 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMem: Supporting Modern DNN Workloads on Mobile with GPU Memory Hierarchy Optimizations
Feb 17, 2026The increasing size and complexity of modern deep neural networks (DNNs) pose significant challenges for on-device inference on mobile GPUs, with limited memory and computational resources. Existing DNN acceleration frameworks primarily deploy a weight preloading strategy, where all model parameters are loaded into memory before execution on mobile GPUs. We posit that this approach is not adequate for modern DNN workloads that comprise very large model(s) and possibly execution of several distinct models in succession. In this work, we introduce FlashMem, a memory streaming framework designed to efficiently execute large-scale modern DNNs and multi-DNN workloads while minimizing memory consumption and reducing inference latency. Instead of fully preloading weights, FlashMem statically determines model loading schedules and dynamically streams them on demand, leveraging 2.5D texture memory to minimize data transformations and improve execution efficiency. Experimental results on 11 models demonstrate that FlashMem achieves 2.0x to 8.4x memory reduction and 1.7x to 75.0x speedup compared to existing frameworks, enabling efficient execution of large-scale models and multi-DNN support on resource-constrained mobile GPUs.
From Bits to Chips: An LLM-based Hardware-Aware Quantization Agent for Streamlined Deployment of LLMs
Jan 07, 2026Deploying models, especially large language models (LLMs), is becoming increasingly attractive to a broader user base, including those without specialized expertise. However, due to the resource constraints of certain hardware, maintaining high accuracy with larger model while meeting the hardware requirements remains a significant challenge. Model quantization technique helps mitigate memory and compute bottlenecks, yet the added complexities of tuning and deploying quantized models further exacerbates these challenges, making the process unfriendly to most of the users. We introduce the Hardware-Aware Quantization Agent (HAQA), an automated framework that leverages LLMs to streamline the entire quantization and deployment process by enabling efficient hyperparameter tuning and hardware configuration, thereby simultaneously improving deployment quality and ease of use for a broad range of users. Our results demonstrate up to a 2.3x speedup in inference, along with increased throughput and improved accuracy compared to unoptimized models on Llama. Additionally, HAQA is designed to implement adaptive quantization strategies across diverse hardware platforms, as it automatically finds optimal settings even when they appear counterintuitive, thereby reducing extensive manual effort and demonstrating superior adaptability. Code will be released.
Scalable Deep Metric Learning on Attributed Graphs
Nov 20, 2024We consider the problem of constructing embeddings of large attributed graphs and supporting multiple downstream learning tasks. We develop a graph embedding method, which is based on extending deep metric and unbiased contrastive learning techniques to 1) work with attributed graphs, 2) enabling a mini-batch based approach, and 3) achieving scalability. Based on a multi-class tuplet loss function, we present two algorithms -- DMT for semi-supervised learning and DMAT-i for the unsupervised case. Analyzing our methods, we provide a generalization bound for the downstream node classification task and for the first time relate tuplet loss to contrastive learning. Through extensive experiments, we show high scalability of representation construction, and in applying the method for three downstream tasks (node clustering, node classification, and link prediction) better consistency over any single existing method.
