 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile
Apr 21, 2024



This work is motivated by recent developments in Deep Neural Networks, particularly the Transformer architectures underlying applications such as ChatGPT, and the need for performing inference on mobile devices. Focusing on emerging transformers (specifically the ones with computationally efficient Swin-like architectures) and large models (e.g., Stable Diffusion and LLMs) based on transformers, we observe that layout transformations between the computational operators cause a significant slowdown in these applications. This paper presents SmartMem, a comprehensive framework for eliminating most layout transformations, with the idea that multiple operators can use the same tensor layout through careful choice of layout and implementation of operations. Our approach is based on classifying the operators into four groups, and considering combinations of producer-consumer edges between the operators. We develop a set of methods for searching such layouts. Another component of our work is developing efficient memory layouts for 2.5 dimensional memory commonly seen in mobile devices. Our experimental results show that SmartMem outperforms 5 state-of-the-art DNN execution frameworks on mobile devices across 18 varied neural networks, including CNNs, Transformers with both local and global attention, as well as LLMs. In particular, compared to DNNFusion, SmartMem achieves an average speedup of 2.8$\times$, and outperforms TVM and MNN with speedups of 6.9$\times$ and 7.9$\times$, respectively, on average.
Efficient Large Language Models Fine-Tuning On Graphs
Dec 07, 2023Learning from Text-Attributed Graphs (TAGs) has attracted significant attention due to its wide range of real-world applications. The rapid evolution of large language models (LLMs) has revolutionized the way we process textual data, which indicates a strong potential to replace shallow text embedding generally used in Graph Neural Networks (GNNs). However, we find that existing LLM approaches that exploit text information in graphs suffer from inferior computation and data efficiency. In this work, we introduce a novel and efficient approach for the end-to-end fine-tuning of Large Language Models (LLMs) on TAGs, named LEADING. The proposed approach maintains computation cost and memory overhead comparable to the graph-less fine-tuning of LLMs. Moreover, it transfers the rick knowledge in LLMs to downstream graph learning tasks effectively with limited labeled data in semi-supervised learning. Its superior computation and data efficiency are demonstrated through comprehensive experiments, offering a promising solution for a wide range of LLMs and graph learning tasks on TAGs.
BitGNN: Unleashing the Performance Potential of Binary Graph Neural Networks on GPUs
May 04, 2023



Recent studies have shown that Binary Graph Neural Networks (GNNs) are promising for saving computations of GNNs through binarized tensors. Prior work, however, mainly focused on algorithm designs or training techniques, leaving it open to how to materialize the performance potential on accelerator hardware fully. This work redesigns the binary GNN inference backend from the efficiency perspective. It fills the gap by proposing a series of abstractions and techniques to map binary GNNs and their computations best to fit the nature of bit manipulations on GPUs. Results on real-world graphs with GCNs, GraphSAGE, and GraphSAINT show that the proposed techniques outperform state-of-the-art binary GNN implementations by 8-22X with the same accuracy maintained. BitGNN code is publicly available.
Survey: Exploiting Data Redundancy for Optimization of Deep Learning
Aug 29, 2022

