 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Prompt vs. Image Enhancement: Boosting Object Detection With CLIP in Hazy Environments
Apr 12, 2026Object detection in hazy environments is challenging because degraded objects are nearly invisible and their semantics are weakened by environmental noise, making it difficult for detectors to identify. Common approaches involve image enhancement to boost weakened semantics, but these methods are limited by the instability of enhanced modules. This paper proposes a novel solution by employing language prompts to enhance weakened semantics without image enhancement. Specifically, we design Approximation of Mutual Exclusion (AME) to provide credible weights for Cross-Entropy Loss, resulting in CLIP-guided Cross-Entropy Loss (CLIP-CE). The provided weights assess the semantic weakening of objects. Through the backpropagation of CLIP-CE, weakened semantics are enhanced, making degraded objects easier to detect. In addition, we present Fine-tuned AME (FAME) which adaptively fine-tunes the weight of AME based on the predicted confidence. The proposed FAME compensates for the imbalanced optimization in AME. Furthermore, we present HazyCOCO, a large-scale synthetic hazy dataset comprising 61258 images. Experimental results demonstrate that our method achieves state-of-the-art performance. The code and dataset will be released.
Rethinking Intelligence: Brain-like Neuron Network
Jan 27, 2026Since their inception, artificial neural networks have relied on manually designed architectures and inductive biases to better adapt to data and tasks. With the rise of deep learning and the expansion of parameter spaces, they have begun to exhibit brain-like functional behaviors. Nevertheless, artificial neural networks remain fundamentally different from biological neural systems in structural organization, learning mechanisms, and evolutionary pathways. From the perspective of neuroscience, we rethink the formation and evolution of intelligence and proposes a new neural network paradigm, Brain-like Neural Network (BNN). We further present the first instantiation of a BNN termed LuminaNet that operates without convolutions or self-attention and is capable of autonomously modifying its architecture. We conduct extensive experiments demonstrating that LuminaNet can achieve self-evolution through dynamic architectural changes. On the CIFAR-10, LuminaNet achieves top-1 accuracy improvements of 11.19%, 5.46% over LeNet-5 and AlexNet, respectively, outperforming MLP-Mixer, ResMLP, and DeiT-Tiny among MLP/ViT architectures. On the TinyStories text generation task, LuminaNet attains a perplexity of 8.4, comparable to a single-layer GPT-2-style Transformer, while reducing computational cost by approximately 25% and peak memory usage by nearly 50%. Code and interactive structures are available at https://github.com/aaroncomo/LuminaNet.
Unbiased Semantic Decoding with Vision Foundation Models for Few-shot Segmentation
Nov 19, 2025Few-shot segmentation has garnered significant attention. Many recent approaches attempt to introduce the Segment Anything Model (SAM) to handle this task. With the strong generalization ability and rich object-specific extraction ability of the SAM model, such a solution shows great potential in few-shot segmentation. However, the decoding process of SAM highly relies on accurate and explicit prompts, making previous approaches mainly focus on extracting prompts from the support set, which is insufficient to activate the generalization ability of SAM, and this design is easy to result in a biased decoding process when adapting to the unknown classes. In this work, we propose an Unbiased Semantic Decoding (USD) strategy integrated with SAM, which extracts target information from both the support and query set simultaneously to perform consistent predictions guided by the semantics of the Contrastive Language-Image Pre-training (CLIP) model. Specifically, to enhance the unbiased semantic discrimination of SAM, we design two feature enhancement strategies that leverage the semantic alignment capability of CLIP to enrich the original SAM features, mainly including a global supplement at the image level to provide a generalize category indicate with support image and a local guidance at the pixel level to provide a useful target location with query image. Besides, to generate target-focused prompt embeddings, a learnable visual-text target prompt generator is proposed by interacting target text embeddings and clip visual features. Without requiring re-training of the vision foundation models, the features with semantic discrimination draw attention to the target region through the guidance of prompt with rich target information.
HCC-3D: Hierarchical Compensatory Compression for 98% 3D Token Reduction in Vision-Language Models
Nov 13, 20253D understanding has drawn significant attention recently, leveraging Vision-Language Models (VLMs) to enable multi-modal reasoning between point cloud and text data. Current 3D-VLMs directly embed the 3D point clouds into 3D tokens, following large 2D-VLMs with powerful reasoning capabilities. However, this framework has a great computational cost limiting its application, where we identify that the bottleneck lies in processing all 3D tokens in the Large Language Model (LLM) part. This raises the question: how can we reduce the computational overhead introduced by 3D tokens while preserving the integrity of their essential information? To address this question, we introduce Hierarchical Compensatory Compression (HCC-3D) to efficiently compress 3D tokens while maintaining critical detail retention. Specifically, we first propose a global structure compression (GSC), in which we design global queries to compress all 3D tokens into a few key tokens while keeping overall structural information. Then, to compensate for the information loss in GSC, we further propose an adaptive detail mining (ADM) module that selectively recompresses salient but under-attended features through complementary scoring. Extensive experiments demonstrate that HCC-3D not only achieves extreme compression ratios (approximately 98%) compared to previous 3D-VLMs, but also achieves new state-of-the-art performance, showing the great improvements on both efficiency and performance.