Federated Contrastive Learning of Graph-Level Representations
Nov 18, 2024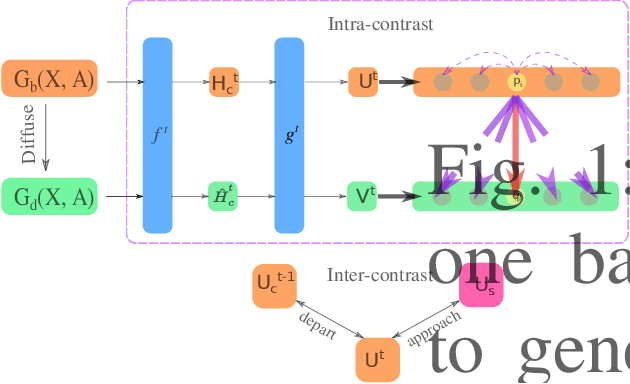
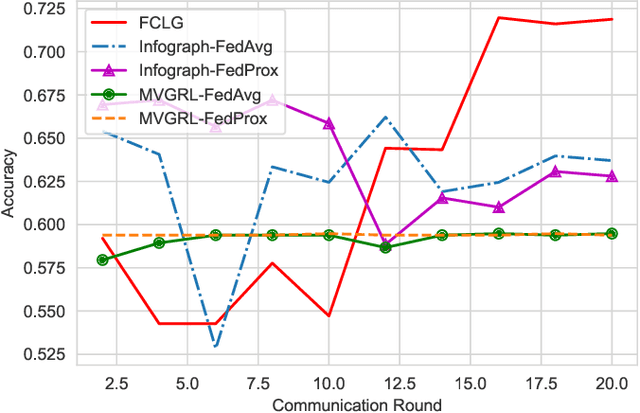

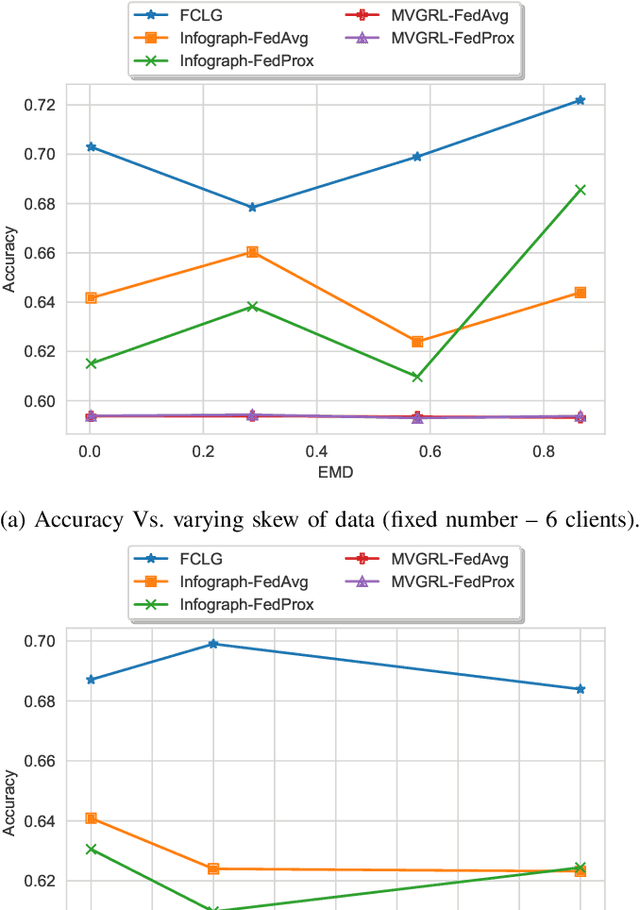
Graph-level representations (and clustering/classification based on these representations) are required in a variety of applications. Examples include identifying malicious network traffic, prediction of protein properties, and many others. Often, data has to stay in isolated local systems (i.e., cannot be centrally shared for analysis) due to a variety of considerations like privacy concerns, lack of trust between the parties, regulations, or simply because the data is too large to be shared sufficiently quickly. This points to the need for federated learning for graph-level representations, a topic that has not been explored much, especially in an unsupervised setting. Addressing this problem, this paper presents a new framework we refer to as Federated Contrastive Learning of Graph-level Representations (FCLG). As the name suggests, our approach builds on contrastive learning. However, what is unique is that we apply contrastive learning at two levels. The first application is for local unsupervised learning of graph representations. The second level is to address the challenge associated with data distribution variation (i.e. the ``Non-IID issue") when combining local models. Through extensive experiments on the downstream task of graph-level clustering, we demonstrate FCLG outperforms baselines (which apply existing federated methods on existing graph-level clustering methods) with significant margins.
SmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile
Apr 21, 2024



This work is motivated by recent developments in Deep Neural Networks, particularly the Transformer architectures underlying applications such as ChatGPT, and the need for performing inference on mobile devices. Focusing on emerging transformers (specifically the ones with computationally efficient Swin-like architectures) and large models (e.g., Stable Diffusion and LLMs) based on transformers, we observe that layout transformations between the computational operators cause a significant slowdown in these applications. This paper presents SmartMem, a comprehensive framework for eliminating most layout transformations, with the idea that multiple operators can use the same tensor layout through careful choice of layout and implementation of operations. Our approach is based on classifying the operators into four groups, and considering combinations of producer-consumer edges between the operators. We develop a set of methods for searching such layouts. Another component of our work is developing efficient memory layouts for 2.5 dimensional memory commonly seen in mobile devices. Our experimental results show that SmartMem outperforms 5 state-of-the-art DNN execution frameworks on mobile devices across 18 varied neural networks, including CNNs, Transformers with both local and global attention, as well as LLMs. In particular, compared to DNNFusion, SmartMem achieves an average speedup of 2.8$\times$, and outperforms TVM and MNN with speedups of 6.9$\times$ and 7.9$\times$, respectively, on average.
