 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL-OTA: Unveiling Backdoor Threats in Self-Supervised Learning for Object Detection
Dec 30, 2023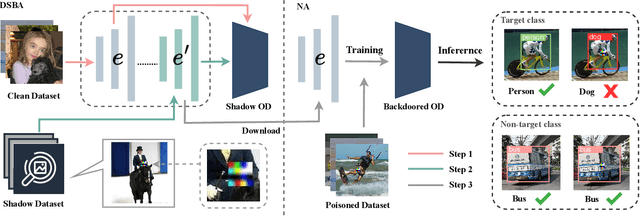

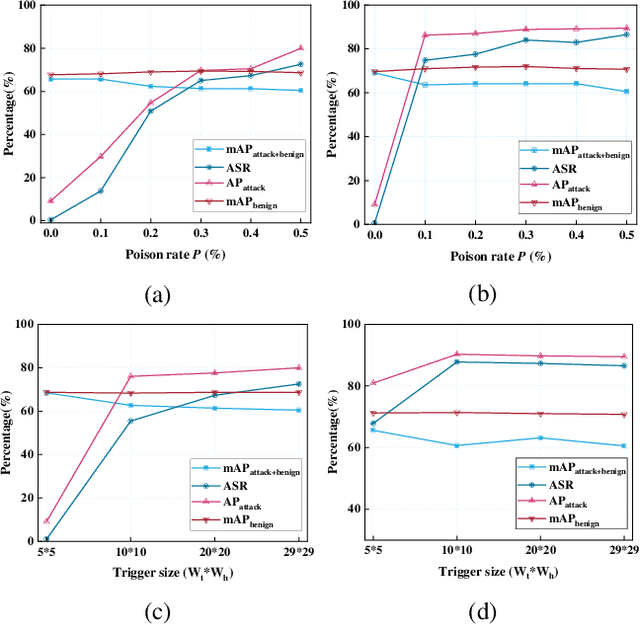
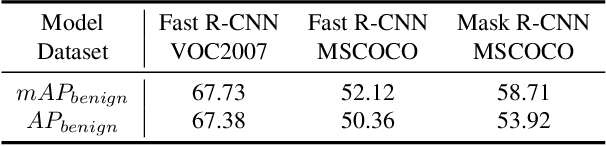
The extensive adoption of Self-supervised learning (SSL) has led to an increased security threat from backdoor attacks. While existing research has mainly focused on backdoor attacks in image classification, there has been limited exploration into their implications for object detection. In this work, we propose the first backdoor attack designed for object detection tasks in SSL scenarios, termed Object Transform Attack (SSL-OTA). SSL-OTA employs a trigger capable of altering predictions of the target object to the desired category, encompassing two attacks: Data Poisoning Attack (NA) and Dual-Source Blending Attack (DSBA). NA conducts data poisoning during downstream fine-tuning of the object detector, while DSBA additionally injects backdoors into the pre-trained encoder. We establish appropriate metrics and conduct extensive experiments on benchmark datasets, demonstrating the effectiveness and utility of our proposed attack. Notably, both NA and DSBA achieve high attack success rates (ASR) at extremely low poisoning rates (0.5%). The results underscore the importance of considering backdoor threats in SSL-based object detection and contribute a novel perspective to the field.
GhostEncoder: Stealthy Backdoor Attacks with Dynamic Triggers to Pre-trained Encoders in Self-supervised Learning
Oct 01, 2023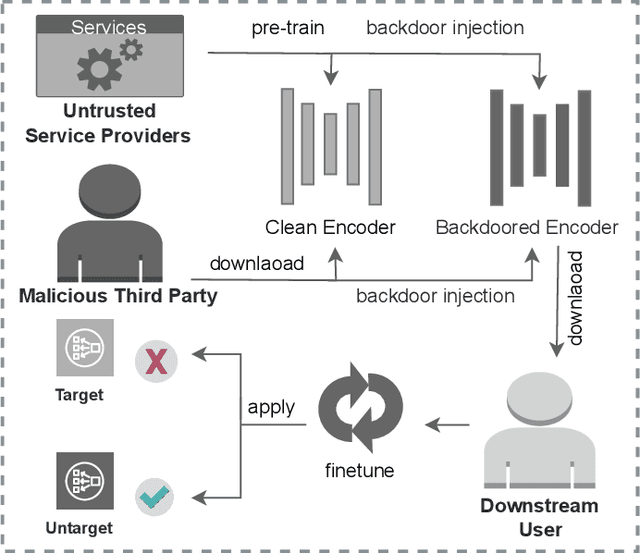

