 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptAttack: Prompt-based Attack for Language Models via Gradient Search
Paper and Code
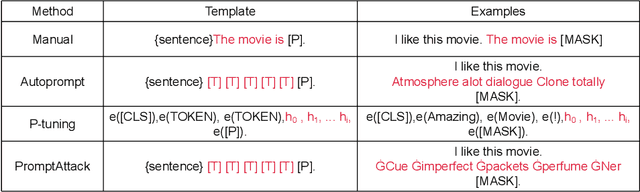

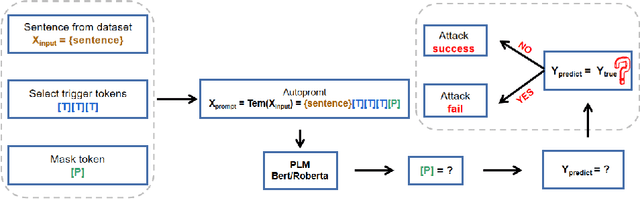

As the pre-trained language models (PLMs) continue to grow, so do the hardware and data requirements for fine-tuning PLMs. Therefore, the researchers have come up with a lighter method called \textit{Prompt Learning}. However, during the investigations, we observe that the prompt learning methods are vulnerable and can easily be attacked by some illegally constructed prompts, resulting in classification errors, and serious security problems for PLMs. Most of the current research ignores the security issue of prompt-based methods. Therefore, in this paper, we propose a malicious prompt template construction method (\textbf{PromptAttack}) to probe the security performance of PLMs. Several unfriendly template construction approaches are investigated to guide the model to misclassify the task. Extensive experiments on three datasets and three PLMs prove the effectiveness of our proposed approach PromptAttack. We also conduct experiments to verify that our method is applicable in few-shot scenarios.