 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplaxel: Efficient Distributed Training of 3D Gaussian Splatting for Large-scale Scene Reconstruction via Pixel-level Communication
Jun 17, 20263D Gaussian Splatting (3DGS) enables high-fidelity and real-time 3D scene reconstruction, but scaling training to large-scale scenes requires optimizing hundreds of millions of Gaussians across multiple GPUs. Existing distributed approaches either partition scenes into isolated regions, causing global inconsistency, or rely on global Gaussian-level exchanges, which lead to substantial growth in inter-GPU communication and quickly dominate iteration time. We propose Splaxel, a communication-efficient distributed 3DGS training framework based on pixel-level local rendering and global composition. Instead of synchronizing Gaussians, each GPU renders its local subset and exchanges only partial pixel values, maintaining mathematical consistency while keeping communication cost stable as the scene size increases. Splaxel further reduces pixel-level redundancy through geometric and transmittance visibility prediction and improves GPU utilization via conflict-free camera-view consolidation. Evaluated on large-scale datasets with up to 120M Gaussians, Splaxel achieves up to 7.6$\times$ speedup over the state-of-the-art distributed 3DGS framework while preserving high reconstruction quality.
Gaussians on a Diet: High-Quality Memory-Bounded 3D Gaussian Splatting Training
Apr 21, 20263D Gaussian Splatting (3DGS) has revolutionized novel view synthesis with high-quality rendering through continuous aggregations of millions of 3D Gaussian primitives. However, it suffers from a substantial memory footprint, particularly during training due to uncontrolled densification, posing a critical bottleneck for deployment on memory-constrained edge devices. While existing methods prune redundant Gaussians post-training, they fail to address the peak memory spikes caused by the abrupt growth of Gaussians early in the training process. To solve the training memory consumption problem, we propose a systematic memory-bounded training framework that dynamically optimizes Gaussians through iterative growth and pruning. In other words, the proposed framework alternates between incremental pruning of low-impact Gaussians and strategic growing of new primitives with an adaptive Gaussian compensation, maintaining a near-constant low memory usage while progressively refining rendering fidelity. We comprehensively evaluate the proposed training framework on various real-world datasets under strict memory constraints, showing significant improvements over existing state-of-the-art methods. Particularly, our proposed method practically enables memory-efficient 3DGS training on NVIDIA Jetson AGX Xavier, achieving similar visual quality with up to 80% lower peak training memory consumption than the original 3DGS.
FlashMem: Supporting Modern DNN Workloads on Mobile with GPU Memory Hierarchy Optimizations
Feb 17, 2026The increasing size and complexity of modern deep neural networks (DNNs) pose significant challenges for on-device inference on mobile GPUs, with limited memory and computational resources. Existing DNN acceleration frameworks primarily deploy a weight preloading strategy, where all model parameters are loaded into memory before execution on mobile GPUs. We posit that this approach is not adequate for modern DNN workloads that comprise very large model(s) and possibly execution of several distinct models in succession. In this work, we introduce FlashMem, a memory streaming framework designed to efficiently execute large-scale modern DNNs and multi-DNN workloads while minimizing memory consumption and reducing inference latency. Instead of fully preloading weights, FlashMem statically determines model loading schedules and dynamically streams them on demand, leveraging 2.5D texture memory to minimize data transformations and improve execution efficiency. Experimental results on 11 models demonstrate that FlashMem achieves 2.0x to 8.4x memory reduction and 1.7x to 75.0x speedup compared to existing frameworks, enabling efficient execution of large-scale models and multi-DNN support on resource-constrained mobile GPUs.
CoSA: Compressed Sensing-Based Adaptation of Large Language Models
Feb 05, 2026Parameter-Efficient Fine-Tuning (PEFT) has emerged as a practical paradigm for adapting large language models (LLMs) without updating all parameters. Most existing approaches, such as LoRA and PiSSA, rely on low-rank decompositions of weight updates. However, the low-rank assumption may restrict expressivity, particularly in task-specific adaptation scenarios where singular values are distributed relatively uniformly. To address this limitation, we propose CoSA (Compressed Sensing-Based Adaptation), a new PEFT method extended from compressed sensing theory. Instead of constraining weight updates to a low-rank subspace, CoSA expresses them through fixed random projection matrices and a compact learnable core. We provide a formal theoretical analysis of CoSA as a synthesis process, proving that weight updates can be compactly encoded into a low-dimensional space and mapped back through random projections. Extensive experimental results show that CoSA provides a principled perspective for efficient and expressive multi-scale model adaptation. Specifically, we evaluate CoSA on 10 diverse tasks, including natural language understanding and generation, employing 5 models of different scales from RoBERTa, Llama, and Qwen families. Across these settings, CoSA consistently matches or outperforms state-of-the-art PEFT methods.
