 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition through Reasoning: Reinforcing Image Geo-localization with Large Vision-Language Models
Jun 17, 2025Previous methods for image geo-localization have typically treated the task as either classification or retrieval, often relying on black-box decisions that lack interpretability. The rise of large vision-language models (LVLMs) has enabled a rethinking of geo-localization as a reasoning-driven task grounded in visual cues. However, two major challenges persist. On the data side, existing reasoning-focused datasets are primarily based on street-view imagery, offering limited scene diversity and constrained viewpoints. On the modeling side, current approaches predominantly rely on supervised fine-tuning, which yields only marginal improvements in reasoning capabilities. To address these challenges, we propose a novel pipeline that constructs a reasoning-oriented geo-localization dataset, MP16-Reason, using diverse social media images. We introduce GLOBE, Group-relative policy optimization for Locatability assessment and Optimized visual-clue reasoning, yielding Bi-objective geo-Enhancement for the VLM in recognition and reasoning. GLOBE incorporates task-specific rewards that jointly enhance locatability assessment, visual clue reasoning, and geolocation accuracy. Both qualitative and quantitative results demonstrate that GLOBE outperforms state-of-the-art open-source LVLMs on geo-localization tasks, particularly in diverse visual scenes, while also generating more insightful and interpretable reasoning trajectories.
A Pre-Training and Adaptive Fine-Tuning Framework for Graph Anomaly Detection
Apr 19, 2025Graph anomaly detection (GAD) has garnered increasing attention in recent years, yet it remains challenging due to the scarcity of abnormal nodes and the high cost of label annotations. Graph pre-training, the two-stage learning paradigm, has emerged as an effective approach for label-efficient learning, largely benefiting from expressive neighborhood aggregation under the assumption of strong homophily. However, in GAD, anomalies typically exhibit high local heterophily, while normal nodes retain strong homophily, resulting in a complex homophily-heterophily mixture. To understand the impact of this mixed pattern on graph pre-training, we analyze it through the lens of spectral filtering and reveal that relying solely on a global low-pass filter is insufficient for GAD. We further provide a theoretical justification for the necessity of selectively applying appropriate filters to individual nodes. Building upon this insight, we propose PAF, a Pre-Training and Adaptive Fine-tuning framework specifically designed for GAD. In particular, we introduce joint training with low- and high-pass filters in the pre-training phase to capture the full spectrum of frequency information in node features. During fine-tuning, we devise a gated fusion network that adaptively combines node representations generated by both filters. Extensive experiments across ten benchmark datasets consistently demonstrate the effectiveness of PAF.
Sparseformer: a Transferable Transformer with Multi-granularity Token Sparsification for Medical Time Series Classification
Mar 19, 2025



Medical time series (MedTS) classification is crucial for improved diagnosis in healthcare, and yet it is challenging due to the varying granularity of patterns, intricate inter-channel correlation, information redundancy, and label scarcity. While existing transformer-based models have shown promise in time series analysis, they mainly focus on forecasting and fail to fully exploit the distinctive characteristics of MedTS data. In this paper, we introduce Sparseformer, a transformer specifically designed for MedTS classification. We propose a sparse token-based dual-attention mechanism that enables global modeling and token compression, allowing dynamic focus on the most informative tokens while distilling redundant features. This mechanism is then applied to the multi-granularity, cross-channel encoding of medical signals, capturing intra- and inter-granularity correlations and inter-channel connections. The sparsification design allows our model to handle heterogeneous inputs of varying lengths and channels directly. Further, we introduce an adaptive label encoder to address label space misalignment across datasets, equipping our model with cross-dataset transferability to alleviate the medical label scarcity issue. Our model outperforms 12 baselines across seven medical datasets under supervised learning. In the few-shot learning experiments, our model also achieves superior average results. In addition, the in-domain and cross-domain experiments among three diagnostic scenarios demonstrate our model's zero-shot learning capability. Collectively, these findings underscore the robustness and transferability of our model in various medical applications.
CirT: Global Subseasonal-to-Seasonal Forecasting with Geometry-inspired Transformer
Feb 27, 2025Accurate Subseasonal-to-Seasonal (S2S) climate forecasting is pivotal for decision-making including agriculture planning and disaster preparedness but is known to be challenging due to its chaotic nature. Although recent data-driven models have shown promising results, their performance is limited by inadequate consideration of geometric inductive biases. Usually, they treat the spherical weather data as planar images, resulting in an inaccurate representation of locations and spatial relations. In this work, we propose the geometric-inspired Circular Transformer (CirT) to model the cyclic characteristic of the graticule, consisting of two key designs: (1) Decomposing the weather data by latitude into circular patches that serve as input tokens to the Transformer; (2) Leveraging Fourier transform in self-attention to capture the global information and model the spatial periodicity. Extensive experiments on the Earth Reanalysis 5 (ERA5) reanalysis dataset demonstrate our model yields a significant improvement over the advanced data-driven models, including PanguWeather and GraphCast, as well as skillful ECMWF systems. Additionally, we empirically show the effectiveness of our model designs and high-quality prediction over spatial and temporal dimensions.