AI for Service: Proactive Assistance with AI Glasses
Oct 16, 2025In an era where AI is evolving from a passive tool into an active and adaptive companion, we introduce AI for Service (AI4Service), a new paradigm that enables proactive and real-time assistance in daily life. Existing AI services remain largely reactive, responding only to explicit user commands. We argue that a truly intelligent and helpful assistant should be capable of anticipating user needs and taking actions proactively when appropriate. To realize this vision, we propose Alpha-Service, a unified framework that addresses two fundamental challenges: Know When to intervene by detecting service opportunities from egocentric video streams, and Know How to provide both generalized and personalized services. Inspired by the von Neumann computer architecture and based on AI glasses, Alpha-Service consists of five key components: an Input Unit for perception, a Central Processing Unit for task scheduling, an Arithmetic Logic Unit for tool utilization, a Memory Unit for long-term personalization, and an Output Unit for natural human interaction. As an initial exploration, we implement Alpha-Service through a multi-agent system deployed on AI glasses. Case studies, including a real-time Blackjack advisor, a museum tour guide, and a shopping fit assistant, demonstrate its ability to seamlessly perceive the environment, infer user intent, and provide timely and useful assistance without explicit prompts.
Flexible Operator Fusion for Fast Sparse Transformer with Diverse Masking on GPU
Jun 06, 2025Large language models are popular around the world due to their powerful understanding capabilities. As the core component of LLMs, accelerating Transformer through parallelization has gradually become a hot research topic. Mask layers introduce sparsity into Transformer to reduce calculations. However, previous works rarely focus on the performance optimization of sparse Transformer. Moreover, rule-based mechanisms ignore the fusion opportunities of mixed-type operators and fail to adapt to various sequence lengths. To address the above problems, we propose STOF, a framework that incorporates optimizations for Sparse Transformer via flexible masking and operator fusion on GPU. We firstly unify the storage format and kernel implementation for the multi-head attention. Then, we map fusion schemes to compilation templates and determine the optimal parameter setting through a two-stage search engine. The experimental results show that compared to the state-of-the-art work, STOF achieves maximum speedups of 1.7x in MHA computation and 1.5x in end-to-end inference.
CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large Language Model Evaluation
Apr 29, 2025Large language models (LLMs) play a crucial role in software engineering, excelling in tasks like code generation and maintenance. However, existing benchmarks are often narrow in scope, focusing on a specific task and lack a comprehensive evaluation framework that reflects real-world applications. To address these gaps, we introduce CoCo-Bench (Comprehensive Code Benchmark), designed to evaluate LLMs across four critical dimensions: code understanding, code generation, code modification, and code review. These dimensions capture essential developer needs, ensuring a more systematic and representative evaluation. CoCo-Bench includes multiple programming languages and varying task difficulties, with rigorous manual review to ensure data quality and accuracy. Empirical results show that CoCo-Bench aligns with existing benchmarks while uncovering significant variations in model performance, effectively highlighting strengths and weaknesses. By offering a holistic and objective evaluation, CoCo-Bench provides valuable insights to guide future research and technological advancements in code-oriented LLMs, establishing a reliable benchmark for the field.
FFCBA: Feature-based Full-target Clean-label Backdoor Attacks
Apr 29, 2025Backdoor attacks pose a significant threat to deep neural networks, as backdoored models would misclassify poisoned samples with specific triggers into target classes while maintaining normal performance on clean samples. Among these, multi-target backdoor attacks can simultaneously target multiple classes. However, existing multi-target backdoor attacks all follow the dirty-label paradigm, where poisoned samples are mislabeled, and most of them require an extremely high poisoning rate. This makes them easily detectable by manual inspection. In contrast, clean-label attacks are more stealthy, as they avoid modifying the labels of poisoned samples. However, they generally struggle to achieve stable and satisfactory attack performance and often fail to scale effectively to multi-target attacks. To address this issue, we propose the Feature-based Full-target Clean-label Backdoor Attacks (FFCBA) which consists of two paradigms: Feature-Spanning Backdoor Attacks (FSBA) and Feature-Migrating Backdoor Attacks (FMBA). FSBA leverages class-conditional autoencoders to generate noise triggers that align perturbed in-class samples with the original category's features, ensuring the effectiveness, intra-class consistency, inter-class specificity and natural-feature correlation of triggers. While FSBA supports swift and efficient attacks, its cross-model attack capability is relatively weak. FMBA employs a two-stage class-conditional autoencoder training process that alternates between using out-of-class samples and in-class samples. This allows FMBA to generate triggers with strong target-class features, making it highly effective for cross-model attacks. We conduct experiments on multiple datasets and models, the results show that FFCBA achieves outstanding attack performance and maintains desirable robustness against the state-of-the-art backdoor defenses.
