 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMem: Supporting Modern DNN Workloads on Mobile with GPU Memory Hierarchy Optimizations
Feb 17, 2026The increasing size and complexity of modern deep neural networks (DNNs) pose significant challenges for on-device inference on mobile GPUs, with limited memory and computational resources. Existing DNN acceleration frameworks primarily deploy a weight preloading strategy, where all model parameters are loaded into memory before execution on mobile GPUs. We posit that this approach is not adequate for modern DNN workloads that comprise very large model(s) and possibly execution of several distinct models in succession. In this work, we introduce FlashMem, a memory streaming framework designed to efficiently execute large-scale modern DNNs and multi-DNN workloads while minimizing memory consumption and reducing inference latency. Instead of fully preloading weights, FlashMem statically determines model loading schedules and dynamically streams them on demand, leveraging 2.5D texture memory to minimize data transformations and improve execution efficiency. Experimental results on 11 models demonstrate that FlashMem achieves 2.0x to 8.4x memory reduction and 1.7x to 75.0x speedup compared to existing frameworks, enabling efficient execution of large-scale models and multi-DNN support on resource-constrained mobile GPUs.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.
Data Overfitting for On-Device Super-Resolution with Dynamic Algorithm and Compiler Co-Design
Jul 03, 2024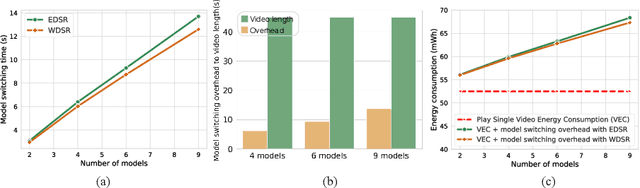

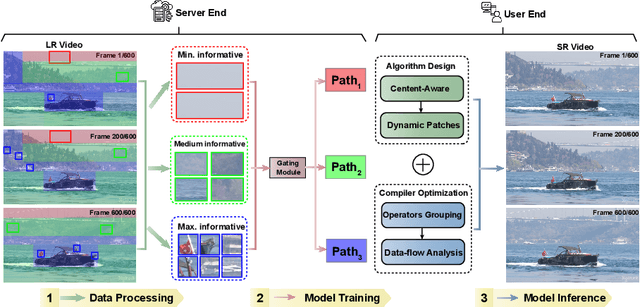
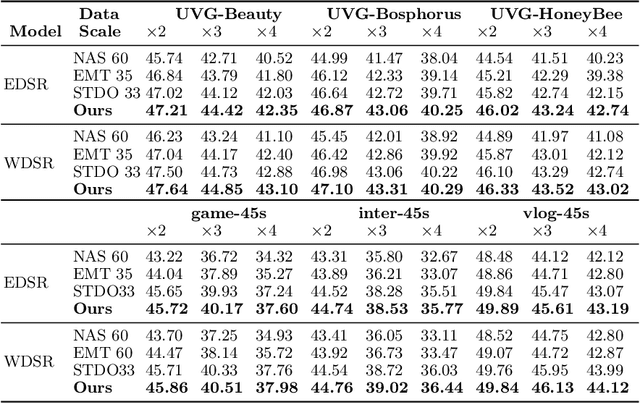
Deep neural networks (DNNs) are frequently employed in a variety of computer vision applications. Nowadays, an emerging trend in the current video distribution system is to take advantage of DNN's overfitting properties to perform video resolution upscaling. By splitting videos into chunks and applying a super-resolution (SR) model to overfit each chunk, this scheme of SR models plus video chunks is able to replace traditional video transmission to enhance video quality and transmission efficiency. However, many models and chunks are needed to guarantee high performance, which leads to tremendous overhead on model switching and memory footprints at the user end. To resolve such problems, we propose a Dynamic Deep neural network assisted by a Content-Aware data processing pipeline to reduce the model number down to one (Dy-DCA), which helps promote performance while conserving computational resources. Additionally, to achieve real acceleration on the user end, we designed a framework that optimizes dynamic features (e.g., dynamic shapes, sizes, and control flow) in Dy-DCA to enable a series of compilation optimizations, including fused code generation, static execution planning, etc. By employing such techniques, our method achieves better PSNR and real-time performance (33 FPS) on an off-the-shelf mobile phone. Meanwhile, assisted by our compilation optimization, we achieve a 1.7$\times$ speedup while saving up to 1.61$\times$ memory consumption. Code available in https://github.com/coulsonlee/Dy-DCA-ECCV2024.
SmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile
Apr 21, 2024



This work is motivated by recent developments in Deep Neural Networks, particularly the Transformer architectures underlying applications such as ChatGPT, and the need for performing inference on mobile devices. Focusing on emerging transformers (specifically the ones with computationally efficient Swin-like architectures) and large models (e.g., Stable Diffusion and LLMs) based on transformers, we observe that layout transformations between the computational operators cause a significant slowdown in these applications. This paper presents SmartMem, a comprehensive framework for eliminating most layout transformations, with the idea that multiple operators can use the same tensor layout through careful choice of layout and implementation of operations. Our approach is based on classifying the operators into four groups, and considering combinations of producer-consumer edges between the operators. We develop a set of methods for searching such layouts. Another component of our work is developing efficient memory layouts for 2.5 dimensional memory commonly seen in mobile devices. Our experimental results show that SmartMem outperforms 5 state-of-the-art DNN execution frameworks on mobile devices across 18 varied neural networks, including CNNs, Transformers with both local and global attention, as well as LLMs. In particular, compared to DNNFusion, SmartMem achieves an average speedup of 2.8$\times$, and outperforms TVM and MNN with speedups of 6.9$\times$ and 7.9$\times$, respectively, on average.
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.