LeMoLE: LLM-Enhanced Mixture of Linear Experts for Time Series Forecasting
Nov 24, 2024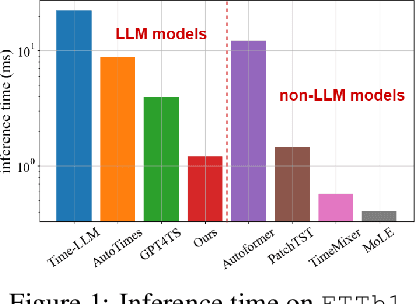
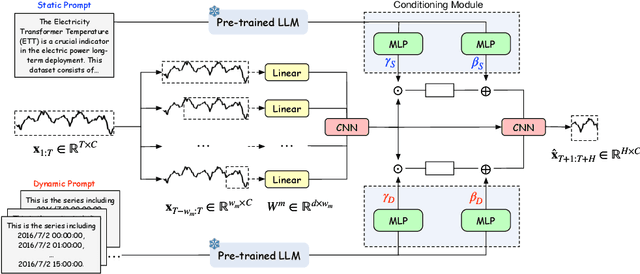
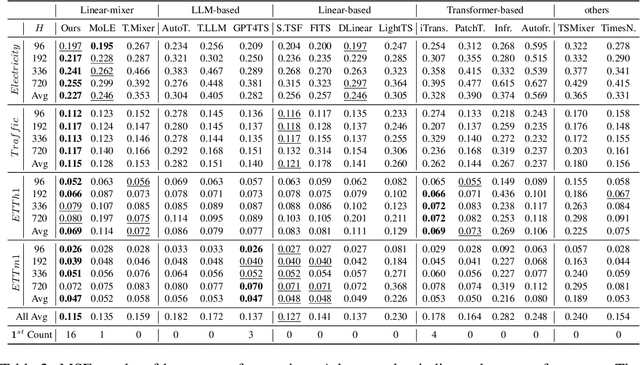
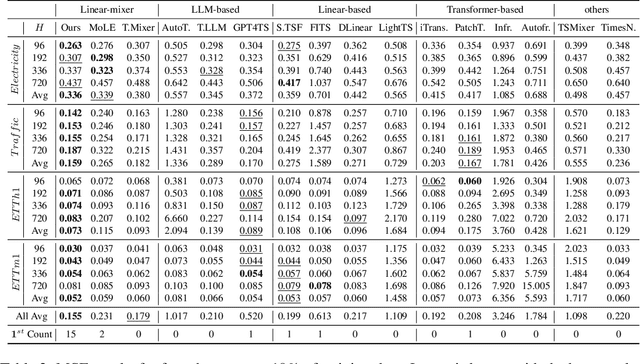
Recent research has shown that large language models (LLMs) can be effectively used for real-world time series forecasting due to their strong natural language understanding capabilities. However, aligning time series into semantic spaces of LLMs comes with high computational costs and inference complexity, particularly for long-range time series generation. Building on recent advancements in using linear models for time series, this paper introduces an LLM-enhanced mixture of linear experts for precise and efficient time series forecasting. This approach involves developing a mixture of linear experts with multiple lookback lengths and a new multimodal fusion mechanism. The use of a mixture of linear experts is efficient due to its simplicity, while the multimodal fusion mechanism adaptively combines multiple linear experts based on the learned features of the text modality from pre-trained large language models. In experiments, we rethink the need to align time series to LLMs by existing time-series large language models and further discuss their efficiency and effectiveness in time series forecasting. Our experimental results show that the proposed LeMoLE model presents lower prediction errors and higher computational efficiency than existing LLM models.
