 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFIBA: Spatial-based Full-target Invisible Backdoor Attacks
Apr 29, 2025Multi-target backdoor attacks pose significant security threats to deep neural networks, as they can preset multiple target classes through a single backdoor injection. This allows attackers to control the model to misclassify poisoned samples with triggers into any desired target class during inference, exhibiting superior attack performance compared with conventional backdoor attacks. However, existing multi-target backdoor attacks fail to guarantee trigger specificity and stealthiness in black-box settings, resulting in two main issues. First, they are unable to simultaneously target all classes when only training data can be manipulated, limiting their effectiveness in realistic attack scenarios. Second, the triggers often lack visual imperceptibility, making poisoned samples easy to detect. To address these problems, we propose a Spatial-based Full-target Invisible Backdoor Attack, called SFIBA. It restricts triggers for different classes to specific local spatial regions and morphologies in the pixel space to ensure specificity, while employing a frequency-domain-based trigger injection method to guarantee stealthiness. Specifically, for injection of each trigger, we first apply fast fourier transform to obtain the amplitude spectrum of clean samples in local spatial regions. Then, we employ discrete wavelet transform to extract the features from the amplitude spectrum and use singular value decomposition to integrate the trigger. Subsequently, we selectively filter parts of the trigger in pixel space to implement trigger morphology constraints and adjust injection coefficients based on visual effects. We conduct experiments on multiple datasets and models. The results demonstrate that SFIBA can achieve excellent attack performance and stealthiness, while preserving the model's performance on benign samples, and can also bypass existing backdoor defenses.
XTraffic: A Dataset Where Traffic Meets Incidents with Explainability and More
Jul 16, 2024

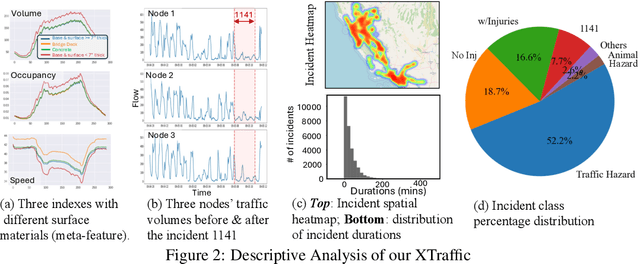
Long-separated research has been conducted on two highly correlated tracks: traffic and incidents. Traffic track witnesses complicating deep learning models, e.g., to push the prediction a few percent more accurate, and the incident track only studies the incidents alone, e.g., to infer the incident risk. We, for the first time, spatiotemporally aligned the two tracks in a large-scale region (16,972 traffic nodes) over the whole year of 2023: our XTraffic dataset includes traffic, i.e., time-series indexes on traffic flow, lane occupancy, and average vehicle speed, and incidents, whose records are spatiotemporally-aligned with traffic data, with seven different incident classes. Additionally, each node includes detailed physical and policy-level meta-attributes of lanes. Our data can revolutionalize traditional traffic-related tasks towards higher interpretability and practice: instead of traditional prediction or classification tasks, we conduct: (1) post-incident traffic forecasting to quantify the impact of different incidents on traffic indexes; (2) incident classification using traffic indexes to determine the incidents types for precautions measures; (3) global causal analysis among the traffic indexes, meta-attributes, and incidents to give high-level guidance of the interrelations of various factors; (4) local causal analysis within road nodes to examine how different incidents affect the road segments' relations. The dataset is available at http://xaitraffic.github.io.
Transformer-based Drum-level Prediction in a Boiler Plant with Delayed Relations among Multivariates
Jul 15, 2024



