 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeMoLE: LLM-Enhanced Mixture of Linear Experts for Time Series Forecasting
Nov 24, 2024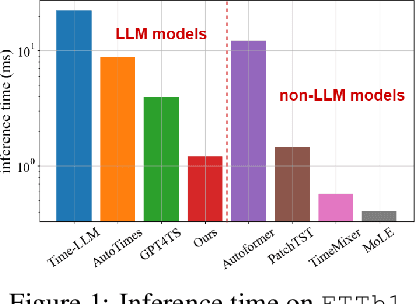
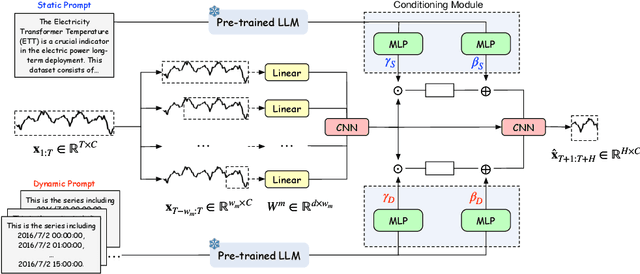
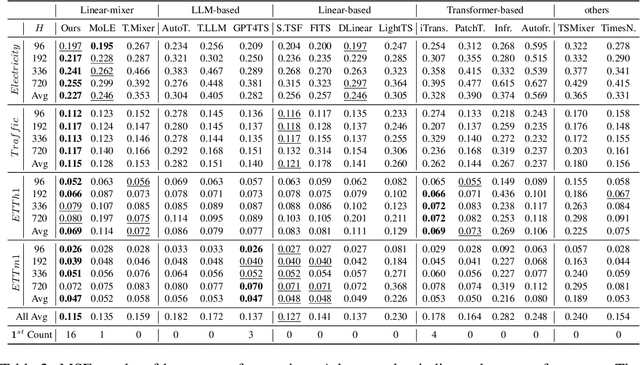
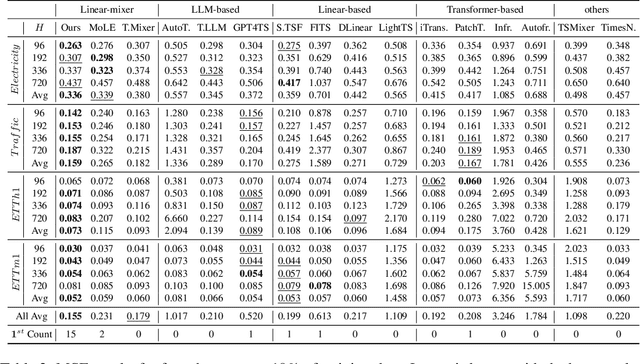
Recent research has shown that large language models (LLMs) can be effectively used for real-world time series forecasting due to their strong natural language understanding capabilities. However, aligning time series into semantic spaces of LLMs comes with high computational costs and inference complexity, particularly for long-range time series generation. Building on recent advancements in using linear models for time series, this paper introduces an LLM-enhanced mixture of linear experts for precise and efficient time series forecasting. This approach involves developing a mixture of linear experts with multiple lookback lengths and a new multimodal fusion mechanism. The use of a mixture of linear experts is efficient due to its simplicity, while the multimodal fusion mechanism adaptively combines multiple linear experts based on the learned features of the text modality from pre-trained large language models. In experiments, we rethink the need to align time series to LLMs by existing time-series large language models and further discuss their efficiency and effectiveness in time series forecasting. Our experimental results show that the proposed LeMoLE model presents lower prediction errors and higher computational efficiency than existing LLM models.
TimeCMA: Towards LLM-Empowered Time Series Forecasting via Cross-Modality Alignment
Jun 03, 2024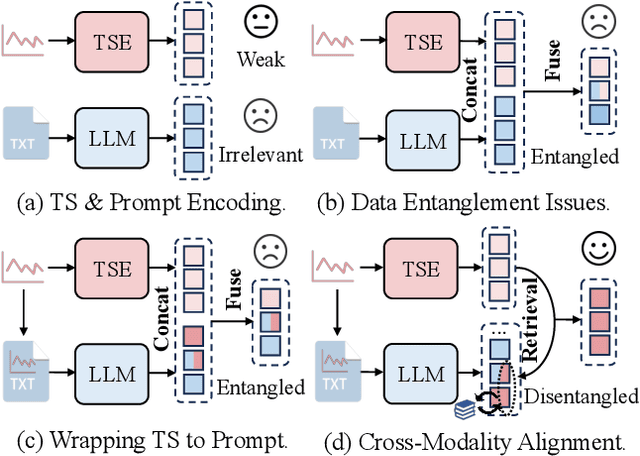



The widespread adoption of scalable mobile sensing has led to large amounts of time series data for real-world applications. A fundamental application is multivariate time series forecasting (MTSF), which aims to predict future time series values based on historical observations. Existing MTSF methods suffer from limited parameterization and small-scale training data. Recently, Large language models (LLMs) have been introduced in time series, which achieve promising forecasting performance but incur heavy computational costs. To solve these challenges, we propose TimeCMA, an LLM-empowered framework for time series forecasting with cross-modality alignment. We design a dual-modality encoding module with two branches, where the time series encoding branch extracts relatively low-quality yet pure embeddings of time series through an inverted Transformer. In addition, the LLM-empowered encoding branch wraps the same time series as prompts to obtain high-quality yet entangled prompt embeddings via a Pre-trained LLM. Then, we design a cross-modality alignment module to retrieve high-quality and pure time series embeddings from the prompt embeddings. Moreover, we develop a time series forecasting module to decode the aligned embeddings while capturing dependencies among multiple variables for forecasting. Notably, we tailor the prompt to encode sufficient temporal information into a last token and design the last token embedding storage to reduce computational costs. Extensive experiments on real data offer insight into the accuracy and efficiency of the proposed framework.