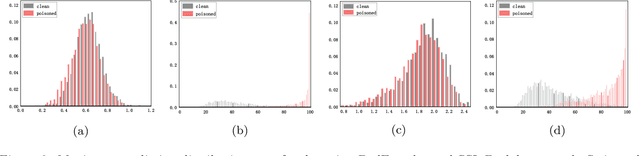
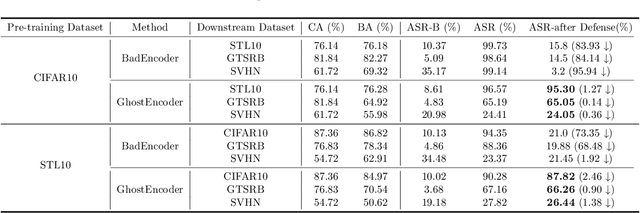
Within the realm of computer vision, self-supervised learning (SSL) pertains to training pre-trained image encoders utilizing a substantial quantity of unlabeled images. Pre-trained image encoders can serve as feature extractors, facilitating the construction of downstream classifiers for various tasks. However, the use of SSL has led to an increase in security research related to various backdoor attacks. Currently, the trigger patterns used in backdoor attacks on SSL are mostly visible or static (sample-agnostic), making backdoors less covert and significantly affecting the attack performance. In this work, we propose GhostEncoder, the first dynamic invisible backdoor attack on SSL. Unlike existing backdoor attacks on SSL, which use visible or static trigger patterns, GhostEncoder utilizes image steganography techniques to encode hidden information into benign images and generate backdoor samples. We then fine-tune the pre-trained image encoder on a manipulation dataset to inject the backdoor, enabling downstream classifiers built upon the backdoored encoder to inherit the backdoor behavior for target downstream tasks. We evaluate GhostEncoder on three downstream tasks and results demonstrate that GhostEncoder provides practical stealthiness on images and deceives the victim model with a high attack success rate without compromising its utility. Furthermore, GhostEncoder withstands state-of-the-art defenses, including STRIP, STRIP-Cl, and SSL-Cleanse.
SSL-Auth: An Authentication Framework by Fragile Watermarking for Pre-trained Encoders in Self-supervised Learning
Aug 16, 2023



Self-supervised learning (SSL), utilizing unlabeled datasets for training powerful encoders, has achieved significant success recently. These encoders serve as feature extractors for downstream tasks, requiring substantial resources. However, the challenge of protecting the intellectual property of encoder trainers and ensuring the trustworthiness of deployed encoders remains a significant gap in SSL. Moreover, recent researches highlight threats to pre-trained encoders, such as backdoor and adversarial attacks. To address these gaps, we propose SSL-Auth, the first authentication framework designed specifically for pre-trained encoders. In particular, SSL-Auth utilizes selected key samples as watermark information and trains a verification network to reconstruct the watermark information, thereby verifying the integrity of the encoder without compromising model performance. By comparing the reconstruction results of the key samples, malicious alterations can be detected, as modified encoders won't mimic the original reconstruction. Comprehensive evaluations on various encoders and diverse downstream tasks demonstrate the effectiveness and fragility of our proposed SSL-Auth.
PromptAttack: Prompt-based Attack for Language Models via Gradient Search
Sep 05, 2022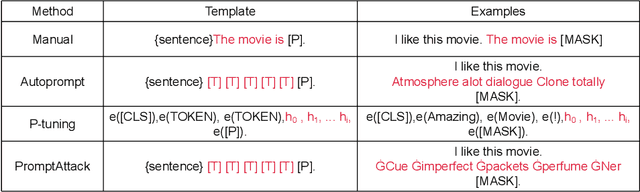

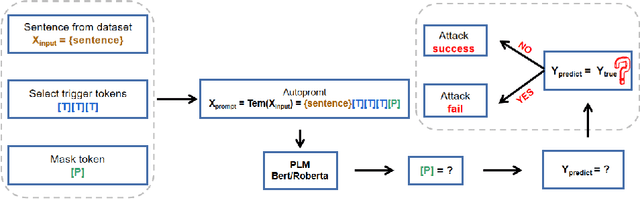

As the pre-trained language models (PLMs) continue to grow, so do the hardware and data requirements for fine-tuning PLMs. Therefore, the researchers have come up with a lighter method called \textit{Prompt Learning}. However, during the investigations, we observe that the prompt learning methods are vulnerable and can easily be attacked by some illegally constructed prompts, resulting in classification errors, and serious security problems for PLMs. Most of the current research ignores the security issue of prompt-based methods. Therefore, in this paper, we propose a malicious prompt template construction method (\textbf{PromptAttack}) to probe the security performance of PLMs. Several unfriendly template construction approaches are investigated to guide the model to misclassify the task. Extensive experiments on three datasets and three PLMs prove the effectiveness of our proposed approach PromptAttack. We also conduct experiments to verify that our method is applicable in few-shot scenarios.