The steam drum water level is a critical parameter that directly impacts the safety and efficiency of power plant operations. However, predicting the drum water level in boilers is challenging due to complex non-linear process dynamics originating from long-time delays and interrelations, as well as measurement noise. This paper investigates the application of Transformer-based models for predicting drum water levels in a steam boiler plant. Leveraging the capabilities of Transformer architectures, this study aims to develop an accurate and robust predictive framework to anticipate water level fluctuations and facilitate proactive control strategies. To this end, a prudent pipeline is proposed, including 1) data preprocess, 2) causal relation analysis, 3) delay inference, 4) variable augmentation, and 5) prediction. Through extensive experimentation and analysis, the effectiveness of Transformer-based approaches in steam drum water level prediction is evaluated, highlighting their potential to enhance operational stability and optimize plant performance.
SQL-to-Schema Enhances Schema Linking in Text-to-SQL
May 15, 2024



In sophisticated existing Text-to-SQL methods exhibit errors in various proportions, including schema-linking errors (incorrect columns, tables, or extra columns), join errors, nested errors, and group-by errors. Consequently, there is a critical need to filter out unnecessary tables and columns, directing the language models attention to relevant tables and columns with schema-linking, to reduce errors during SQL generation. Previous approaches have involved sorting tables and columns based on their relevance to the question, selecting the top-ranked ones for sorting, or directly identifying the necessary tables and columns for SQL generation. However, these methods face challenges such as lengthy model training times, high consumption of expensive GPT-4 tokens in few-shot prompts, or suboptimal performance in schema linking. Therefore, we propose an inventive schema linking method in two steps: Firstly, generate an initial SQL query by utilizing the complete database schema. Subsequently, extract tables and columns from the initial SQL query to create a concise schema. Using CodeLlama-34B, when comparing the schemas obtained by mainstream methods with ours for SQL generation, our schema performs optimally. Leveraging GPT4, our SQL generation method achieved results that are comparable to mainstream Text-to-SQL methods on the Spider dataset.
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Mar 18, 2024



Recent advancements in Text-to-SQL (Text2SQL) emphasize stimulating the large language models (LLM) on in-context learning, achieving significant results. Nevertheless, they face challenges when dealing with verbose database information and complex user intentions. This paper presents a two-stage framework to enhance the performance of current LLM-based natural language to SQL systems. We first introduce a novel prompt representation, called reference-enhanced representation, which includes schema information and randomly sampled cell values from tables to instruct LLMs in generating SQL queries. Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL). After that, the mentioned entities in PreSQL are parsed to conduct schema linking, which can significantly compact the useful information. In the second stage, with the linked schema, we simplify the prompt's schema information and instruct the LLM to produce the final SQL. Finally, as the post-refinement module, we propose using cross-consistency across different LLMs rather than self-consistency within a particular LLM. Our methods achieve new SOTA results on the Spider benchmark, with an execution accuracy of 87.6%.
Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
Mar 06, 2024



