 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention for Causal Relationship Discovery from Biological Neural Dynamics
Nov 23, 2023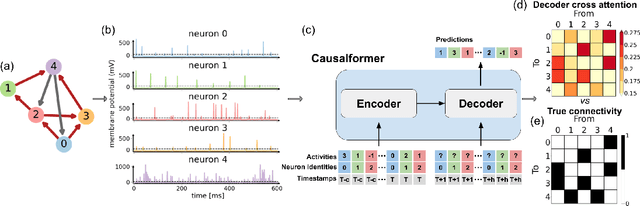

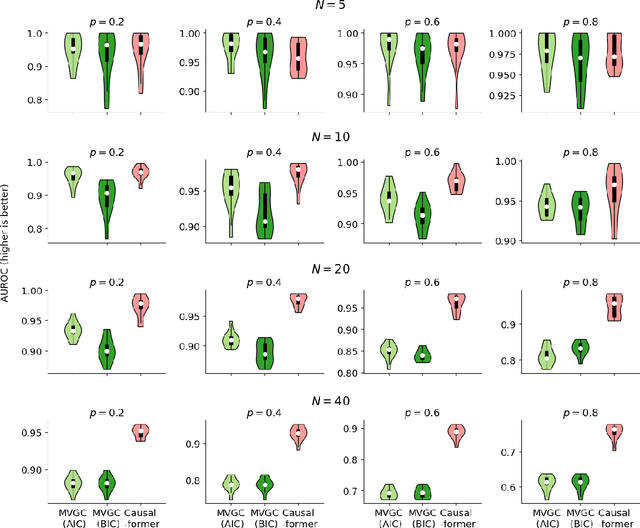

This paper explores the potential of the transformer models for learning Granger causality in networks with complex nonlinear dynamics at every node, as in neurobiological and biophysical networks. Our study primarily focuses on a proof-of-concept investigation based on simulated neural dynamics, for which the ground-truth causality is known through the underlying connectivity matrix. For transformer models trained to forecast neuronal population dynamics, we show that the cross attention module effectively captures the causal relationship among neurons, with an accuracy equal or superior to that for the most popular Granger causality analysis method. While we acknowledge that real-world neurobiology data will bring further challenges, including dynamic connectivity and unobserved variability, this research offers an encouraging preliminary glimpse into the utility of the transformer model for causal representation learning in neuroscience.
GSplit: Scaling Graph Neural Network Training on Large Graphs via Split-Parallelism
Mar 24, 2023



Large-scale graphs with billions of edges are ubiquitous in many industries, science, and engineering fields such as recommendation systems, social graph analysis, knowledge base, material science, and biology. Graph neural networks (GNN), an emerging class of machine learning models, are increasingly adopted to learn on these graphs due to their superior performance in various graph analytics tasks. Mini-batch training is commonly adopted to train on large graphs, and data parallelism is the standard approach to scale mini-batch training to multiple GPUs. In this paper, we argue that several fundamental performance bottlenecks of GNN training systems have to do with inherent limitations of the data parallel approach. We then propose split parallelism, a novel parallel mini-batch training paradigm. We implement split parallelism in a novel system called gsplit and show that it outperforms state-of-the-art systems such as DGL, Quiver, and PaGraph.
In-Place Zero-Space Memory Protection for CNN
Oct 31, 2019
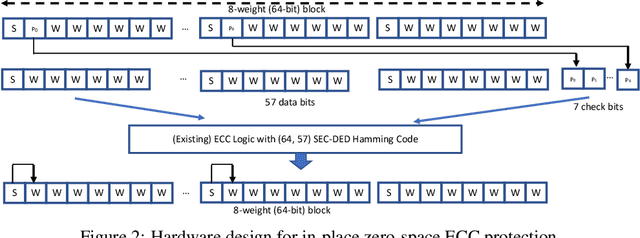
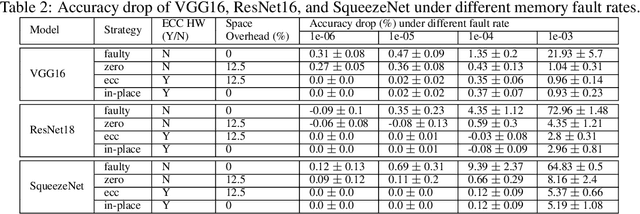
Convolutional Neural Networks (CNN) are being actively explored for safety-critical applications such as autonomous vehicles and aerospace, where it is essential to ensure the reliability of inference results in the presence of possible memory faults. Traditional methods such as error correction codes (ECC) and Triple Modular Redundancy (TMR) are CNN-oblivious and incur substantial memory overhead and energy cost. This paper introduces in-place zero-space ECC assisted with a new training scheme weight distribution-oriented training. The new method provides the first known zero space cost memory protection for CNNs without compromising the reliability offered by traditional ECC.
Exascale Deep Learning to Accelerate Cancer Research
Sep 26, 2019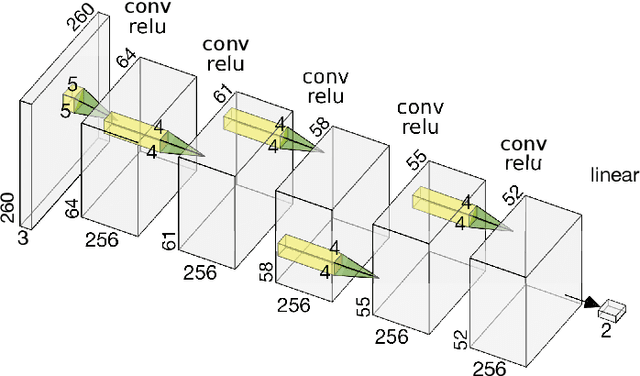
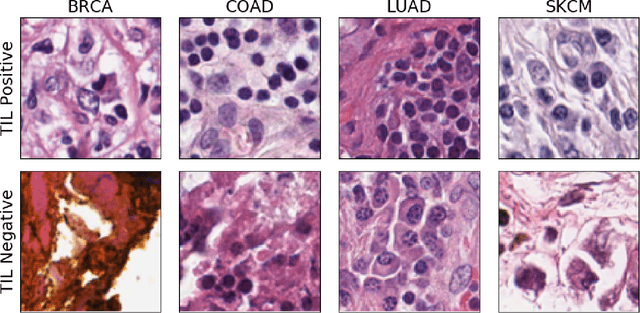
Deep learning, through the use of neural networks, has demonstrated remarkable ability to automate many routine tasks when presented with sufficient data for training. The neural network architecture (e.g. number of layers, types of layers, connections between layers, etc.) plays a critical role in determining what, if anything, the neural network is able to learn from the training data. The trend for neural network architectures, especially those trained on ImageNet, has been to grow ever deeper and more complex. The result has been ever increasing accuracy on benchmark datasets with the cost of increased computational demands. In this paper we demonstrate that neural network architectures can be automatically generated, tailored for a specific application, with dual objectives: accuracy of prediction and speed of prediction. Using MENNDL--an HPC-enabled software stack for neural architecture search--we generate a neural network with comparable accuracy to state-of-the-art networks on a cancer pathology dataset that is also $16\times$ faster at inference. The speedup in inference is necessary because of the volume and velocity of cancer pathology data; specifically, the previous state-of-the-art networks are too slow for individual researchers without access to HPC systems to keep pace with the rate of data generation. Our new model enables researchers with modest computational resources to analyze newly generated data faster than it is collected.