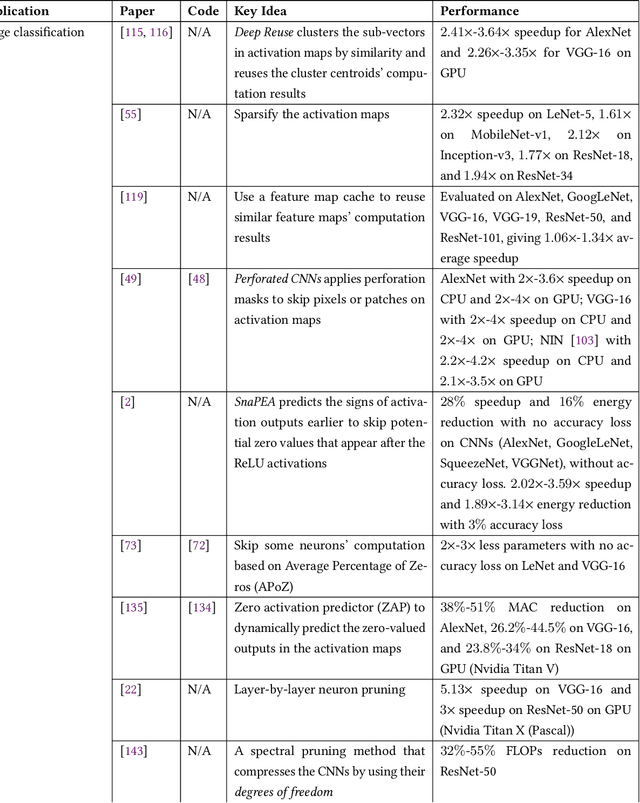

Data redundancy is ubiquitous in the inputs and intermediate results of Deep Neural Networks (DNN). It offers many significant opportunities for improving DNN performance and efficiency and has been explored in a large body of work. These studies have scattered in many venues across several years. The targets they focus on range from images to videos and texts, and the techniques they use to detect and exploit data redundancy also vary in many aspects. There is not yet a systematic examination and summary of the many efforts, making it difficult for researchers to get a comprehensive view of the prior work, the state of the art, differences and shared principles, and the areas and directions yet to explore. This article tries to fill the void. It surveys hundreds of recent papers on the topic, introduces a novel taxonomy to put the various techniques into a single categorization framework, offers a comprehensive description of the main methods used for exploiting data redundancy in improving multiple kinds of DNNs on data, and points out a set of research opportunities for future to explore.
Finding Reusable Machine Learning Components to Build Programming Language Processing Pipelines
Aug 11, 2022
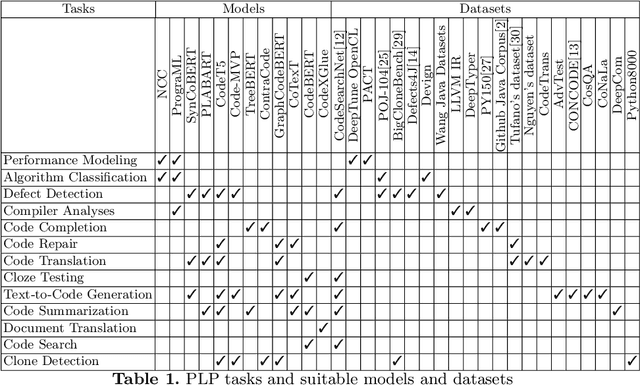

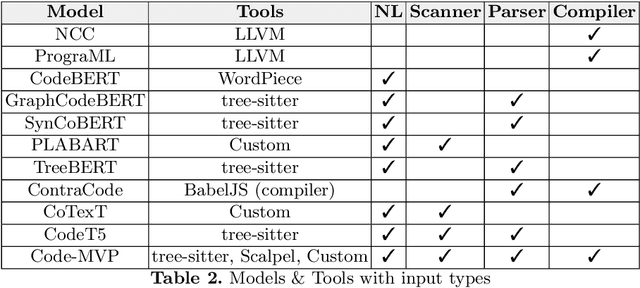
Programming Language Processing (PLP) using machine learning has made vast improvements in the past few years. Increasingly more people are interested in exploring this promising field. However, it is challenging for new researchers and developers to find the right components to construct their own machine learning pipelines, given the diverse PLP tasks to be solved, the large number of datasets and models being released, and the set of complex compilers or tools involved. To improve the findability, accessibility, interoperability and reusability (FAIRness) of machine learning components, we collect and analyze a set of representative papers in the domain of machine learning-based PLP. We then identify and characterize key concepts including PLP tasks, model architectures and supportive tools. Finally, we show some example use cases of leveraging the reusable components to construct machine learning pipelines to solve a set of PLP tasks.
CoCoPIE XGen: A Full-Stack AI-Oriented Optimizing Framework
Jun 21, 2022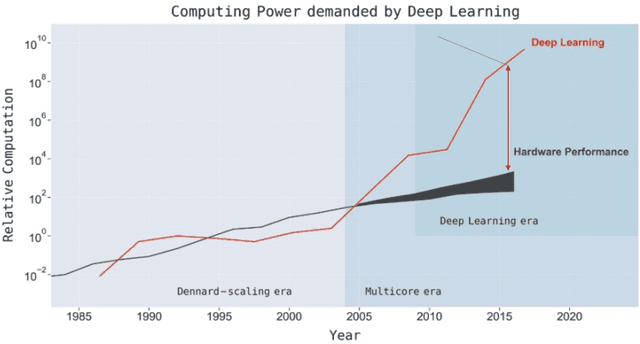