Large Language Models (LLMs) have emerged as a powerful tool in advancing the Text-to-SQL task, significantly outperforming traditional methods. Nevertheless, as a nascent research field, there is still no consensus on the optimal prompt templates and design frameworks. Additionally, existing benchmarks inadequately explore the performance of LLMs across the various sub-tasks of the Text-to-SQL process, which hinders the assessment of LLMs' cognitive capabilities and the optimization of LLM-based solutions. To address the aforementioned issues, we firstly construct a new dataset designed to mitigate the risk of overfitting in LLMs. Then we formulate five evaluation tasks to comprehensively assess the performance of diverse methods across various LLMs throughout the Text-to-SQL process.Our study highlights the performance disparities among LLMs and proposes optimal in-context learning solutions tailored to each task. These findings offer valuable insights for enhancing the development of LLM-based Text-to-SQL systems.
Spatial-Temporal Large Language Model for Traffic Prediction
Jan 23, 2024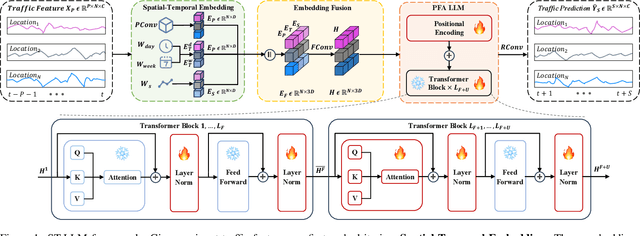
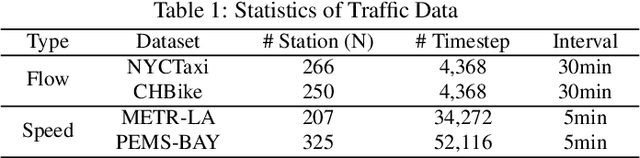
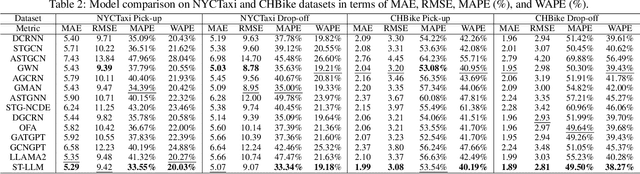
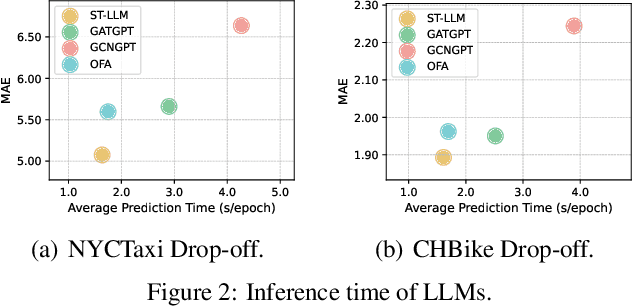
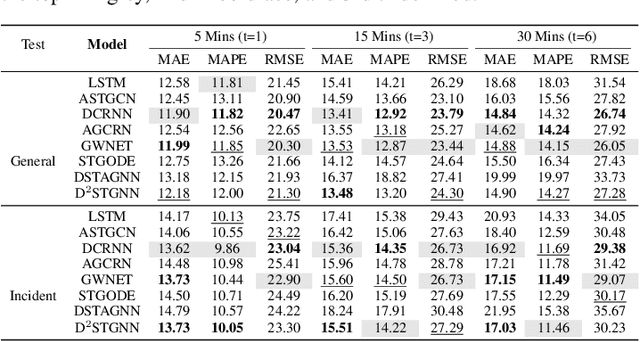
Traffic prediction, a critical component for intelligent transportation systems, endeavors to foresee future traffic at specific locations using historical data. Although existing traffic prediction models often emphasize developing complex neural network structures, their accuracy has not seen improvements accordingly. Recently, Large Language Models (LLMs) have shown outstanding capabilities in time series analysis. Differing from existing models, LLMs progress mainly through parameter expansion and extensive pre-training while maintaining their fundamental structures. In this paper, we propose a Spatial-Temporal Large Language Model (ST-LLM) for traffic prediction. Specifically, ST-LLM redefines the timesteps at each location as tokens and incorporates a spatial-temporal embedding module to learn the spatial location and global temporal representations of tokens. Then these representations are fused to provide each token with unified spatial and temporal information. Furthermore, we propose a novel partially frozen attention strategy of the LLM, which is designed to capture spatial-temporal dependencies for traffic prediction. Comprehensive experiments on real traffic datasets offer evidence that ST-LLM outperforms state-of-the-art models. Notably, the ST-LLM also exhibits robust performance in both few-shot and zero-shot prediction scenarios.
Non-Neighbors Also Matter to Kriging: A New Contrastive-Prototypical Learning
Jan 23, 2024



