 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultureCLIP: Empowering CLIP with Cultural Awareness through Synthetic Images and Contextualized Captions
Jul 08, 2025Pretrained vision-language models (VLMs) such as CLIP excel in multimodal understanding but struggle with contextually relevant fine-grained visual features, making it difficult to distinguish visually similar yet culturally distinct concepts. This limitation stems from the scarcity of high-quality culture-specific datasets, the lack of integrated contextual knowledge, and the absence of hard negatives highlighting subtle distinctions. To address these challenges, we first design a data curation pipeline that leverages open-sourced VLMs and text-to-image diffusion models to construct CulTwin, a synthetic cultural dataset. This dataset consists of paired concept-caption-image triplets, where concepts visually resemble each other but represent different cultural contexts. Then, we fine-tune CLIP on CulTwin to create CultureCLIP, which aligns cultural concepts with contextually enhanced captions and synthetic images through customized contrastive learning, enabling finer cultural differentiation while preserving generalization capabilities. Experiments on culturally relevant benchmarks show that CultureCLIP outperforms the base CLIP, achieving up to a notable 5.49% improvement in fine-grained concept recognition on certain tasks, while preserving CLIP's original generalization ability, validating the effectiveness of our data synthesis and VLM backbone training paradigm in capturing subtle cultural distinctions.
MMBoundary: Advancing MLLM Knowledge Boundary Awareness through Reasoning Step Confidence Calibration
May 29, 2025In recent years, multimodal large language models (MLLMs) have made significant progress but continue to face inherent challenges in multimodal reasoning, which requires multi-level (e.g., perception, reasoning) and multi-granular (e.g., multi-step reasoning chain) advanced inferencing. Prior work on estimating model confidence tends to focus on the overall response for training and calibration, but fails to assess confidence in each reasoning step, leading to undesirable hallucination snowballing. In this work, we present MMBoundary, a novel framework that advances the knowledge boundary awareness of MLLMs through reasoning step confidence calibration. To achieve this, we propose to incorporate complementary textual and cross-modal self-rewarding signals to estimate confidence at each step of the MLLM reasoning process. In addition to supervised fine-tuning MLLM on this set of self-rewarded confidence estimation signal for initial confidence expression warm-up, we introduce a reinforcement learning stage with multiple reward functions for further aligning model knowledge and calibrating confidence at each reasoning step, enhancing reasoning chain self-correction. Empirical results show that MMBoundary significantly outperforms existing methods across diverse domain datasets and metrics, achieving an average of 7.5% reduction in multimodal confidence calibration errors and up to 8.3% improvement in task performance.
MAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness
Apr 30, 2025With the widespread application of large language models (LLMs), the issue of generating non-existing facts, known as hallucination, has garnered increasing attention. Previous research in enhancing LLM confidence estimation mainly focuses on the single problem setting. However, LLM awareness of its internal parameterized knowledge boundary under the more challenging multi-problem setting, which requires answering multiple problems accurately simultaneously, remains underexplored. To bridge this gap, we introduce a novel method, Multiple Answers and Confidence Stepwise Tuning (MAC-Tuning), that separates the learning of answer prediction and confidence estimation during fine-tuning on instruction data. Extensive experiments demonstrate that our method outperforms baselines by up to 25% in average precision.
V$^2$R-Bench: Holistically Evaluating LVLM Robustness to Fundamental Visual Variations
Apr 24, 2025