SFIBA: Spatial-based Full-target Invisible Backdoor Attacks
Apr 29, 2025Multi-target backdoor attacks pose significant security threats to deep neural networks, as they can preset multiple target classes through a single backdoor injection. This allows attackers to control the model to misclassify poisoned samples with triggers into any desired target class during inference, exhibiting superior attack performance compared with conventional backdoor attacks. However, existing multi-target backdoor attacks fail to guarantee trigger specificity and stealthiness in black-box settings, resulting in two main issues. First, they are unable to simultaneously target all classes when only training data can be manipulated, limiting their effectiveness in realistic attack scenarios. Second, the triggers often lack visual imperceptibility, making poisoned samples easy to detect. To address these problems, we propose a Spatial-based Full-target Invisible Backdoor Attack, called SFIBA. It restricts triggers for different classes to specific local spatial regions and morphologies in the pixel space to ensure specificity, while employing a frequency-domain-based trigger injection method to guarantee stealthiness. Specifically, for injection of each trigger, we first apply fast fourier transform to obtain the amplitude spectrum of clean samples in local spatial regions. Then, we employ discrete wavelet transform to extract the features from the amplitude spectrum and use singular value decomposition to integrate the trigger. Subsequently, we selectively filter parts of the trigger in pixel space to implement trigger morphology constraints and adjust injection coefficients based on visual effects. We conduct experiments on multiple datasets and models. The results demonstrate that SFIBA can achieve excellent attack performance and stealthiness, while preserving the model's performance on benign samples, and can also bypass existing backdoor defenses.
Modeling All Response Surfaces in One for Conditional Search Spaces
Jan 08, 2025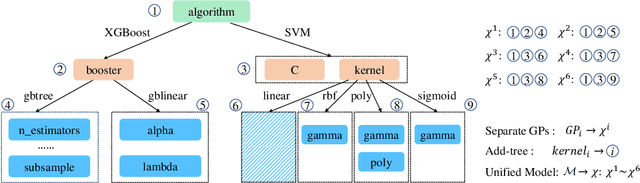
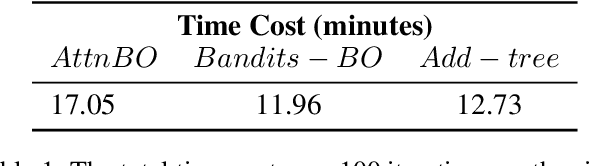
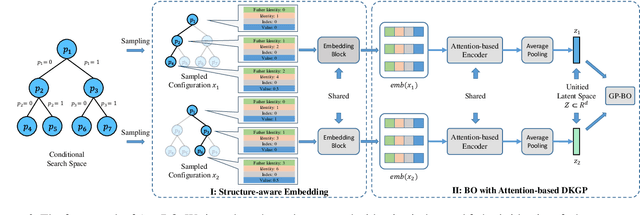
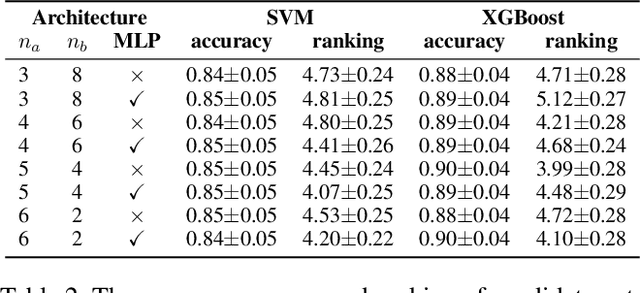
Bayesian Optimization (BO) is a sample-efficient black-box optimizer commonly used in search spaces where hyperparameters are independent. However, in many practical AutoML scenarios, there will be dependencies among hyperparameters, forming a conditional search space, which can be partitioned into structurally distinct subspaces. The structure and dimensionality of hyperparameter configurations vary across these subspaces, challenging the application of BO. Some previous BO works have proposed solutions to develop multiple Gaussian Process models in these subspaces. However, these approaches tend to be inefficient as they require a substantial number of observations to guarantee each GP's performance and cannot capture relationships between hyperparameters across different subspaces. To address these issues, this paper proposes a novel approach to model the response surfaces of all subspaces in one, which can model the relationships between hyperparameters elegantly via a self-attention mechanism. Concretely, we design a structure-aware hyperparameter embedding to preserve the structural information. Then, we introduce an attention-based deep feature extractor, capable of projecting configurations with different structures from various subspaces into a unified feature space, where the response surfaces can be formulated using a single standard Gaussian Process. The empirical results on a simulation function, various real-world tasks, and HPO-B benchmark demonstrate that our proposed approach improves the efficacy and efficiency of BO within conditional search spaces.