Kriging aims at estimating the attributes of unsampled geo-locations from observations in the spatial vicinity or physical connections, which helps mitigate skewed monitoring caused by under-deployed sensors. Existing works assume that neighbors' information offers the basis for estimating the attributes of the unobserved target while ignoring non-neighbors. However, non-neighbors could also offer constructive information, and neighbors could also be misleading. To this end, we propose ``Contrastive-Prototypical'' self-supervised learning for Kriging (KCP) to refine valuable information from neighbors and recycle the one from non-neighbors. As a pre-trained paradigm, we conduct the Kriging task from a new perspective of representation: we aim to first learn robust and general representations and then recover attributes from representations. A neighboring contrastive module is designed that coarsely learns the representations by narrowing the representation distance between the target and its neighbors while pushing away the non-neighbors. In parallel, a prototypical module is introduced to identify similar representations via exchanged prediction, thus refining the misleading neighbors and recycling the useful non-neighbors from the neighboring contrast component. As a result, not all the neighbors and some of the non-neighbors will be used to infer the target. To encourage the two modules above to learn general and robust representations, we design an adaptive augmentation module that incorporates data-driven attribute augmentation and centrality-based topology augmentation over the spatiotemporal Kriging graph data. Extensive experiments on real-world datasets demonstrate the superior performance of KCP compared to its peers with 6% improvements and exceptional transferability and robustness. The code is available at https://github.com/bonaldli/KCP
VisionTraj: A Noise-Robust Trajectory Recovery Framework based on Large-scale Camera Network
Dec 11, 2023Trajectory recovery based on the snapshots from the city-wide multi-camera network facilitates urban mobility sensing and driveway optimization. The state-of-the-art solutions devoted to such a vision-based scheme typically incorporate predefined rules or unsupervised iterative feedback, struggling with multi-fold challenges such as lack of open-source datasets for training the whole pipeline, and the vulnerability to the noises from visual inputs. In response to the dilemma, this paper proposes VisionTraj, the first learning-based model that reconstructs vehicle trajectories from snapshots recorded by road network cameras. Coupled with it, we elaborate on two rational vision-trajectory datasets, which produce extensive trajectory data along with corresponding visual snapshots, enabling supervised vision-trajectory interplay extraction. Following the data creation, based on the results from the off-the-shelf multi-modal vehicle clustering, we first re-formulate the trajectory recovery problem as a generative task and introduce the canonical Transformer as the autoregressive backbone. Then, to identify clustering noises (e.g., false positives) with the bound on the snapshots' spatiotemporal dependencies, a GCN-based soft-denoising module is conducted based on the fine- and coarse-grained Re-ID clusters. Additionally, we harness strong semantic information extracted from the tracklet to provide detailed insights into the vehicle's entry and exit actions during trajectory recovery. The denoising and tracklet components can also act as plug-and-play modules to boost baselines. Experimental results on the two hand-crafted datasets show that the proposed VisionTraj achieves a maximum +11.5% improvement against the sub-best model.
A Critical Perceptual Pre-trained Model for Complex Trajectory Recovery
Nov 05, 2023



The trajectory on the road traffic is commonly collected at a low sampling rate, and trajectory recovery aims to recover a complete and continuous trajectory from the sparse and discrete inputs. Recently, sequential language models have been innovatively adopted for trajectory recovery in a pre-trained manner: it learns road segment representation vectors, which will be used in the downstream tasks. However, existing methods are incapable of handling complex trajectories: when the trajectory crosses remote road segments or makes several turns, which we call critical nodes, the quality of learned representations deteriorates, and the recovered trajectories skip the critical nodes. This work is dedicated to offering a more robust trajectory recovery for complex trajectories. Firstly, we define the trajectory complexity based on the detour score and entropy score and construct the complexity-aware semantic graphs correspondingly. Then, we propose a Multi-view Graph and Complexity Aware Transformer (MGCAT) model to encode these semantics in trajectory pre-training from two aspects: 1) adaptively aggregate the multi-view graph features considering trajectory pattern, and 2) higher attention to critical nodes in a complex trajectory. Such that, our MGCAT is perceptual when handling the critical scenario of complex trajectories. Extensive experiments are conducted on large-scale datasets. The results prove that our method learns better representations for trajectory recovery, with 5.22% higher F1-score overall and 8.16% higher F1-score for complex trajectories particularly. The code is available at https://github.com/bonaldli/ComplexTraj.