 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Adaptive Parameter-Efficient Fine-Tuning for Weather Foundation Models
Sep 26, 2025While recent advances in machine learning have equipped Weather Foundation Models (WFMs) with substantial generalization capabilities across diverse downstream tasks, the escalating computational requirements associated with their expanding scale increasingly hinder practical deployment. Current Parameter-Efficient Fine-Tuning (PEFT) methods, designed for vision or language tasks, fail to address the unique challenges of weather downstream tasks, such as variable heterogeneity, resolution diversity, and spatiotemporal coverage variations, leading to suboptimal performance when applied to WFMs. To bridge this gap, we introduce WeatherPEFT, a novel PEFT framework for WFMs incorporating two synergistic innovations. First, during the forward pass, Task-Adaptive Dynamic Prompting (TADP) dynamically injects the embedding weights within the encoder to the input tokens of the pre-trained backbone via internal and external pattern extraction, enabling context-aware feature recalibration for specific downstream tasks. Furthermore, during backpropagation, Stochastic Fisher-Guided Adaptive Selection (SFAS) not only leverages Fisher information to identify and update the most task-critical parameters, thereby preserving invariant pre-trained knowledge, but also introduces randomness to stabilize the selection. We demonstrate the effectiveness and efficiency of WeatherPEFT on three downstream tasks, where existing PEFT methods show significant gaps versus Full-Tuning, and WeatherPEFT achieves performance parity with Full-Tuning using fewer trainable parameters. The code of this work will be released.
A Pre-Training and Adaptive Fine-Tuning Framework for Graph Anomaly Detection
Apr 19, 2025Graph anomaly detection (GAD) has garnered increasing attention in recent years, yet it remains challenging due to the scarcity of abnormal nodes and the high cost of label annotations. Graph pre-training, the two-stage learning paradigm, has emerged as an effective approach for label-efficient learning, largely benefiting from expressive neighborhood aggregation under the assumption of strong homophily. However, in GAD, anomalies typically exhibit high local heterophily, while normal nodes retain strong homophily, resulting in a complex homophily-heterophily mixture. To understand the impact of this mixed pattern on graph pre-training, we analyze it through the lens of spectral filtering and reveal that relying solely on a global low-pass filter is insufficient for GAD. We further provide a theoretical justification for the necessity of selectively applying appropriate filters to individual nodes. Building upon this insight, we propose PAF, a Pre-Training and Adaptive Fine-tuning framework specifically designed for GAD. In particular, we introduce joint training with low- and high-pass filters in the pre-training phase to capture the full spectrum of frequency information in node features. During fine-tuning, we devise a gated fusion network that adaptively combines node representations generated by both filters. Extensive experiments across ten benchmark datasets consistently demonstrate the effectiveness of PAF.
CirT: Global Subseasonal-to-Seasonal Forecasting with Geometry-inspired Transformer
Feb 27, 2025Accurate Subseasonal-to-Seasonal (S2S) climate forecasting is pivotal for decision-making including agriculture planning and disaster preparedness but is known to be challenging due to its chaotic nature. Although recent data-driven models have shown promising results, their performance is limited by inadequate consideration of geometric inductive biases. Usually, they treat the spherical weather data as planar images, resulting in an inaccurate representation of locations and spatial relations. In this work, we propose the geometric-inspired Circular Transformer (CirT) to model the cyclic characteristic of the graticule, consisting of two key designs: (1) Decomposing the weather data by latitude into circular patches that serve as input tokens to the Transformer; (2) Leveraging Fourier transform in self-attention to capture the global information and model the spatial periodicity. Extensive experiments on the Earth Reanalysis 5 (ERA5) reanalysis dataset demonstrate our model yields a significant improvement over the advanced data-driven models, including PanguWeather and GraphCast, as well as skillful ECMWF systems. Additionally, we empirically show the effectiveness of our model designs and high-quality prediction over spatial and temporal dimensions.
