 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network Training Systems: A Performance Comparison of Full-Graph and Mini-Batch
Jun 01, 2024Graph Neural Networks (GNNs) have gained significant attention in recent years due to their ability to learn representations of graph structured data. Two common methods for training GNNs are mini-batch training and full-graph training. Since these two methods require different training pipelines and systems optimizations, two separate categories of GNN training systems emerged, each tailored for one method. Works that introduce systems belonging to a particular category predominantly compare them with other systems within the same category, offering limited or no comparison with systems from the other category. Some prior work also justifies its focus on one specific training method by arguing that it achieves higher accuracy than the alternative. The literature, however, has incomplete and contradictory evidence in this regard. In this paper, we provide a comprehensive empirical comparison of full-graph and mini-batch GNN training systems to get a clearer picture of the state of the art in the field. We find that the mini-batch training systems we consider consistently converge faster than the full-graph training ones across multiple datasets, GNN models, and system configurations, with speedups between 2.4x - 15.2x. We also find that both training techniques converge to similar accuracy values, so comparing systems across the two categories in terms of time-to-accuracy is a sound approach.
GSplit: Scaling Graph Neural Network Training on Large Graphs via Split-Parallelism
Mar 24, 2023Large-scale graphs with billions of edges are ubiquitous in many industries, science, and engineering fields such as recommendation systems, social graph analysis, knowledge base, material science, and biology. Graph neural networks (GNN), an emerging class of machine learning models, are increasingly adopted to learn on these graphs due to their superior performance in various graph analytics tasks. Mini-batch training is commonly adopted to train on large graphs, and data parallelism is the standard approach to scale mini-batch training to multiple GPUs. In this paper, we argue that several fundamental performance bottlenecks of GNN training systems have to do with inherent limitations of the data parallel approach. We then propose split parallelism, a novel parallel mini-batch training paradigm. We implement split parallelism in a novel system called gsplit and show that it outperforms state-of-the-art systems such as DGL, Quiver, and PaGraph.
Scalable Graph Neural Network Training: The Case for Sampling
May 05, 2021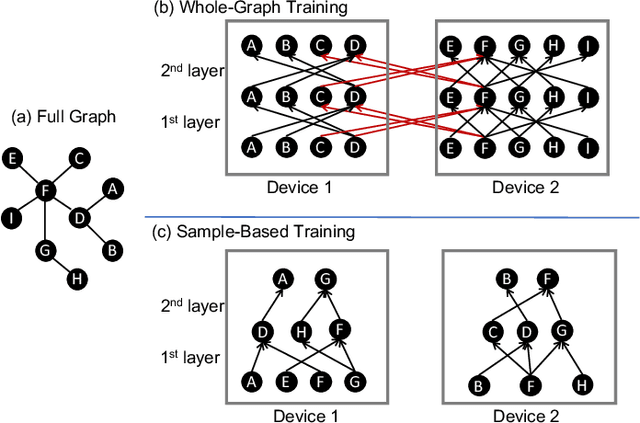

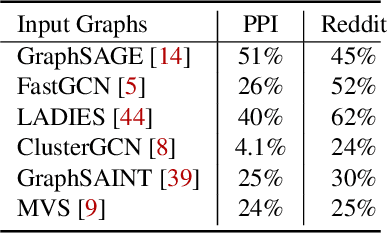

Graph Neural Networks (GNNs) are a new and increasingly popular family of deep neural network architectures to perform learning on graphs. Training them efficiently is challenging due to the irregular nature of graph data. The problem becomes even more challenging when scaling to large graphs that exceed the capacity of single devices. Standard approaches to distributed DNN training, such as data and model parallelism, do not directly apply to GNNs. Instead, two different approaches have emerged in the literature: whole-graph and sample-based training. In this paper, we review and compare the two approaches. Scalability is challenging with both approaches, but we make a case that research should focus on sample-based training since it is a more promising approach. Finally, we review recent systems supporting sample-based training.
NextDoor: GPU-Based Graph Sampling for Graph Machine Learning
Sep 17, 2020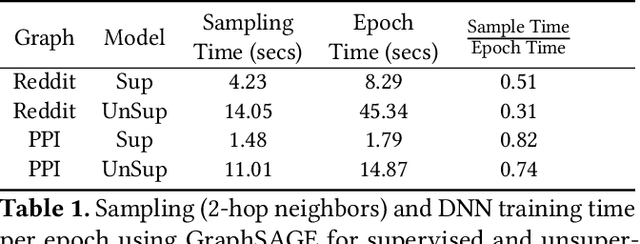
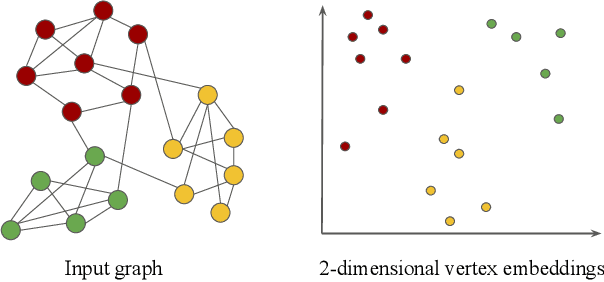


Representation learning is a fundamental task in machine learning. It consists of learning the features of data items automatically, typically using a deep neural network (DNN), instead of selecting hand-engineered features that typically have worse performance. Graph data requires specific algorithms for representation learning such as DeepWalk, node2vec, and GraphSAGE. These algorithms first sample the input graph and then train a DNN based on the samples. It is common to use GPUs for training, but graph sampling on GPUs is challenging. Sampling is an embarrassingly parallel task since each sample can be generated independently. However, the irregularity of graphs makes it hard to use GPU resources effectively. Existing graph processing, mining, and representation learning systems do not effectively parallelize sampling and this negatively impacts the end-to-end performance of representation learning. In this paper, we present NextDoor, the first system specifically designed to perform graph sampling on GPUs. NextDoor introduces a high-level API based on a novel paradigm for parallel graph sampling called transit-parallelism. We implement several graph sampling applications, and show that NextDoor runs them orders of magnitude faster than existing systems