Large Vision Language Models (LVLMs) excel in various vision-language tasks. Yet, their robustness to visual variations in position, scale, orientation, and context that objects in natural scenes inevitably exhibit due to changes in viewpoint and environment remains largely underexplored. To bridge this gap, we introduce V$^2$R-Bench, a comprehensive benchmark framework for evaluating Visual Variation Robustness of LVLMs, which encompasses automated evaluation dataset generation and principled metrics for thorough robustness assessment. Through extensive evaluation on 21 LVLMs, we reveal a surprising vulnerability to visual variations, in which even advanced models that excel at complex vision-language tasks significantly underperform on simple tasks such as object recognition. Interestingly, these models exhibit a distinct visual position bias that contradicts theories of effective receptive fields, and demonstrate a human-like visual acuity threshold. To identify the source of these vulnerabilities, we present a systematic framework for component-level analysis, featuring a novel visualization approach for aligned visual features. Results show that these vulnerabilities stem from error accumulation in the pipeline architecture and inadequate multimodal alignment. Complementary experiments with synthetic data further demonstrate that these limitations are fundamentally architectural deficiencies, scoring the need for architectural innovations in future LVLM designs.
TAMP: Token-Adaptive Layerwise Pruning in Multimodal Large Language Models
Apr 15, 2025Multimodal Large Language Models (MLLMs) have shown remarkable versatility in understanding diverse multimodal data and tasks. However, these capabilities come with an increased model scale. While post-training pruning reduces model size in unimodal models, its application to MLLMs often yields limited success. Our analysis discovers that conventional methods fail to account for the unique token attributes across layers and modalities inherent to MLLMs. Inspired by this observation, we propose TAMP, a simple yet effective pruning framework tailored for MLLMs, featuring two key components: (1) Diversity-Aware Sparsity, which adjusts sparsity ratio per layer based on diversities among multimodal output tokens, preserving more parameters in high-diversity layers; and (2) Adaptive Multimodal Input Activation, which identifies representative multimodal input tokens using attention scores to guide unstructured weight pruning. We validate our method on two state-of-the-art MLLMs: LLaVA-NeXT, designed for vision-language tasks, and VideoLLaMA2, capable of processing audio, visual, and language modalities. Empirical experiments across various multimodal evaluation benchmarks demonstrate that each component of our approach substantially outperforms existing pruning techniques.
GSplit: Scaling Graph Neural Network Training on Large Graphs via Split-Parallelism
Mar 24, 2023



Large-scale graphs with billions of edges are ubiquitous in many industries, science, and engineering fields such as recommendation systems, social graph analysis, knowledge base, material science, and biology. Graph neural networks (GNN), an emerging class of machine learning models, are increasingly adopted to learn on these graphs due to their superior performance in various graph analytics tasks. Mini-batch training is commonly adopted to train on large graphs, and data parallelism is the standard approach to scale mini-batch training to multiple GPUs. In this paper, we argue that several fundamental performance bottlenecks of GNN training systems have to do with inherent limitations of the data parallel approach. We then propose split parallelism, a novel parallel mini-batch training paradigm. We implement split parallelism in a novel system called gsplit and show that it outperforms state-of-the-art systems such as DGL, Quiver, and PaGraph.
NextDoor: GPU-Based Graph Sampling for Graph Machine Learning
Sep 17, 2020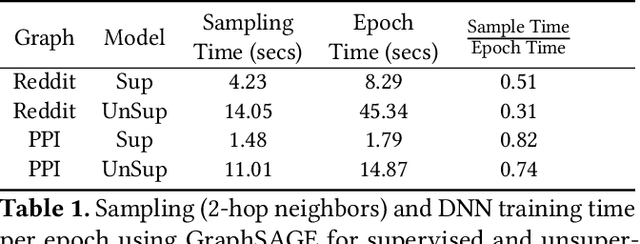


Representation learning is a fundamental task in machine learning. It consists of learning the features of data items automatically, typically using a deep neural network (DNN), instead of selecting hand-engineered features that typically have worse performance. Graph data requires specific algorithms for representation learning such as DeepWalk, node2vec, and GraphSAGE. These algorithms first sample the input graph and then train a DNN based on the samples. It is common to use GPUs for training, but graph sampling on GPUs is challenging. Sampling is an embarrassingly parallel task since each sample can be generated independently. However, the irregularity of graphs makes it hard to use GPU resources effectively. Existing graph processing, mining, and representation learning systems do not effectively parallelize sampling and this negatively impacts the end-to-end performance of representation learning. In this paper, we present NextDoor, the first system specifically designed to perform graph sampling on GPUs. NextDoor introduces a high-level API based on a novel paradigm for parallel graph sampling called transit-parallelism. We implement several graph sampling applications, and show that NextDoor runs them orders of magnitude faster than existing systems