Heterophilic Graph Neural Networks Optimization with Causal Message-passing
Nov 21, 2024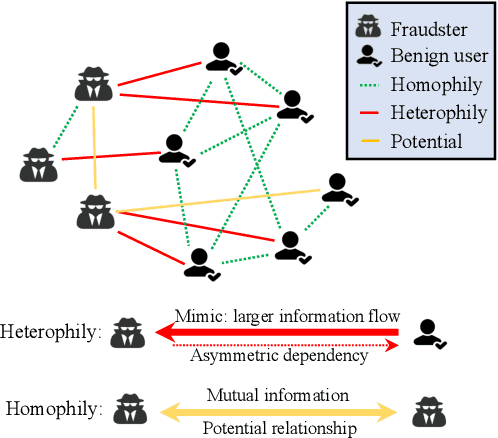
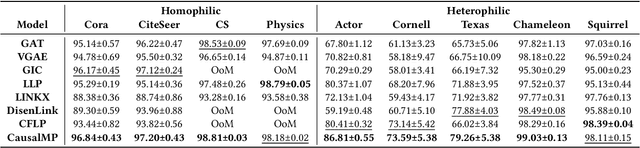
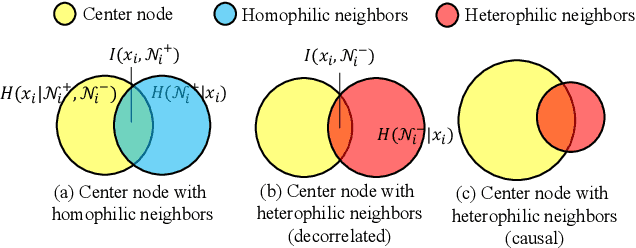
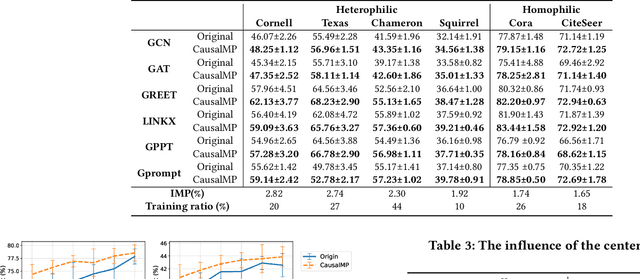
In this work, we discover that causal inference provides a promising approach to capture heterophilic message-passing in Graph Neural Network (GNN). By leveraging cause-effect analysis, we can discern heterophilic edges based on asymmetric node dependency. The learned causal structure offers more accurate relationships among nodes. To reduce the computational complexity, we introduce intervention-based causal inference in graph learning. We first simplify causal analysis on graphs by formulating it as a structural learning model and define the optimization problem within the Bayesian scheme. We then present an analysis of decomposing the optimization target into a consistency penalty and a structure modification based on cause-effect relations. We then estimate this target by conditional entropy and present insights into how conditional entropy quantifies the heterophily. Accordingly, we propose CausalMP, a causal message-passing discovery network for heterophilic graph learning, that iteratively learns the explicit causal structure of input graphs. We conduct extensive experiments in both heterophilic and homophilic graph settings. The result demonstrates that the our model achieves superior link prediction performance. Training on causal structure can also enhance node representation in classification task across different base models.
Graph Pre-Training Models Are Strong Anomaly Detectors
Oct 24, 2024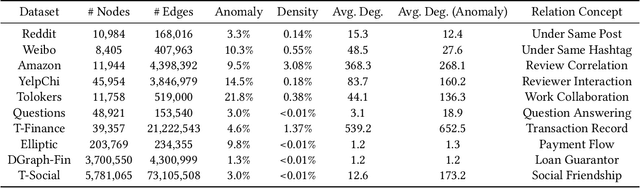
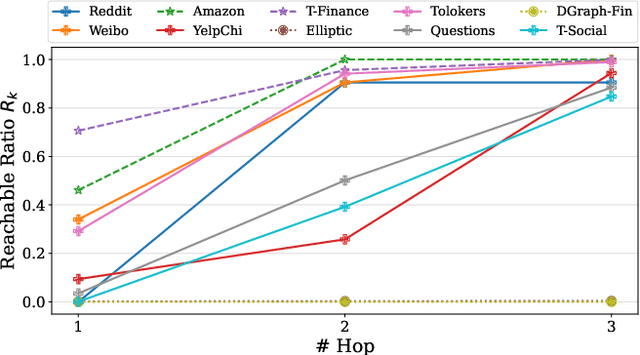
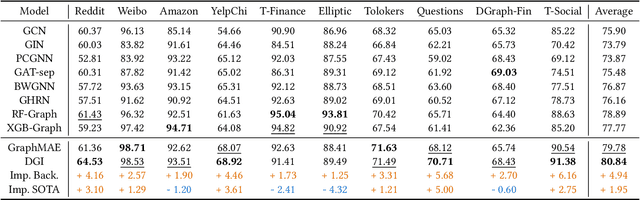
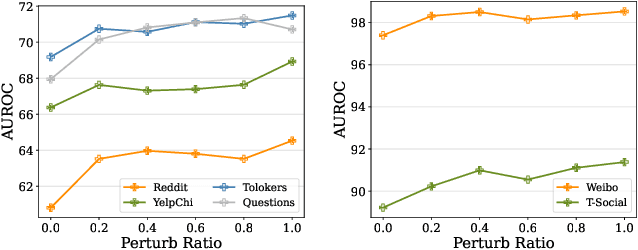
Graph Anomaly Detection (GAD) is a challenging and practical research topic where Graph Neural Networks (GNNs) have recently shown promising results. The effectiveness of existing GNNs in GAD has been mainly attributed to the simultaneous learning of node representations and the classifier in an end-to-end manner. Meanwhile, graph pre-training, the two-stage learning paradigm such as DGI and GraphMAE, has shown potential in leveraging unlabeled graph data to enhance downstream tasks, yet its impact on GAD remains under-explored. In this work, we show that graph pre-training models are strong graph anomaly detectors. Specifically, we demonstrate that pre-training is highly competitive, markedly outperforming the state-of-the-art end-to-end training models when faced with limited supervision. To understand this phenomenon, we further uncover pre-training enhances the detection of distant, under-represented, unlabeled anomalies that go beyond 2-hop neighborhoods of known anomalies, shedding light on its superior performance against end-to-end models. Moreover, we extend our examination to the potential of pre-training in graph-level anomaly detection. We envision this work to stimulate a re-evaluation of pre-training's role in GAD and offer valuable insights for future research.
MCCoder: Streamlining Motion Control with LLM-Assisted Code Generation and Rigorous Verification
Oct 19, 2024



