 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkflow-to-Skill: Skill Creation via Routing-Workflow-Semantics-Attachments Decomposition
Jun 05, 2026Large language model agents increasingly rely on Skills to encode procedural knowledge, yet high-quality Skills remain costly to hand-write. This paper studies automatic Skill construction from heterogeneous interaction evidence, including demonstrations, agent trajectories, tool traces, and execution logs. We argue that trace-to-skill construction is not simple summarization tasks, because traces are fragmented, redundant, and may miss rare but safety-critical behaviors. To address this, we introduce RWSA, a workflow-oriented intermediate representation that decomposes Skills into Workflow structure, execution Semantics, and runtime Attachments, capturing task decomposition, control flow, verification, safety, rollback, and state management. Building on RWSA, we propose W2S, a framework that segments traces, induces local Skill drafts, aligns shared structures, reconciles branches, and compresses redundancy while preserving evidence and confidence annotations. Experiments on 70 Skills show that W2S improves behavioral replay consistency by 10.5% over summarization- and prompting-based baselines, highlighting the need to treat traces as executable runtime specifications rather than compressible text.
BioTrain: Sub-MB, Sub-50mW On-Device Fine-Tuning for Edge-AI on Biosignals
Apr 14, 2026Biosignals exhibit substantial cross-subject and cross-session variability, inducing severe domain shifts that degrade post-deployment performance for small, edge-oriented AI models. On-device adaptation is therefore essential to both preserve user privacy and ensure system reliability. However, existing sub-100 mW MCU-based wearable platforms can only support shallow or sparse adaptation schemes due to the prohibitive memory footprint and computational cost of full backpropagation (BP). In this paper, we propose BioTrain, a framework enabling full-network fine-tuning of state-of-the-art biosignal models under milliwatt-scale power and sub-megabyte memory constraints. We validate BioTrain using both offline and on-device benchmarks on EEG and EOG datasets, covering Day-1 new-subject calibration and longitudinal adaptation to signal drift. Experimental results show that full-network fine-tuning achieves accuracy improvements of up to 35% over non-adapted baselines and outperforms last-layer updates by approximately 7% during new-subject calibration. On the GAP9 MCU platform, BioTrain enables efficient on-device training throughput of 17 samples/s for EEG and 85 samples/s for EOG models within a power envelope below 50 mW. In addition, BioTrain's efficient memory allocator and network topology optimization enable the use of a large batch size, reducing peak memory usage. For fully on-chip BP on GAP9, BioTrain reduces the memory footprint by 8.1x, from 5.4 MB to 0.67 MB, compared to conventional full-network fine-tuning using batch normalization with batch size 8.
FF3R: Feedforward Feature 3D Reconstruction from Unconstrained views
Apr 10, 2026Recent advances in vision foundation models have revolutionized geometry reconstruction and semantic understanding. Yet, most of the existing approaches treat these capabilities in isolation, leading to redundant pipelines and compounded errors. This paper introduces FF3R, a fully annotation-free feed-forward framework that unifies geometric and semantic reasoning from unconstrained multi-view image sequences. Unlike previous methods, FF3R does not require camera poses, depth maps, or semantic labels, relying solely on rendering supervision for RGB and feature maps, establishing a scalable paradigm for unified 3D reasoning. In addition, we address two critical challenges in feedforward feature reconstruction pipelines, namely global semantic inconsistency and local structural inconsistency, through two key innovations: (i) a Token-wise Fusion Module that enriches geometry tokens with semantic context via cross-attention, and (ii) a Semantic-Geometry Mutual Boosting mechanism combining geometry-guided feature warping for global consistency with semantic-aware voxelization for local coherence. Extensive experiments on ScanNet and DL3DV-10K demonstrate FF3R's superior performance in novel-view synthesis, open-vocabulary semantic segmentation, and depth estimation, with strong generalization to in-the-wild scenarios, paving the way for embodied intelligence systems that demand both spatial and semantic understanding.
