 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK12-KGraph: A Curriculum-Aligned Knowledge Graph for Benchmarking and Training Educational LLMs
May 10, 2026Large language models (LLMs) are increasingly used in K-12 education, yet existing benchmarks such as C-Eval, CMMLU, GaokaoBench, and EduEval mainly evaluate factual recall through exam-style question answering. Effective educational AI additionally requires curriculum cognition: understanding how knowledge is structured through prerequisite chains, concept taxonomies, experiment-concept links, and pedagogical sequencing. To address this gap, we introduce K12-KGraph, a curriculum-aligned knowledge graph extracted from official People's Education Press textbooks across mathematics, physics, chemistry, and biology from primary to high school. The graph contains seven node types (Concept, Skill, Experiment, Exercise, Section, Chapter, Book) and nine relation types covering taxonomy, prerequisite, association, verification, assessment, location, and order. Based on this graph, we construct two resources: (1) K12-Bench, a 23,640-question multi-select benchmark spanning five graph-derived task families (Ground, Prereq, Neighbor, Evidence, and Locate); and (2) K12-Train, a KG-guided supervised fine-tuning corpus of approximately 2,300 QA pairs synthesized from graph structure and node attributes. Experiments reveal substantial deficiencies in curriculum cognition: on K12-Bench, Gemini-3-Flash achieves only 57% exact match, while the best open-source model, Gemma-4-31B-IT, reaches 46%. Under a strictly matched 2,300-sample SFT budget on Qwen3-4B-Base and Llama-3.1-8B-Base, K12-Train consistently outperforms equally sized subsets from eight mainstream instruction-tuning corpora on both GaokaoBench and EduEval, demonstrating that curriculum-structured supervision is highly sample-efficient for educational tuning. We release the graph, benchmark, training data, and full construction pipeline.
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
Towards Next-Generation LLM Training: From the Data-Centric Perspective
Mar 16, 2026Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks and domains, with data playing a central role in enabling these advances. Despite this success, the preparation and effective utilization of the massive datasets required for LLM training remain major bottlenecks. In current practice, LLM training data is often constructed using ad hoc scripts, and there is still a lack of mature, agent-based data preparation systems that can automatically construct robust and reusable data workflows, thereby freeing data scientists from repetitive and error-prone engineering efforts. Moreover, once collected, datasets are often consumed largely in their entirety during training, without systematic mechanisms for data selection, mixture optimization, or reweighting. To address these limitations, we advocate two complementary research directions. First, we propose building a robust, agent-based automatic data preparation system that supports automated workflow construction and scalable data management. Second, we argue for a unified data-model interaction training system in which data is dynamically selected, mixed, and reweighted throughout the training process, enabling more efficient, adaptive, and performance-aware data utilization. Finally, we discuss the remaining challenges and outline promising directions for future research and system development.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
LoVR: A Benchmark for Long Video Retrieval in Multimodal Contexts
May 20, 2025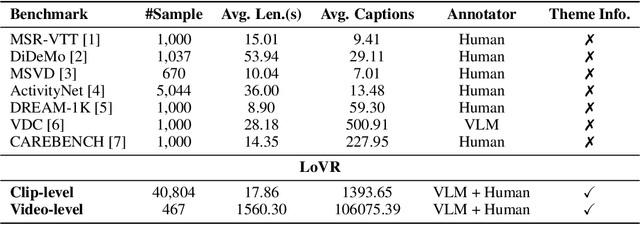