Event-VStream: Event-Driven Real-Time Understanding for Long Video Streams
Jan 22, 2026Real-time understanding of long video streams remains challenging for multimodal large language models (VLMs) due to redundant frame processing and rapid forgetting of past context. Existing streaming systems rely on fixed-interval decoding or cache pruning, which either produce repetitive outputs or discard crucial temporal information. We introduce Event-VStream, an event-aware framework that represents continuous video as a sequence of discrete, semantically coherent events. Our system detects meaningful state transitions by integrating motion, semantic, and predictive cues, and triggers language generation only at those boundaries. Each event embedding is consolidated into a persistent memory bank, enabling long-horizon reasoning while maintaining low latency. Across OVOBench-Realtime, and long-form Ego4D evaluations, Event-VStream achieves competitive performance. It improves over a VideoLLM-Online-8B baseline by +10.4 points on OVOBench-Realtime, achieves performance close to Flash-VStream-7B despite using only a general-purpose LLaMA-3-8B text backbone, and maintains around 70% GPT-5 win rate on 2-hour Ego4D streams.
AdaCM$^2$: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
Nov 19, 2024The advancements in large language models (LLMs) have propelled the improvement of video understanding tasks by incorporating LLMs with visual models. However, most existing LLM-based models (e.g., VideoLLaMA, VideoChat) are constrained to processing short-duration videos. Recent attempts to understand long-term videos by extracting and compressing visual features into a fixed memory size. Nevertheless, those methods leverage only visual modality to merge video tokens and overlook the correlation between visual and textual queries, leading to difficulties in effectively handling complex question-answering tasks. To address the challenges of long videos and complex prompts, we propose AdaCM$^2$, which, for the first time, introduces an adaptive cross-modality memory reduction approach to video-text alignment in an auto-regressive manner on video streams. Our extensive experiments on various video understanding tasks, such as video captioning, video question answering, and video classification, demonstrate that AdaCM$^2$ achieves state-of-the-art performance across multiple datasets while significantly reducing memory usage. Notably, it achieves a 4.5% improvement across multiple tasks in the LVU dataset with a GPU memory consumption reduction of up to 65%.
GaussianSpa: An "Optimizing-Sparsifying" Simplification Framework for Compact and High-Quality 3D Gaussian Splatting
Nov 09, 2024



3D Gaussian Splatting (3DGS) has emerged as a mainstream for novel view synthesis, leveraging continuous aggregations of Gaussian functions to model scene geometry. However, 3DGS suffers from substantial memory requirements to store the multitude of Gaussians, hindering its practicality. To address this challenge, we introduce GaussianSpa, an optimization-based simplification framework for compact and high-quality 3DGS. Specifically, we formulate the simplification as an optimization problem associated with the 3DGS training. Correspondingly, we propose an efficient "optimizing-sparsifying" solution that alternately solves two independent sub-problems, gradually imposing strong sparsity onto the Gaussians in the training process. Our comprehensive evaluations on various datasets show the superiority of GaussianSpa over existing state-of-the-art approaches. Notably, GaussianSpa achieves an average PSNR improvement of 0.9 dB on the real-world Deep Blending dataset with 10$\times$ fewer Gaussians compared to the vanilla 3DGS. Our project page is available at https://gaussianspa.github.io/.