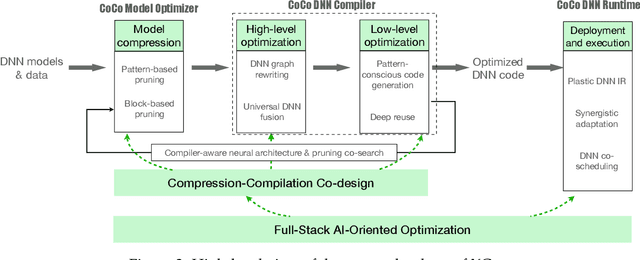

There is a growing demand for shifting the delivery of AI capability from data centers on the cloud to edge or end devices, exemplified by the fast emerging real-time AI-based apps running on smartphones, AR/VR devices, autonomous vehicles, and various IoT devices. The shift has however been seriously hampered by the large growing gap between DNN computing demands and the computing power on edge or end devices. This article presents the design of XGen, an optimizing framework for DNN designed to bridge the gap. XGen takes cross-cutting co-design as its first-order consideration. Its full-stack AI-oriented optimizations consist of a number of innovative optimizations at every layer of the DNN software stack, all designed in a cooperative manner. The unique technology makes XGen able to optimize various DNNs, including those with an extreme depth (e.g., BERT, GPT, other transformers), and generate code that runs several times faster than those from existing DNN frameworks, while delivering the same level of accuracy.
Enabling Level-4 Autonomous Driving on a Single $1k Off-the-Shelf Card
Oct 12, 2021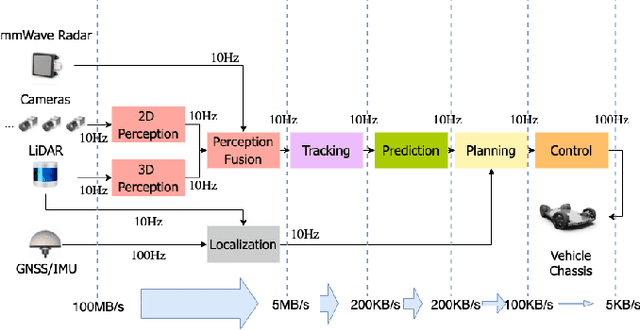
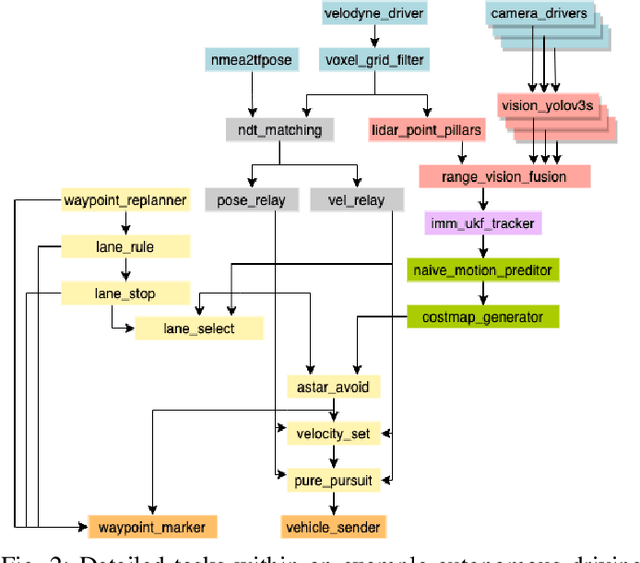
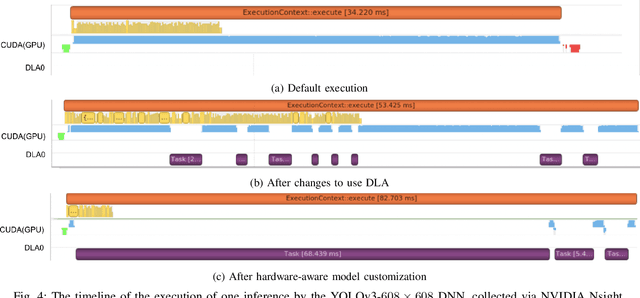
Autonomous driving is of great interest in both research and industry. The high cost has been one of the major roadblocks that slow down the development and adoption of autonomous driving in practice. This paper, for the first-time, shows that it is possible to run level-4 (i.e., fully autonomous driving) software on a single off-the-shelf card (Jetson AGX Xavier) for less than $1k, an order of magnitude less than the state-of-the-art systems, while meeting all the requirements of latency. The success comes from the resolution of some important issues shared by existing practices through a series of measures and innovations. The study overturns the common perceptions of the computing resources required by level-4 autonomous driving, points out a promising path for the industry to lower the cost, and suggests a number of research opportunities for rethinking the architecture, software design, and optimizations of autonomous driving.
Coarsening Optimization for Differentiable Programming
Oct 05, 2021