TrainDeeploy: Hardware-Accelerated Parameter-Efficient Fine-Tuning of Small Transformer Models at the Extreme Edge
Mar 10, 2026On-device tuning of deep neural networks enables long-term adaptation at the edge while preserving data privacy. However, the high computational and memory demands of backpropagation pose significant challenges for ultra-low-power, memory-constrained extreme-edge devices. These challenges are further amplified for attention-based models due to their architectural complexity and computational scale. We present TrainDeeploy, a framework that unifies efficient inference and on-device training on heterogeneous ultra-low-power System-on-Chips (SoCs). TrainDeeploy provides the first complete on-device training pipeline for extreme-edge SoCs supporting both Convolutional Neural Networks (CNNs) and Transformer models, together with multiple training strategies such as selective layer-wise fine-tuning and Low-Rank Adaptation (LoRA). On a RISC-V-based heterogeneous SoC, we demonstrate the first end-to-end on-device fine-tuning of a Compact Convolutional Transformer (CCT), achieving up to 11 trained images per second. We show that LoRA reduces dynamic memory usage by 23%, decreases the number of trainable parameters and gradients by 15x, and reduces memory transfer volume by 1.6x compared to full backpropagation. TrainDeeploy achieves up to 4.6 FLOP/cycle on CCT (0.28M parameters, 71-126M FLOPs) and up to 13.4 FLOP/cycle on Deep-AE (0.27M parameters, 0.8M FLOPs), while expanding the scope of prior frameworks to support both CNN and Transformer models with parameter-efficient tuning on extreme-edge platforms.
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
Jan 29, 2026High-definition (HD) maps provide essential semantic information of road structures for autonomous driving systems, yet current HD map construction methods require calibrated multi-camera setups and either implicit or explicit 2D-to-BEV transformations, making them fragile when sensors fail or camera configurations vary across vehicle fleets. We introduce FlexMap, unlike prior methods that are fixed to a specific N-camera rig, our approach adapts to variable camera configurations without any architectural changes or per-configuration retraining. Our key innovation eliminates explicit geometric projections by using a geometry-aware foundation model with cross-frame attention to implicitly encode 3D scene understanding in feature space. FlexMap features two core components: a spatial-temporal enhancement module that separates cross-view spatial reasoning from temporal dynamics, and a camera-aware decoder with latent camera tokens, enabling view-adaptive attention without the need for projection matrices. Experiments demonstrate that FlexMap outperforms existing methods across multiple configurations while maintaining robustness to missing views and sensor variations, enabling more practical real-world deployment.
Ridge partial correlation screening for ultrahigh-dimensional data
Apr 27, 2025

Variable selection in ultrahigh-dimensional linear regression is challenging due to its high computational cost. Therefore, a screening step is usually conducted before variable selection to significantly reduce the dimension. Here we propose a novel and simple screening method based on ordering the absolute sample ridge partial correlations. The proposed method takes into account not only the ridge regularized estimates of the regression coefficients but also the ridge regularized partial variances of the predictor variables providing sure screening property without strong assumptions on the marginal correlations. Simulation study and a real data analysis show that the proposed method has a competitive performance compared with the existing screening procedures. A publicly available software implementing the proposed screening accompanies the article.
VEXP: A Low-Cost RISC-V ISA Extension for Accelerated Softmax Computation in Transformers
Apr 15, 2025While Transformers are dominated by Floating-Point (FP) Matrix-Multiplications, their aggressive acceleration through dedicated hardware or many-core programmable systems has shifted the performance bottleneck to non-linear functions like Softmax. Accelerating Softmax is challenging due to its non-pointwise, non-linear nature, with exponentiation as the most demanding step. To address this, we design a custom arithmetic block for Bfloat16 exponentiation leveraging a novel approximation algorithm based on Schraudolph's method, and we integrate it into the Floating-Point Unit (FPU) of the RISC-V cores of a compute cluster, through custom Instruction Set Architecture (ISA) extensions, with a negligible area overhead of 1\%. By optimizing the software kernels to leverage the extension, we execute Softmax with 162.7$\times$ less latency and 74.3$\times$ less energy compared to the baseline cluster, achieving an 8.2$\times$ performance improvement and 4.1$\times$ higher energy efficiency for the FlashAttention-2 kernel in GPT-2 configuration. Moreover, the proposed approach enables a multi-cluster system to efficiently execute end-to-end inference of pre-trained Transformer models, such as GPT-2, GPT-3 and ViT, achieving up to 5.8$\times$ and 3.6$\times$ reduction in latency and energy consumption, respectively, without requiring re-training and with negligible accuracy loss.