SoD$^2$: Statically Optimizing Dynamic Deep Neural Network
Feb 29, 2024Though many compilation and runtime systems have been developed for DNNs in recent years, the focus has largely been on static DNNs. Dynamic DNNs, where tensor shapes and sizes and even the set of operators used are dependent upon the input and/or execution, are becoming common. This paper presents SoD$^2$, a comprehensive framework for optimizing Dynamic DNNs. The basis of our approach is a classification of common operators that form DNNs, and the use of this classification towards a Rank and Dimension Propagation (RDP) method. This framework statically determines the shapes of operators as known constants, symbolic constants, or operations on these. Next, using RDP we enable a series of optimizations, like fused code generation, execution (order) planning, and even runtime memory allocation plan generation. By evaluating the framework on 10 emerging Dynamic DNNs and comparing it against several existing systems, we demonstrate both reductions in execution latency and memory requirements, with RDP-enabled key optimizations responsible for much of the gains. Our evaluation results show that SoD$^2$ runs up to $3.9\times$ faster than these systems while saving up to $88\%$ peak memory consumption.
Scalable Deep Graph Clustering with Random-walk based Self-supervised Learning
Dec 31, 2021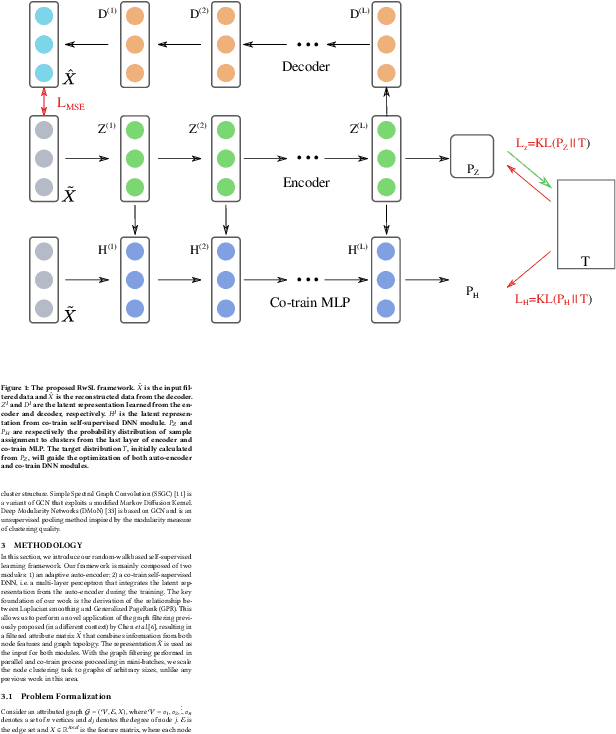

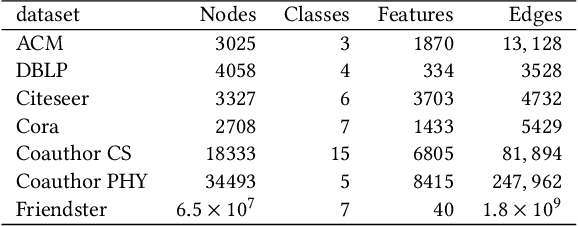
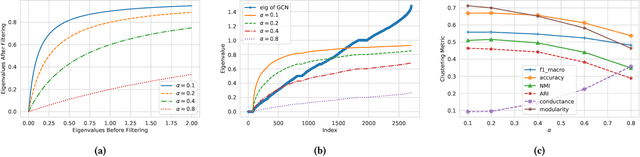
Web-based interactions can be frequently represented by an attributed graph, and node clustering in such graphs has received much attention lately. Multiple efforts have successfully applied Graph Convolutional Networks (GCN), though with some limits on accuracy as GCNs have been shown to suffer from over-smoothing issues. Though other methods (particularly those based on Laplacian Smoothing) have reported better accuracy, a fundamental limitation of all the work is a lack of scalability. This paper addresses this open problem by relating the Laplacian smoothing to the Generalized PageRank and applying a random-walk based algorithm as a scalable graph filter. This forms the basis for our scalable deep clustering algorithm, RwSL, where through a self-supervised mini-batch training mechanism, we simultaneously optimize a deep neural network for sample-cluster assignment distribution and an autoencoder for a clustering-oriented embedding. Using 6 real-world datasets and 6 clustering metrics, we show that RwSL achieved improved results over several recent baselines. Most notably, we show that RwSL, unlike all other deep clustering frameworks, can continue to scale beyond graphs with more than one million nodes, i.e., handle web-scale. We also demonstrate how RwSL could perform node clustering on a graph with 1.8 billion edges using only a single GPU.