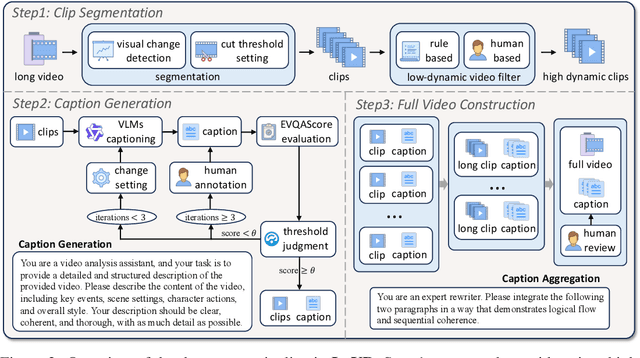
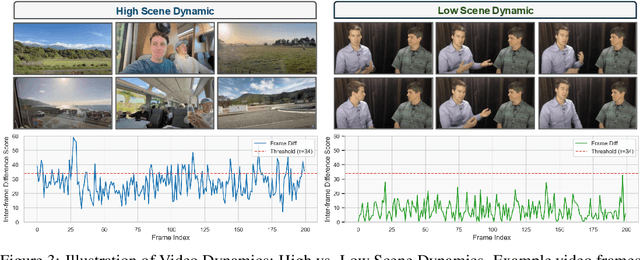
Long videos contain a vast amount of information, making video-text retrieval an essential and challenging task in multimodal learning. However, existing benchmarks suffer from limited video duration, low-quality captions, and coarse annotation granularity, which hinder the evaluation of advanced video-text retrieval methods. To address these limitations, we introduce LoVR, a benchmark specifically designed for long video-text retrieval. LoVR contains 467 long videos and over 40,804 fine-grained clips with high-quality captions. To overcome the issue of poor machine-generated annotations, we propose an efficient caption generation framework that integrates VLM automatic generation, caption quality scoring, and dynamic refinement. This pipeline improves annotation accuracy while maintaining scalability. Furthermore, we introduce a semantic fusion method to generate coherent full-video captions without losing important contextual information. Our benchmark introduces longer videos, more detailed captions, and a larger-scale dataset, presenting new challenges for video understanding and retrieval. Extensive experiments on various advanced embedding models demonstrate that LoVR is a challenging benchmark, revealing the limitations of current approaches and providing valuable insights for future research. We release the code and dataset link at https://github.com/TechNomad-ds/LoVR-benchmark
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.
Punctuation Matters! Stealthy Backdoor Attack for Language Models
Dec 26, 2023Recent studies have pointed out that natural language processing (NLP) models are vulnerable to backdoor attacks. A backdoored model produces normal outputs on the clean samples while performing improperly on the texts with triggers that the adversary injects. However, previous studies on textual backdoor attack pay little attention to stealthiness. Moreover, some attack methods even cause grammatical issues or change the semantic meaning of the original texts. Therefore, they can easily be detected by humans or defense systems. In this paper, we propose a novel stealthy backdoor attack method against textual models, which is called \textbf{PuncAttack}. It leverages combinations of punctuation marks as the trigger and chooses proper locations strategically to replace them. Through extensive experiments, we demonstrate that the proposed method can effectively compromise multiple models in various tasks. Meanwhile, we conduct automatic evaluation and human inspection, which indicate the proposed method possesses good performance of stealthiness without bringing grammatical issues and altering the meaning of sentences.
A Survey on Backdoor Attack and Defense in Natural Language Processing
Nov 22, 2022



Deep learning is becoming increasingly popular in real-life applications, especially in natural language processing (NLP). Users often choose training outsourcing or adopt third-party data and models due to data and computation resources being limited. In such a situation, training data and models are exposed to the public. As a result, attackers can manipulate the training process to inject some triggers into the model, which is called backdoor attack. Backdoor attack is quite stealthy and difficult to be detected because it has little inferior influence on the model's performance for the clean samples. To get a precise grasp and understanding of this problem, in this paper, we conduct a comprehensive review of backdoor attacks and defenses in the field of NLP. Besides, we summarize benchmark datasets and point out the open issues to design credible systems to defend against backdoor attacks.
PromptAttack: Prompt-based Attack for Language Models via Gradient Search
Sep 05, 2022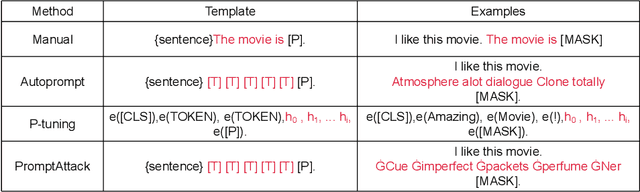

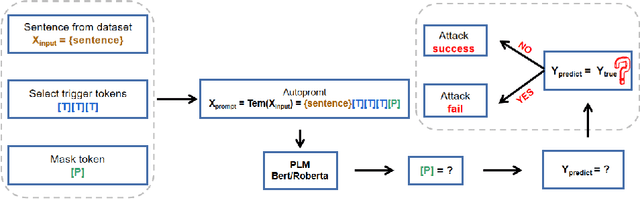

As the pre-trained language models (PLMs) continue to grow, so do the hardware and data requirements for fine-tuning PLMs. Therefore, the researchers have come up with a lighter method called \textit{Prompt Learning}. However, during the investigations, we observe that the prompt learning methods are vulnerable and can easily be attacked by some illegally constructed prompts, resulting in classification errors, and serious security problems for PLMs. Most of the current research ignores the security issue of prompt-based methods. Therefore, in this paper, we propose a malicious prompt template construction method (\textbf{PromptAttack}) to probe the security performance of PLMs. Several unfriendly template construction approaches are investigated to guide the model to misclassify the task. Extensive experiments on three datasets and three PLMs prove the effectiveness of our proposed approach PromptAttack. We also conduct experiments to verify that our method is applicable in few-shot scenarios.