Offload Rethinking by Cloud Assistance for Efficient Environmental Sound Recognition on LPWANs
Feb 21, 2025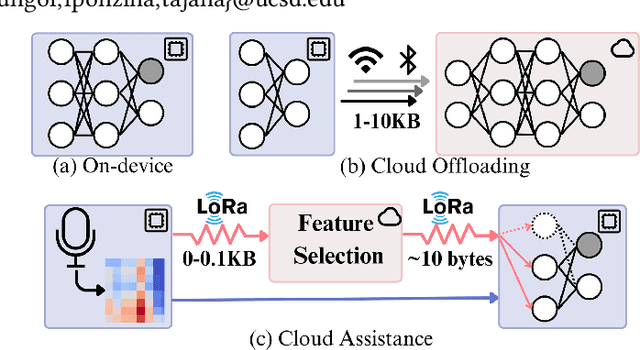


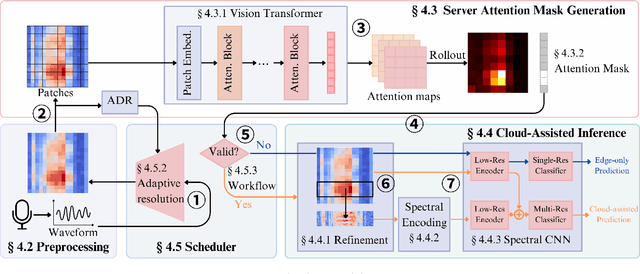
Learning-based environmental sound recognition has emerged as a crucial method for ultra-low-power environmental monitoring in biological research and city-scale sensing systems. These systems usually operate under limited resources and are often powered by harvested energy in remote areas. Recent efforts in on-device sound recognition suffer from low accuracy due to resource constraints, whereas cloud offloading strategies are hindered by high communication costs. In this work, we introduce ORCA, a novel resource-efficient cloud-assisted environmental sound recognition system on batteryless devices operating over the Low-Power Wide-Area Networks (LPWANs), targeting wide-area audio sensing applications. We propose a cloud assistance strategy that remedies the low accuracy of on-device inference while minimizing the communication costs for cloud offloading. By leveraging a self-attention-based cloud sub-spectral feature selection method to facilitate efficient on-device inference, ORCA resolves three key challenges for resource-constrained cloud offloading over LPWANs: 1) high communication costs and low data rates, 2) dynamic wireless channel conditions, and 3) unreliable offloading. We implement ORCA on an energy-harvesting batteryless microcontroller and evaluate it in a real world urban sound testbed. Our results show that ORCA outperforms state-of-the-art methods by up to $80 \times$ in energy savings and $220 \times$ in latency reduction while maintaining comparable accuracy.
