 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Aligning Prompt Rewriting with Visual Anchors for Text-to-Image Generation
Jun 07, 2026Despite the impressive capabilities of text-to-image (T2I) models, an intent-generation gap often persists due to the brevity and ambiguity of user prompts. Existing approaches primarily polish the prompt for fluency and readability. However, the enhancement process still lacks visual grounding. As a result, the rewriter may over-infer missing details, causing an intent-generation gap. To address this limitation, we propose FaithRewriter, a novel prompt-enhancement framework for T2I generation. Specifically, FaithRewriter first leverages a multimodal MLLM to generate an image from the original prompt as an intermediate visual cue. This cue is then combined with the prompt and fed into a large-scale LLM to produce visually grounded augmentations that better reflect how the intended content should appear in images. Finally, these augmentations are distilled into a small-scale LLM for efficient deployment, enhancing its ability to generate effective T2I prompts. Experiments show that FaithRewriter yields prompts that are more faithful to the user intent and more visually plausible than strong baselines, helping narrow the intent-generation gap.
Language-Instructed Reasoning for Group Activity Detection via Multimodal Large Language Model
Sep 19, 2025Group activity detection (GAD) aims to simultaneously identify group members and categorize their collective activities within video sequences. Existing deep learning-based methods develop specialized architectures (e.g., transformer networks) to model the dynamics of individual roles and semantic dependencies between individuals and groups. However, they rely solely on implicit pattern recognition from visual features and struggle with contextual reasoning and explainability. In this work, we propose LIR-GAD, a novel framework of language-instructed reasoning for GAD via Multimodal Large Language Model (MLLM). Our approach expand the original vocabulary of MLLM by introducing an activity-level <ACT> token and multiple cluster-specific <GROUP> tokens. We process video frames alongside two specially designed tokens and language instructions, which are then integrated into the MLLM. The pretrained commonsense knowledge embedded in the MLLM enables the <ACT> token and <GROUP> tokens to effectively capture the semantic information of collective activities and learn distinct representational features of different groups, respectively. Also, we introduce a multi-label classification loss to further enhance the <ACT> token's ability to learn discriminative semantic representations. Then, we design a Multimodal Dual-Alignment Fusion (MDAF) module that integrates MLLM's hidden embeddings corresponding to the designed tokens with visual features, significantly enhancing the performance of GAD. Both quantitative and qualitative experiments demonstrate the superior performance of our proposed method in GAD taks.
Unlocking the Power of SAM 2 for Few-Shot Segmentation
May 21, 2025



Few-Shot Segmentation (FSS) aims to learn class-agnostic segmentation on few classes to segment arbitrary classes, but at the risk of overfitting. To address this, some methods use the well-learned knowledge of foundation models (e.g., SAM) to simplify the learning process. Recently, SAM 2 has extended SAM by supporting video segmentation, whose class-agnostic matching ability is useful to FSS. A simple idea is to encode support foreground (FG) features as memory, with which query FG features are matched and fused. Unfortunately, the FG objects in different frames of SAM 2's video data are always the same identity, while those in FSS are different identities, i.e., the matching step is incompatible. Therefore, we design Pseudo Prompt Generator to encode pseudo query memory, matching with query features in a compatible way. However, the memories can never be as accurate as the real ones, i.e., they are likely to contain incomplete query FG, and some unexpected query background (BG) features, leading to wrong segmentation. Hence, we further design Iterative Memory Refinement to fuse more query FG features into the memory, and devise a Support-Calibrated Memory Attention to suppress the unexpected query BG features in memory. Extensive experiments have been conducted on PASCAL-5$^i$ and COCO-20$^i$ to validate the effectiveness of our design, e.g., the 1-shot mIoU can be 4.2% better than the best baseline.
SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache
May 19, 2025Graph-based retrieval-augmented generation (RAG) enables large language models (LLMs) to incorporate structured knowledge via graph retrieval as contextual input, enhancing more accurate and context-aware reasoning. We observe that for different queries, it could retrieve similar subgraphs as prompts, and thus we propose SubGCache, which aims to reduce inference latency by reusing computation across queries with similar structural prompts (i.e., subgraphs). Specifically, SubGCache clusters queries based on subgraph embeddings, constructs a representative subgraph for each cluster, and pre-computes the key-value (KV) cache of the representative subgraph. For each query with its retrieved subgraph within a cluster, it reuses the pre-computed KV cache of the representative subgraph of the cluster without computing the KV tensors again for saving computation. Experiments on two new datasets across multiple LLM backbones and graph-based RAG frameworks demonstrate that SubGCache consistently reduces inference latency with comparable and even improved generation quality, achieving up to 6.68$\times$ reduction in time-to-first-token (TTFT).
Towards Cross-Modality Modeling for Time Series Analytics: A Survey in the LLM Era
May 05, 2025The proliferation of edge devices has generated an unprecedented volume of time series data across different domains, motivating various well-customized methods. Recently, Large Language Models (LLMs) have emerged as a new paradigm for time series analytics by leveraging the shared sequential nature of textual data and time series. However, a fundamental cross-modality gap between time series and LLMs exists, as LLMs are pre-trained on textual corpora and are not inherently optimized for time series. Many recent proposals are designed to address this issue. In this survey, we provide an up-to-date overview of LLMs-based cross-modality modeling for time series analytics. We first introduce a taxonomy that classifies existing approaches into four groups based on the type of textual data employed for time series modeling. We then summarize key cross-modality strategies, e.g., alignment and fusion, and discuss their applications across a range of downstream tasks. Furthermore, we conduct experiments on multimodal datasets from different application domains to investigate effective combinations of textual data and cross-modality strategies for enhancing time series analytics. Finally, we suggest several promising directions for future research. This survey is designed for a range of professionals, researchers, and practitioners interested in LLM-based time series modeling.
Efficient Multivariate Time Series Forecasting via Calibrated Language Models with Privileged Knowledge Distillation
May 04, 2025Multivariate time series forecasting (MTSF) endeavors to predict future observations given historical data, playing a crucial role in time series data management systems. With advancements in large language models (LLMs), recent studies employ textual prompt tuning to infuse the knowledge of LLMs into MTSF. However, the deployment of LLMs often suffers from low efficiency during the inference phase. To address this problem, we introduce TimeKD, an efficient MTSF framework that leverages the calibrated language models and privileged knowledge distillation. TimeKD aims to generate high-quality future representations from the proposed cross-modality teacher model and cultivate an effective student model. The cross-modality teacher model adopts calibrated language models (CLMs) with ground truth prompts, motivated by the paradigm of Learning Under Privileged Information (LUPI). In addition, we design a subtractive cross attention (SCA) mechanism to refine these representations. To cultivate an effective student model, we propose an innovative privileged knowledge distillation (PKD) mechanism including correlation and feature distillation. PKD enables the student to replicate the teacher's behavior while minimizing their output discrepancy. Extensive experiments on real data offer insight into the effectiveness, efficiency, and scalability of the proposed TimeKD.