DNNFusion: Accelerating Deep Neural Networks Execution with Advanced Operator Fusion
Aug 30, 2021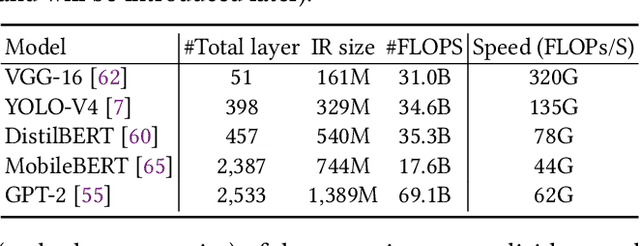
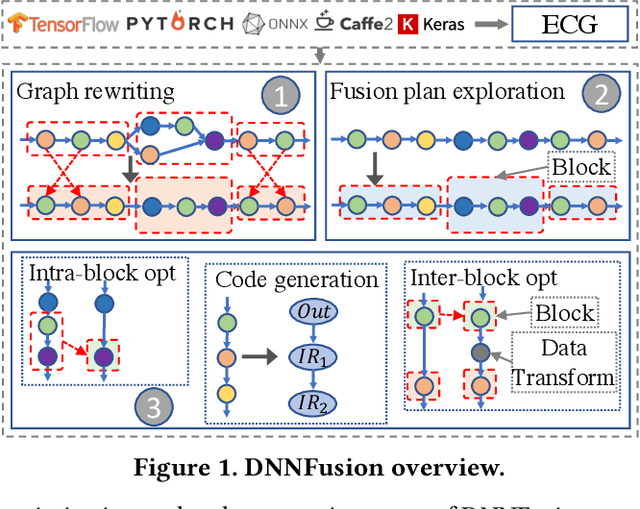

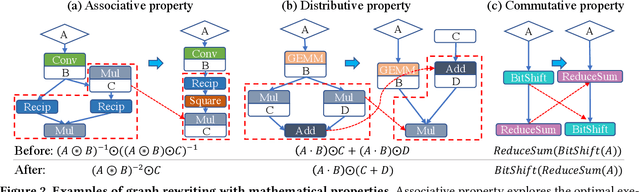
Deep Neural Networks (DNNs) have emerged as the core enabler of many major applications on mobile devices. To achieve high accuracy, DNN models have become increasingly deep with hundreds or even thousands of operator layers, leading to high memory and computational requirements for inference. Operator fusion (or kernel/layer fusion) is key optimization in many state-of-the-art DNN execution frameworks, such as TensorFlow, TVM, and MNN. However, these frameworks usually adopt fusion approaches based on certain patterns that are too restrictive to cover the diversity of operators and layer connections. Polyhedral-based loop fusion techniques, on the other hand, work on a low-level view of the computation without operator-level information, and can also miss potential fusion opportunities. To address this challenge, this paper proposes a novel and extensive loop fusion framework called DNNFusion. The basic idea of this work is to work at an operator view of DNNs, but expand fusion opportunities by developing a classification of both individual operators and their combinations. In addition, DNNFusion includes 1) a novel mathematical-property-based graph rewriting framework to reduce evaluation costs and facilitate subsequent operator fusion, 2) an integrated fusion plan generation that leverages the high-level analysis and accurate light-weight profiling, and 3) additional optimizations during fusion code generation. DNNFusion is extensively evaluated on 15 DNN models with varied types of tasks, model sizes, and layer counts. The evaluation results demonstrate that DNNFusion finds up to 8.8x higher fusion opportunities, outperforms four state-of-the-art DNN execution frameworks with 9.3x speedup. The memory requirement reduction and speedups can enable the execution of many of the target models on mobile devices and even make them part of a real-time application.
