 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciSafeEval: A Comprehensive Benchmark for Safety Alignment of Large Language Models in Scientific Tasks
Oct 02, 2024



Large language models (LLMs) have had a transformative impact on a variety of scientific tasks across disciplines such as biology, chemistry, medicine, and physics. However, ensuring the safety alignment of these models in scientific research remains an underexplored area, with existing benchmarks primarily focus on textual content and overlooking key scientific representations such as molecular, protein, and genomic languages. Moreover, the safety mechanisms of LLMs in scientific tasks are insufficiently studied. To address these limitations, we introduce SciSafeEval, a comprehensive benchmark designed to evaluate the safety alignment of LLMs across a range of scientific tasks. SciSafeEval spans multiple scientific languages - including textual, molecular, protein, and genomic - and covers a wide range of scientific domains. We evaluate LLMs in zero-shot, few-shot and chain-of-thought settings, and introduce a 'jailbreak' enhancement feature that challenges LLMs equipped with safety guardrails, rigorously testing their defenses against malicious intention. Our benchmark surpasses existing safety datasets in both scale and scope, providing a robust platform for assessing the safety and performance of LLMs in scientific contexts. This work aims to facilitate the responsible development and deployment of LLMs, promoting alignment with safety and ethical standards in scientific research.
Let Real Images be as a Judger, Spotting Fake Images Synthesized with Generative Models
Mar 25, 2024In the last few years, generative models have shown their powerful capabilities in synthesizing realistic images in both quality and diversity (i.e., facial images, and natural subjects). Unfortunately, the artifact patterns in fake images synthesized by different generative models are inconsistent, leading to the failure of previous research that relied on spotting subtle differences between real and fake. In our preliminary experiments, we find that the artifacts in fake images always change with the development of the generative model, while natural images exhibit stable statistical properties. In this paper, we employ natural traces shared only by real images as an additional predictive target in the detector. Specifically, the natural traces are learned from the wild real images and we introduce extended supervised contrastive learning to bring them closer to real images and further away from fake ones. This motivates the detector to make decisions based on the proximity of images to the natural traces. To conduct a comprehensive experiment, we built a high-quality and diverse dataset that includes generative models comprising 6 GAN and 6 diffusion models, to evaluate the effectiveness in generalizing unknown forgery techniques and robustness in surviving different transformations. Experimental results show that our proposed method gives 96.1% mAP significantly outperforms the baselines. Extensive experiments conducted on the widely recognized platform Midjourney reveal that our proposed method achieves an accuracy exceeding 78.4%, underscoring its practicality for real-world application deployment. The source code and partial self-built dataset are available in supplementary material.
BRIEF but Powerful: Byzantine-Robust and Privacy-Preserving Federated Learning via Model Segmentation and Secure clustering
Aug 22, 2022
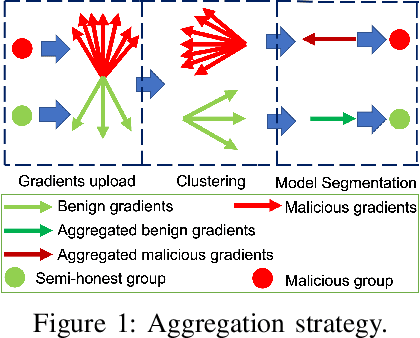
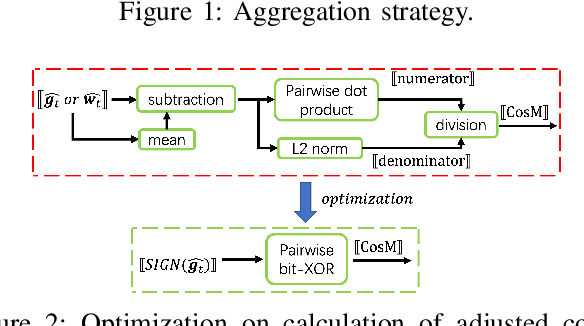
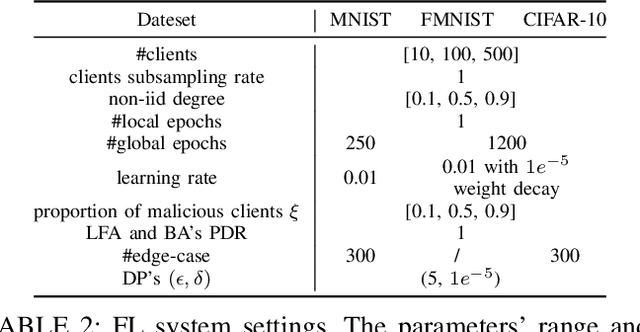
Byzantine-robust Federated Learning (FL) aims to counter malicious clients and to train an accurate global model while maintaining an extremely low attack success rate. Most of the existing systems, however, are only robust in honest/semi-honest majority settings. FLTrust (NDSS '21) extends the context to the malicious majority for clients but with a strong restriction that the server should be provided with an auxiliary dataset before training in order to filter malicious inputs. Private FLAME/FLGUARD (USENIX '22) gives a solution to guarantee both robustness and updates confidentiality in the semi-honest majority context. It is so far impossible to balance the trade-off among malicious context, robustness, and updates confidentiality. To tackle this problem, we propose a novel Byzantine-robust and privacy-preserving FL system, called BRIEF, to capture malicious minority and majority for server and client sides. Specifically, based on the DBSCAN algorithm, we design a new method for clustering via pairwise adjusted cosine similarity to boost the accuracy of the clustering results. To thwart attacks of malicious majority, we develop an algorithm called Model Segmentation, where local updates in the same cluster are aggregated together, and the aggregations are sent back to corresponding clients correctly. We also leverage multiple cryptographic tools to conduct clustering tasks without sacrificing training correctness and updates confidentiality. We present detailed security proof and empirical evaluation along with convergence analysis for BRIEF. The experimental results demonstrate that the testing accuracy of BRIEF is practically close to the FL baseline (0.8% gap on average). At the same time, the attack success rate is around 0%-5%. We further optimize our design so that the communication overhead and runtime can be decreased by {67%-89.17% and 66.05%-68.75%}, respectively.