MoE-I$^2$: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Nov 01, 2024

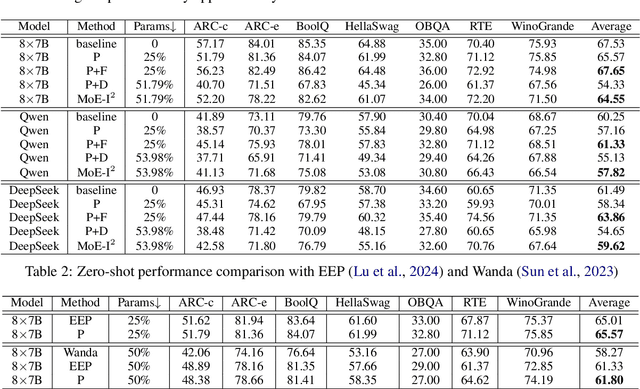
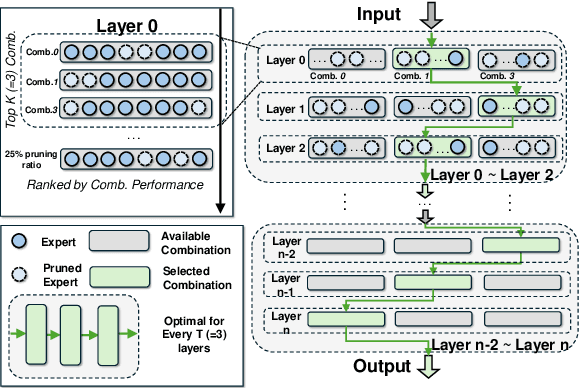
The emergence of Mixture of Experts (MoE) LLMs has significantly advanced the development of language models. Compared to traditional LLMs, MoE LLMs outperform traditional LLMs by achieving higher performance with considerably fewer activated parameters. Despite this efficiency, their enormous parameter size still leads to high deployment costs. In this paper, we introduce a two-stage compression method tailored for MoE to reduce the model size and decrease the computational cost. First, in the inter-expert pruning stage, we analyze the importance of each layer and propose the Layer-wise Genetic Search and Block-wise KT-Reception Field with the non-uniform pruning ratio to prune the individual expert. Second, in the intra-expert decomposition stage, we apply the low-rank decomposition to further compress the parameters within the remaining experts. Extensive experiments on Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite, and Mixtral-8$\times$7B demonstrate that our proposed methods can both reduce the model size and enhance inference efficiency while maintaining performance in various zero-shot tasks. The code will be available at \url{https://github.com/xiaochengsky/MoEI-2.git}
Enhancing Lossy Compression Through Cross-Field Information for Scientific Applications
Sep 26, 2024



Lossy compression is one of the most effective methods for reducing the size of scientific data containing multiple data fields. It reduces information density through prediction or transformation techniques to compress the data. Previous approaches use local information from a single target field when predicting target data points, limiting their potential to achieve higher compression ratios. In this paper, we identified significant cross-field correlations within scientific datasets. We propose a novel hybrid prediction model that utilizes CNN to extract cross-field information and combine it with existing local field information. Our solution enhances the prediction accuracy of lossy compressors, leading to improved compression ratios without compromising data quality. We evaluate our solution on three scientific datasets, demonstrating its ability to improve compression ratios by up to 25% under specific error bounds. Additionally, our solution preserves more data details and reduces artifacts compared to baseline approaches.
NeurLZ: On Enhancing Lossy Compression Performance based on Error-Controlled Neural Learning for Scientific Data
Sep 10, 2024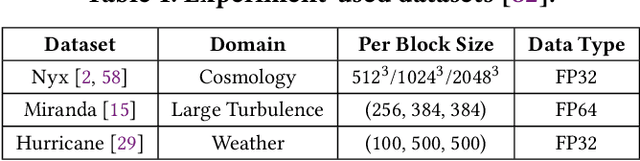



Large-scale scientific simulations generate massive datasets that pose significant challenges for storage and I/O. While traditional lossy compression techniques can improve performance, balancing compression ratio, data quality, and throughput remains difficult. To address this, we propose NeurLZ, a novel cross-field learning-based and error-controlled compression framework for scientific data. By integrating skipping DNN models, cross-field learning, and error control, our framework aims to substantially enhance lossy compression performance. Our contributions are three-fold: (1) We design a lightweight skipping model to provide high-fidelity detail retention, further improving prediction accuracy. (2) We adopt a cross-field learning approach to significantly improve data prediction accuracy, resulting in a substantially improved compression ratio. (3) We develop an error control approach to provide strict error bounds according to user requirements. We evaluated NeurLZ on several real-world HPC application datasets, including Nyx (cosmological simulation), Miranda (large turbulence simulation), and Hurricane (weather simulation). Experiments demonstrate that our framework achieves up to a 90% relative reduction in bit rate under the same data distortion, compared to the best existing approach.