This paper presents a novel optimization for differentiable programming named coarsening optimization. It offers a systematic way to synergize symbolic differentiation and algorithmic differentiation (AD). Through it, the granularity of the computations differentiated by each step in AD can become much larger than a single operation, and hence lead to much reduced runtime computations and data allocations in AD. To circumvent the difficulties that control flow creates to symbolic differentiation in coarsening, this work introduces phi-calculus, a novel method to allow symbolic reasoning and differentiation of computations that involve branches and loops. It further avoids "expression swell" in symbolic differentiation and balance reuse and coarsening through the design of reuse-centric segment of interest identification. Experiments on a collection of real-world applications show that coarsening optimization is effective in speeding up AD, producing several times to two orders of magnitude speedups.
Achieving Real-Time LiDAR 3D Object Detection on a Mobile Device
Dec 26, 2020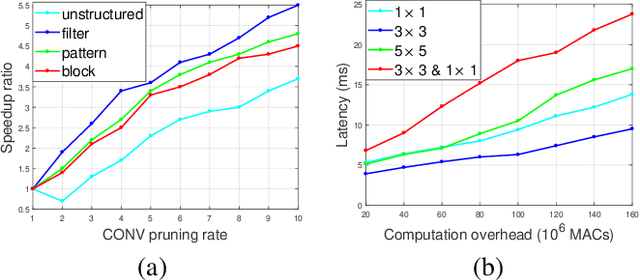
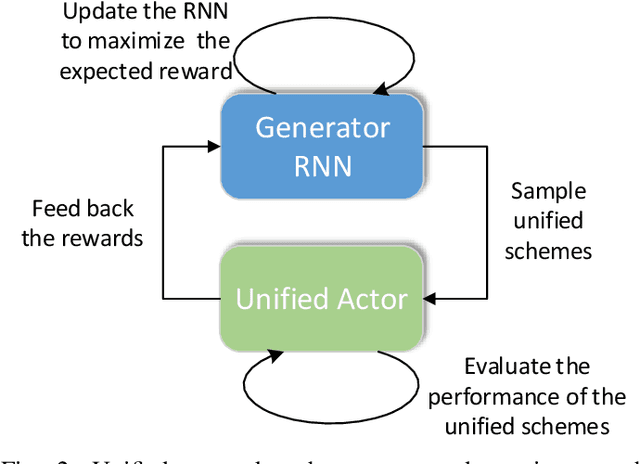
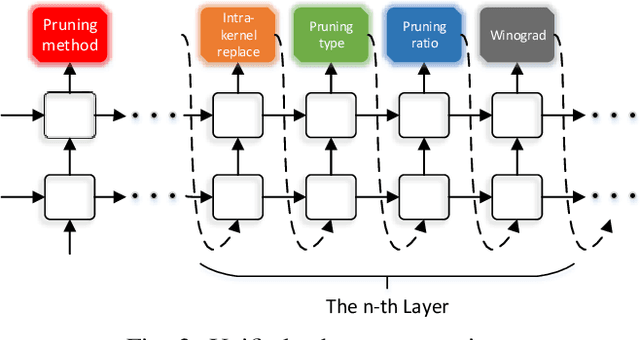

3D object detection is an important task, especially in the autonomous driving application domain. However, it is challenging to support the real-time performance with the limited computation and memory resources on edge-computing devices in self-driving cars. To achieve this, we propose a compiler-aware unified framework incorporating network enhancement and pruning search with the reinforcement learning techniques, to enable real-time inference of 3D object detection on the resource-limited edge-computing devices. Specifically, a generator Recurrent Neural Network (RNN) is employed to provide the unified scheme for both network enhancement and pruning search automatically, without human expertise and assistance. And the evaluated performance of the unified schemes can be fed back to train the generator RNN. The experimental results demonstrate that the proposed framework firstly achieves real-time 3D object detection on mobile devices (Samsung Galaxy S20 phone) with competitive detection performance.
Achieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020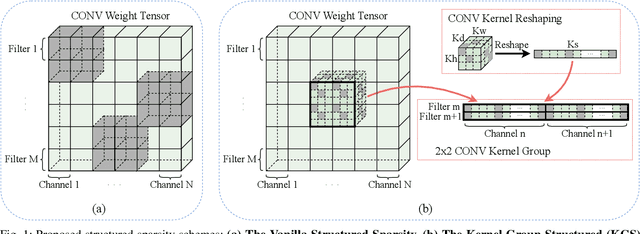
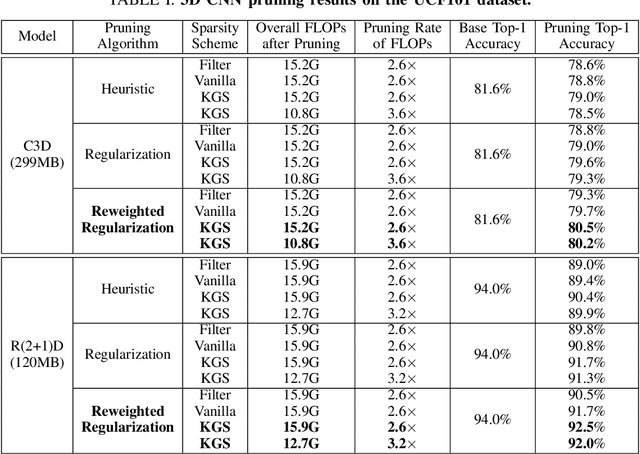
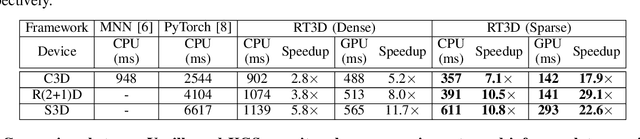

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.