 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Reusable Machine Learning Components to Build Programming Language Processing Pipelines
Paper and Code
Aug 11, 2022
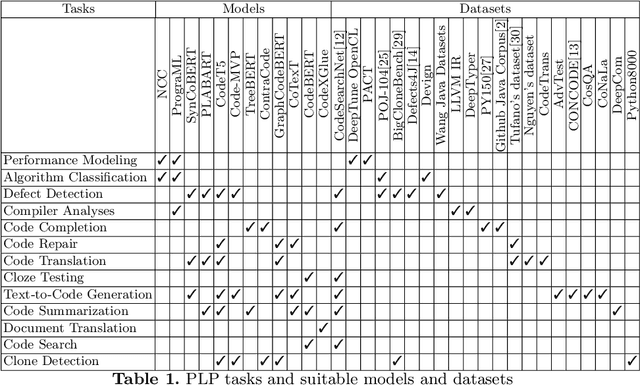

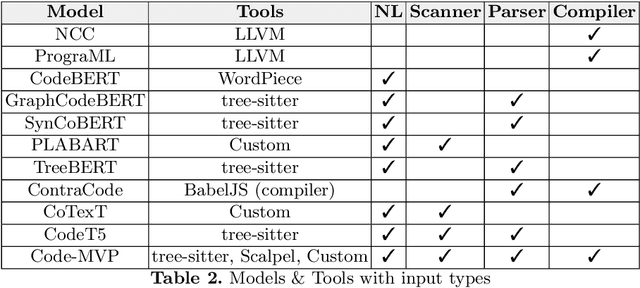
Programming Language Processing (PLP) using machine learning has made vast improvements in the past few years. Increasingly more people are interested in exploring this promising field. However, it is challenging for new researchers and developers to find the right components to construct their own machine learning pipelines, given the diverse PLP tasks to be solved, the large number of datasets and models being released, and the set of complex compilers or tools involved. To improve the findability, accessibility, interoperability and reusability (FAIRness) of machine learning components, we collect and analyze a set of representative papers in the domain of machine learning-based PLP. We then identify and characterize key concepts including PLP tasks, model architectures and supportive tools. Finally, we show some example use cases of leveraging the reusable components to construct machine learning pipelines to solve a set of PLP tasks.