Adaptive Periodic Averaging: A Practical Approach to Reducing Communication in Distributed Learning
Jul 13, 2020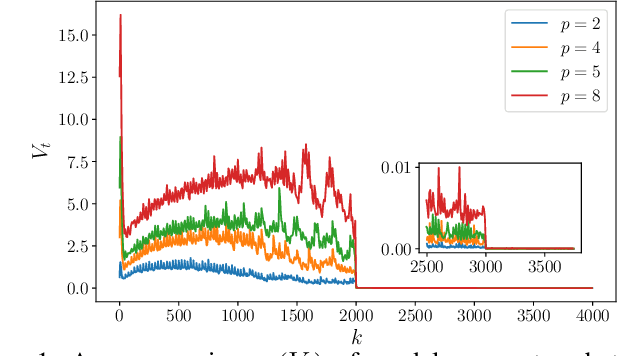
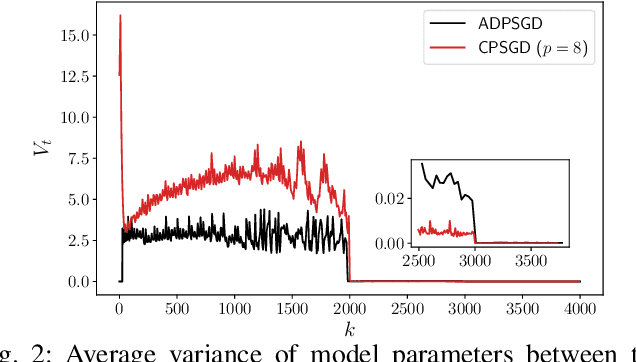
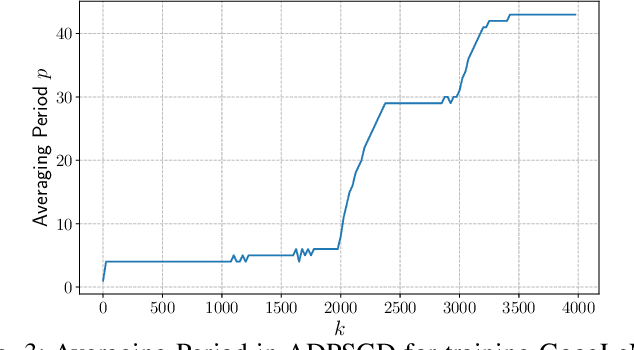
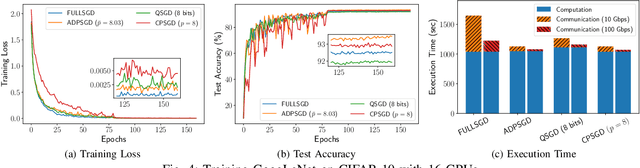
Stochastic Gradient Descent (SGD) is the key learning algorithm for many machine learning tasks. Because of its computational costs, there is a growing interest in accelerating SGD on HPC resources like GPU clusters. However, the performance of parallel SGD is still bottlenecked by the high communication costs even with a fast connection among the machines. A simple approach to alleviating this problem, used in many existing efforts, is to perform communication every few iterations, using a constant averaging period. In this paper, we show that the optimal averaging period in terms of convergence and communication cost is not a constant, but instead varies over the course of the execution. Specifically, we observe that reducing the variance of model parameters among the computing nodes is critical to the convergence of periodic parameter averaging SGD. Given a fixed communication budget, we show that it is more beneficial to synchronize more frequently in early iterations to reduce the initial large variance and synchronize less frequently in the later phase of the training process. We propose a practical algorithm, named ADaptive Periodic parameter averaging SGD (ADPSGD), to achieve a smaller overall variance of model parameters, and thus better convergence compared with the Constant Periodic parameter averaging SGD (CPSGD). We evaluate our method with several image classification benchmarks and show that our ADPSGD indeed achieves smaller training losses and higher test accuracies with smaller communication compared with CPSGD. Compared with gradient-quantization SGD, we show that our algorithm achieves faster convergence with only half of the communication. Compared with full-communication SGD, our ADPSGD achieves 1:14x to 1:27x speedups with a 100Gbps connection among computing nodes, and the speedups increase to 1:46x ~ 1:95x with a 10Gbps connection.