Large Language Models (LLMs) have shown considerable promise in code generation. However, the automation sector, especially in motion control, continues to rely heavily on manual programming due to the complexity of tasks and critical safety considerations. In this domain, incorrect code execution can pose risks to both machinery and personnel, necessitating specialized expertise. To address these challenges, we introduce MCCoder, an LLM-powered system designed to generate code that addresses complex motion control tasks, with integrated soft-motion data verification. MCCoder enhances code generation through multitask decomposition, hybrid retrieval-augmented generation (RAG), and self-correction with a private motion library. Moreover, it supports data verification by logging detailed trajectory data and providing simulations and plots, allowing users to assess the accuracy of the generated code and bolstering confidence in LLM-based programming. To ensure robust validation, we propose MCEVAL, an evaluation dataset with metrics tailored to motion control tasks of varying difficulties. Experiments indicate that MCCoder improves performance by 11.61% overall and by 66.12% on complex tasks in MCEVAL dataset compared with base models with naive RAG. This system and dataset aim to facilitate the application of code generation in automation settings with strict safety requirements. MCCoder is publicly available at https://github.com/MCCodeAI/MCCoder.
Disentangling Likes and Dislikes in Personalized Generative Explainable Recommendation
Oct 17, 2024



Recent research on explainable recommendation generally frames the task as a standard text generation problem, and evaluates models simply based on the textual similarity between the predicted and ground-truth explanations. However, this approach fails to consider one crucial aspect of the systems: whether their outputs accurately reflect the users' (post-purchase) sentiments, i.e., whether and why they would like and/or dislike the recommended items. To shed light on this issue, we introduce new datasets and evaluation methods that focus on the users' sentiments. Specifically, we construct the datasets by explicitly extracting users' positive and negative opinions from their post-purchase reviews using an LLM, and propose to evaluate systems based on whether the generated explanations 1) align well with the users' sentiments, and 2) accurately identify both positive and negative opinions of users on the target items. We benchmark several recent models on our datasets and demonstrate that achieving strong performance on existing metrics does not ensure that the generated explanations align well with the users' sentiments. Lastly, we find that existing models can provide more sentiment-aware explanations when the users' (predicted) ratings for the target items are directly fed into the models as input. We will release our code and datasets upon acceptance.
Toward Physics-guided Time Series Embedding
Oct 09, 2024



In various scientific and engineering fields, the primary research areas have revolved around physics-based dynamical systems modeling and data-driven time series analysis. According to the embedding theory, dynamical systems and time series can be mutually transformed using observation functions and physical reconstruction techniques. Based on this, we propose Embedding Duality Theory, where the parameterized embedding layer essentially provides a linear estimation of the non-linear time series dynamics. This theory enables us to bypass the parameterized embedding layer and directly employ physical reconstruction techniques to acquire a data embedding representation. Utilizing physical priors results in a 10X reduction in parameters, a 3X increase in speed, and maximum performance boosts of 18% in expert, 22% in few-shot, and 53\% in zero-shot tasks without any hyper-parameter tuning. All methods are encapsulated as a plug-and-play module