Graph Pre-Training Models Are Strong Anomaly Detectors
Oct 24, 2024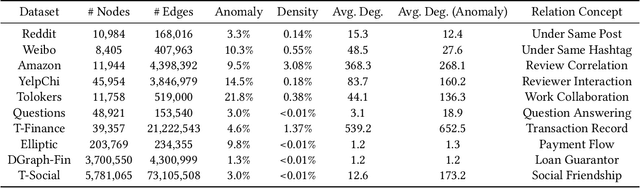
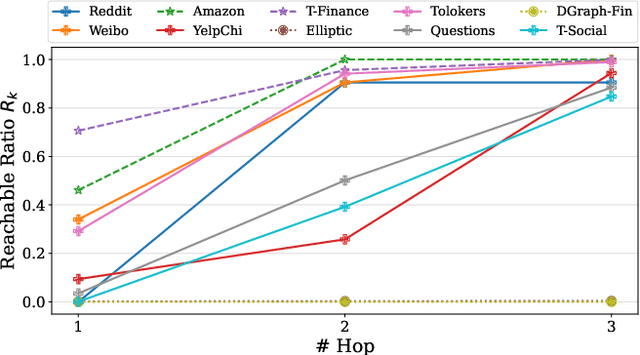
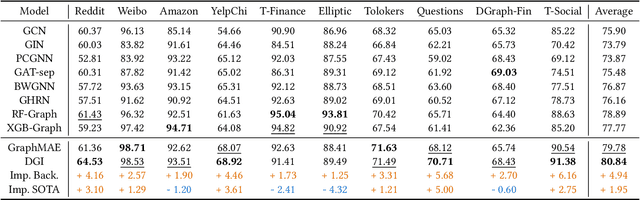
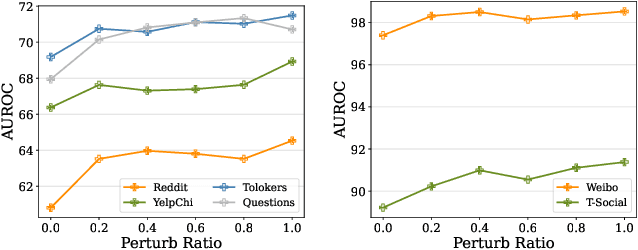
Graph Anomaly Detection (GAD) is a challenging and practical research topic where Graph Neural Networks (GNNs) have recently shown promising results. The effectiveness of existing GNNs in GAD has been mainly attributed to the simultaneous learning of node representations and the classifier in an end-to-end manner. Meanwhile, graph pre-training, the two-stage learning paradigm such as DGI and GraphMAE, has shown potential in leveraging unlabeled graph data to enhance downstream tasks, yet its impact on GAD remains under-explored. In this work, we show that graph pre-training models are strong graph anomaly detectors. Specifically, we demonstrate that pre-training is highly competitive, markedly outperforming the state-of-the-art end-to-end training models when faced with limited supervision. To understand this phenomenon, we further uncover pre-training enhances the detection of distant, under-represented, unlabeled anomalies that go beyond 2-hop neighborhoods of known anomalies, shedding light on its superior performance against end-to-end models. Moreover, we extend our examination to the potential of pre-training in graph-level anomaly detection. We envision this work to stimulate a re-evaluation of pre-training's role in GAD and offer valuable insights for future research.
Deep Insights into Noisy Pseudo Labeling on Graph Data
Oct 02, 2023



Pseudo labeling (PL) is a wide-applied strategy to enlarge the labeled dataset by self-annotating the potential samples during the training process. Several works have shown that it can improve the graph learning model performance in general. However, we notice that the incorrect labels can be fatal to the graph training process. Inappropriate PL may result in the performance degrading, especially on graph data where the noise can propagate. Surprisingly, the corresponding error is seldom theoretically analyzed in the literature. In this paper, we aim to give deep insights of PL on graph learning models. We first present the error analysis of PL strategy by showing that the error is bounded by the confidence of PL threshold and consistency of multi-view prediction. Then, we theoretically illustrate the effect of PL on convergence property. Based on the analysis, we propose a cautious pseudo labeling methodology in which we pseudo label the samples with highest confidence and multi-view consistency. Finally, extensive experiments demonstrate that the proposed strategy improves graph learning process and outperforms other PL strategies on link prediction and node classification tasks.
Physics-Inspired Neural Graph ODE for Long-term Dynamical Simulation
Aug 25, 2023Simulating and modeling the long-term dynamics of multi-object physical systems is an essential and challenging task. Current studies model the physical systems utilizing Graph Neural Networks (GNNs) with equivariant properties. Specifically, they model the dynamics as a sequence of discrete states with a fixed time interval and learn a direct mapping for all the two adjacent states. However, this direct mapping overlooks the continuous nature between the two states. Namely, we have verified that there are countless possible trajectories between two discrete dynamic states in current GNN-based direct mapping models. This issue greatly hinders the model generalization ability, leading to poor performance of the long-term simulation. In this paper, to better model the latent trajectory through discrete supervision signals, we propose a Physics-Inspired Neural Graph ODE (PINGO) algorithm. In PINGO, to ensure the uniqueness of the trajectory, we construct a Physics-Inspired Neural ODE framework to update the latent trajectory. Meanwhile, to effectively capture intricate interactions among objects, we use a GNN-based model to parameterize Neural ODE in a plug-and-play manner. Furthermore, we prove that the discrepancy between the learned trajectory of PIGNO and the true trajectory can be theoretically bounded. Extensive experiments verify our theoretical findings and demonstrate that our model yields an order-of-magnitude improvement over the state-of-the-art baselines, especially on long-term predictions and roll-out errors.