POPEN: Preference-Based Optimization and Ensemble for LVLM-Based Reasoning Segmentation
Apr 01, 2025



Existing LVLM-based reasoning segmentation methods often suffer from imprecise segmentation results and hallucinations in their text responses. This paper introduces POPEN, a novel framework designed to address these issues and achieve improved results. POPEN includes a preference-based optimization method to finetune the LVLM, aligning it more closely with human preferences and thereby generating better text responses and segmentation results. Additionally, POPEN introduces a preference-based ensemble method for inference, which integrates multiple outputs from the LVLM using a preference-score-based attention mechanism for refinement. To better adapt to the segmentation task, we incorporate several task-specific designs in our POPEN framework, including a new approach for collecting segmentation preference data with a curriculum learning mechanism, and a novel preference optimization loss to refine the segmentation capability of the LVLM. Experiments demonstrate that our method achieves state-of-the-art performance in reasoning segmentation, exhibiting minimal hallucination in text responses and the highest segmentation accuracy compared to previous advanced methods like LISA and PixelLM. Project page is https://lanyunzhu.site/POPEN/
Hybrid Mamba for Few-Shot Segmentation
Sep 29, 2024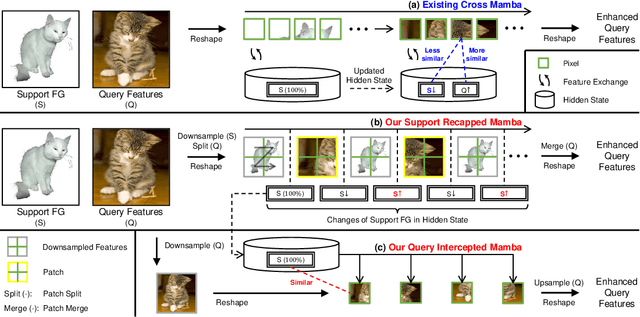
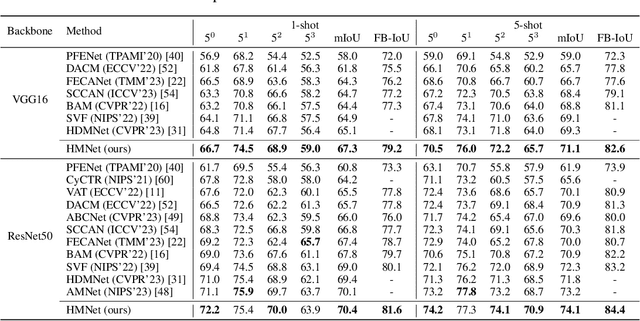
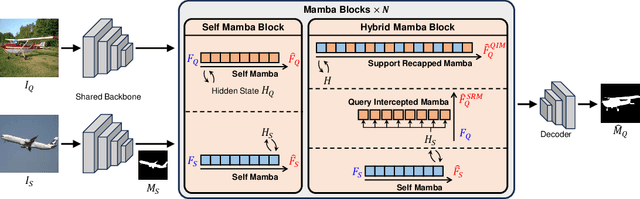
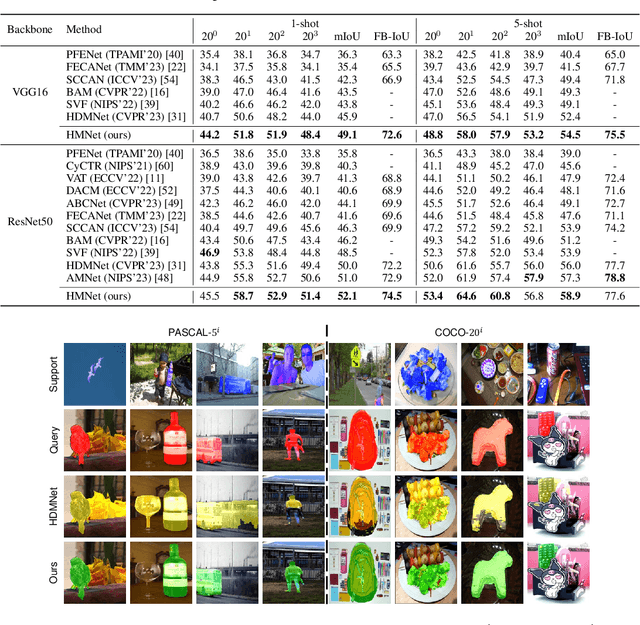
Many few-shot segmentation (FSS) methods use cross attention to fuse support foreground (FG) into query features, regardless of the quadratic complexity. A recent advance Mamba can also well capture intra-sequence dependencies, yet the complexity is only linear. Hence, we aim to devise a cross (attention-like) Mamba to capture inter-sequence dependencies for FSS. A simple idea is to scan on support features to selectively compress them into the hidden state, which is then used as the initial hidden state to sequentially scan query features. Nevertheless, it suffers from (1) support forgetting issue: query features will also gradually be compressed when scanning on them, so the support features in hidden state keep reducing, and many query pixels cannot fuse sufficient support features; (2) intra-class gap issue: query FG is essentially more similar to itself rather than to support FG, i.e., query may prefer not to fuse support features but their own ones from the hidden state, yet the success of FSS relies on the effective use of support information. To tackle them, we design a hybrid Mamba network (HMNet), including (1) a support recapped Mamba to periodically recap the support features when scanning query, so the hidden state can always contain rich support information; (2) a query intercepted Mamba to forbid the mutual interactions among query pixels, and encourage them to fuse more support features from the hidden state. Consequently, the support information is better utilized, leading to better performance. Extensive experiments have been conducted on two public benchmarks, showing the superiority of HMNet. The code is available at https://github.com/Sam1224/HMNet.