Towards Successful Social Media Advertising: Predicting the Influence of Commercial Tweets
Oct 28, 2019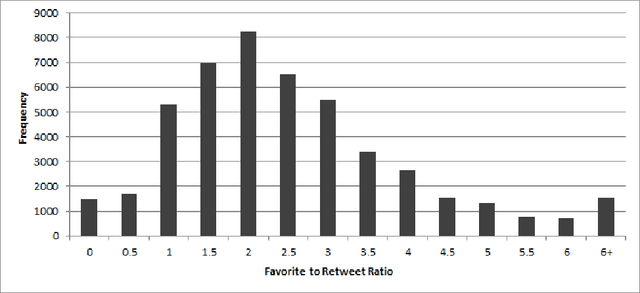
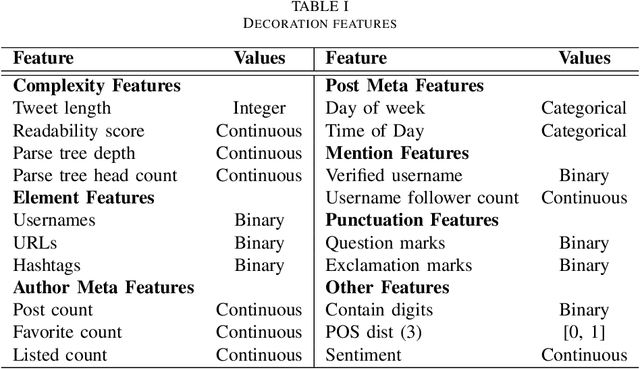
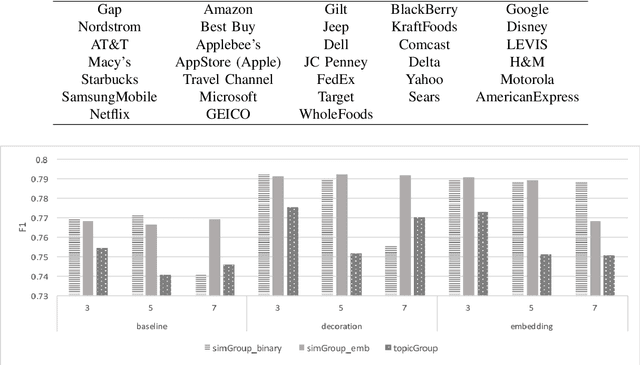
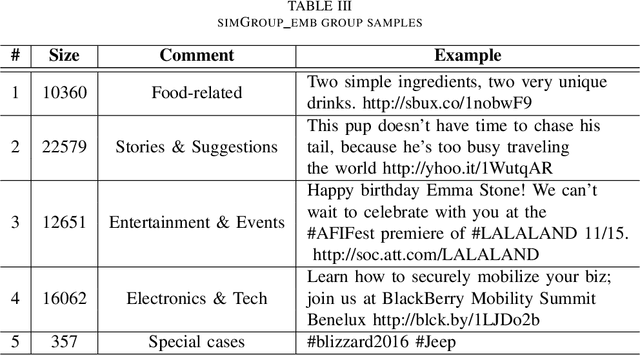
Businesses communicate using Twitter for a variety of reasons -- to raise awareness of their brands, to market new products, to respond to community comments, and to connect with their customers and potential customers in a targeted manner. For businesses to do this effectively, they need to understand which content and structural elements about a tweet make it influential, that is, widely liked, followed, and retweeted. This paper presents a systematic methodology for analyzing commercial tweets, and predicting the influence on their readers. Our model, which use a combination of decoration and meta features, outperforms the prediction ability of the baseline model as well as the tweet embedding model. Further, in order to demonstrate a practical use of this work, we show how an unsuccessful tweet may be engineered (for example, reworded) to increase its potential for success.