fine-tuning and verifiable reward in reinforcement learning. Motivated by the finding that increasing role perspectives consistently improves performance, we propose MultiRole-R1, a diversity-enhanced framework with multiple role perspectives, to improve the accuracy and diversity in subjective reasoning tasks. MultiRole-R1 features an unsupervised data construction pipeline that generates reasoning chains that incorporate diverse role perspectives. We further employ reinforcement learning via Group Relative Policy Optimization (GRPO) with reward shaping, by taking diversity as a reward signal in addition to the verifiable reward. With specially designed reward functions, we successfully promote perspective diversity and lexical diversity, uncovering a positive relation between reasoning diversity and accuracy. Our experiment on six benchmarks demonstrates MultiRole-R1's effectiveness and generalizability in enhancing both subjective and objective reasoning, showcasing the potential of diversity-enhanced training in LRMs.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.