HHGT: Hierarchical Heterogeneous Graph Transformer for Heterogeneous Graph Representation Learning
Jul 18, 2024


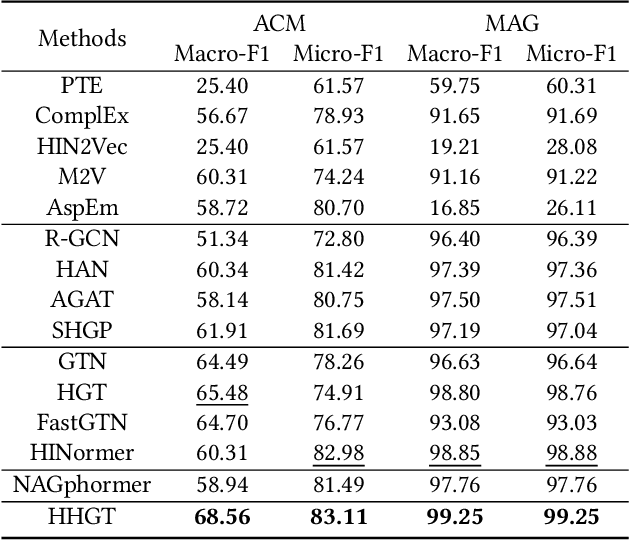
Despite the success of Heterogeneous Graph Neural Networks (HGNNs) in modeling real-world Heterogeneous Information Networks (HINs), challenges such as expressiveness limitations and over-smoothing have prompted researchers to explore Graph Transformers (GTs) for enhanced HIN representation learning. However, research on GT in HINs remains limited, with two key shortcomings in existing work: (1) A node's neighbors at different distances in HINs convey diverse semantics. Unfortunately, existing methods ignore such differences and uniformly treat neighbors within a given distance in a coarse manner, which results in semantic confusion. (2) Nodes in HINs have various types, each with unique semantics. Nevertheless, existing methods mix nodes of different types during neighbor aggregation, hindering the capture of proper correlations between nodes of diverse types. To bridge these gaps, we design an innovative structure named (k,t)-ring neighborhood, where nodes are initially organized by their distance, forming different non-overlapping k-ring neighborhoods for each distance. Within each k-ring structure, nodes are further categorized into different groups according to their types, thus emphasizing the heterogeneity of both distances and types in HINs naturally. Based on this structure, we propose a novel Hierarchical Heterogeneous Graph Transformer (HHGT) model, which seamlessly integrates a Type-level Transformer for aggregating nodes of different types within each k-ring neighborhood, followed by a Ring-level Transformer for aggregating different k-ring neighborhoods in a hierarchical manner. Extensive experiments are conducted on downstream tasks to verify HHGT's superiority over 14 baselines, with a notable improvement of up to 24.75% in NMI and 29.25% in ARI for node clustering task on the ACM dataset compared to the best baseline.
Eliminating Feature Ambiguity for Few-Shot Segmentation
Jul 13, 2024


Recent advancements in few-shot segmentation (FSS) have exploited pixel-by-pixel matching between query and support features, typically based on cross attention, which selectively activate query foreground (FG) features that correspond to the same-class support FG features. However, due to the large receptive fields in deep layers of the backbone, the extracted query and support FG features are inevitably mingled with background (BG) features, impeding the FG-FG matching in cross attention. Hence, the query FG features are fused with less support FG features, i.e., the support information is not well utilized. This paper presents a novel plug-in termed ambiguity elimination network (AENet), which can be plugged into any existing cross attention-based FSS methods. The main idea is to mine discriminative query FG regions to rectify the ambiguous FG features, increasing the proportion of FG information, so as to suppress the negative impacts of the doped BG features. In this way, the FG-FG matching is naturally enhanced. We plug AENet into three baselines CyCTR, SCCAN and HDMNet for evaluation, and their scores are improved by large margins, e.g., the 1-shot performance of SCCAN can be improved by 3.0%+ on both PASCAL-5$^i$ and COCO-20$^i$. The code is available at https://github.com/Sam1224/AENet.