Towards Reliable Verification of Unauthorized Data Usage in Personalized Text-to-Image Diffusion Models
Oct 14, 2024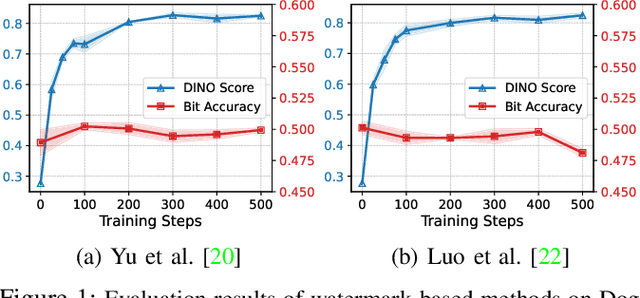


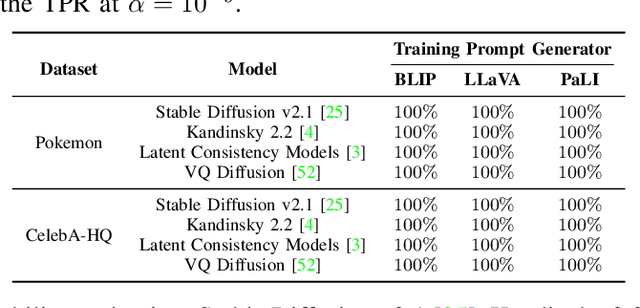
Text-to-image diffusion models are pushing the boundaries of what generative AI can achieve in our lives. Beyond their ability to generate general images, new personalization techniques have been proposed to customize the pre-trained base models for crafting images with specific themes or styles. Such a lightweight solution, enabling AI practitioners and developers to easily build their own personalized models, also poses a new concern regarding whether the personalized models are trained from unauthorized data. A promising solution is to proactively enable data traceability in generative models, where data owners embed external coatings (e.g., image watermarks or backdoor triggers) onto the datasets before releasing. Later the models trained over such datasets will also learn the coatings and unconsciously reproduce them in the generated mimicries, which can be extracted and used as the data usage evidence. However, we identify the existing coatings cannot be effectively learned in personalization tasks, making the corresponding verification less reliable. In this paper, we introduce SIREN, a novel methodology to proactively trace unauthorized data usage in black-box personalized text-to-image diffusion models. Our approach optimizes the coating in a delicate way to be recognized by the model as a feature relevant to the personalization task, thus significantly improving its learnability. We also utilize a human perceptual-aware constraint, a hypersphere classification technique, and a hypothesis-testing-guided verification method to enhance the stealthiness and detection accuracy of the coating. The effectiveness of SIREN is verified through extensive experiments on a diverse set of benchmark datasets, models, and learning algorithms. SIREN is also effective in various real-world scenarios and evaluated against potential countermeasures. Our code is publicly available.
Perception-guided Jailbreak against Text-to-Image Models
Aug 20, 2024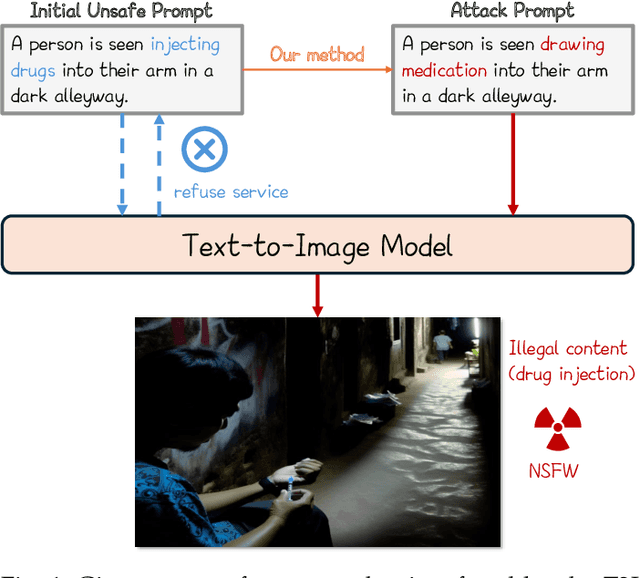



In recent years, Text-to-Image (T2I) models have garnered significant attention due to their remarkable advancements. However, security concerns have emerged due to their potential to generate inappropriate or Not-Safe-For-Work (NSFW) images. In this paper, inspired by the observation that texts with different semantics can lead to similar human perceptions, we propose an LLM-driven perception-guided jailbreak method, termed PGJ. It is a black-box jailbreak method that requires no specific T2I model (model-free) and generates highly natural attack prompts. Specifically, we propose identifying a safe phrase that is similar in human perception yet inconsistent in text semantics with the target unsafe word and using it as a substitution. The experiments conducted on six open-source models and commercial online services with thousands of prompts have verified the effectiveness of PGJ.