Handling Missing Data via Max-Entropy Regularized Graph Autoencoder
Nov 30, 2022



Graph neural networks (GNNs) are popular weapons for modeling relational data. Existing GNNs are not specified for attribute-incomplete graphs, making missing attribute imputation a burning issue. Until recently, many works notice that GNNs are coupled with spectral concentration, which means the spectrum obtained by GNNs concentrates on a local part in spectral domain, e.g., low-frequency due to oversmoothing issue. As a consequence, GNNs may be seriously flawed for reconstructing graph attributes as graph spectral concentration tends to cause a low imputation precision. In this work, we present a regularized graph autoencoder for graph attribute imputation, named MEGAE, which aims at mitigating spectral concentration problem by maximizing the graph spectral entropy. Notably, we first present the method for estimating graph spectral entropy without the eigen-decomposition of Laplacian matrix and provide the theoretical upper error bound. A maximum entropy regularization then acts in the latent space, which directly increases the graph spectral entropy. Extensive experiments show that MEGAE outperforms all the other state-of-the-art imputation methods on a variety of benchmark datasets.
Latent Augmentation Improves Graph Self-Supervised Learning
Jul 03, 2022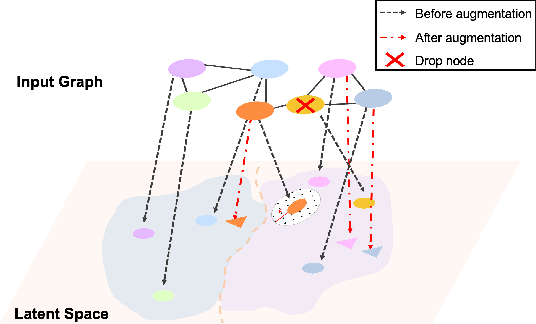
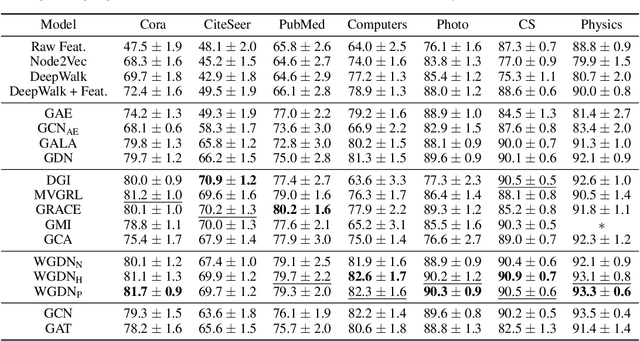
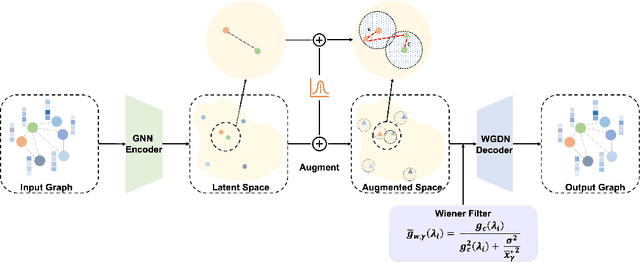
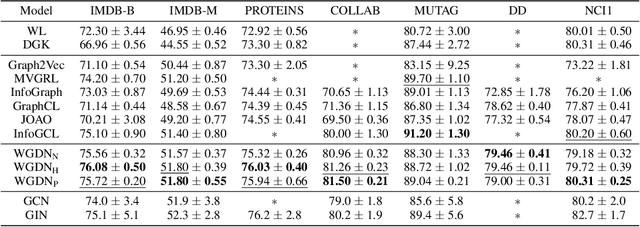
Graph self-supervised learning has been vastly employed to learn representations from unlabeled graphs. Existing methods can be roughly divided into predictive learning and contrastive learning, where the latter one attracts more research attention with better empirical performance. We argue that, however, predictive models weaponed with latent augmentations and powerful decoder could achieve comparable or even better representation power than contrastive models. In this work, we introduce data augmentations into latent space for superior generalization and better efficiency. A novel graph decoder named Wiener Graph Deconvolutional Network is correspondingly designed to perform information reconstruction from augmented latent representations. Theoretical analysis proves the superior reconstruction ability of graph wiener filter. Extensive experimental results on various datasets demonstrate the effectiveness of our approach.