 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan First, Judge Later, Run Better: A DMAIC-Inspired Agentic System for Industrial Anomaly Detection
Jun 03, 2026Large language model (LLM) agents have shown promise in automating complex data-analysis workflows, but their reliable deployment remains challenging in high-stakes industrial scenarios. Industrial anomaly detection (IAD) is essential for manufacturing quality, safety, and efficiency, yet existing LLM-based IAD agents mainly focus on execution while under-exploiting strategy formulation. Consequently, they struggle to handle heterogeneous modalities in a unified and cost-effective manner. Inspired by the DMAIC quality-management framework, we propose DMAIC-IAD (DMAIC-inspired Agentic Industrial Anomaly Detection), a "Plan First, Judge Later" multi-agent system that aligns LLM agents with structured industrial problem-solving. DMAIC-IAD distills heterogeneous references into standardized operating procedures (SOPs) before strategy generation, and introduces a pre-trained execution-free judge model to rank candidate strategies without costly runtime trials. Extensive experiments across four modalities show that DMAIC-IAD improves average detection performance over applicable agentic baselines by 37.76%.
AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
May 28, 2026Modern open-world agents such as OpenClaw exhibit powerful cross-environment execution capabilities yet introduce broad new safety risk sources. Meanwhile, advanced frontier AI models drastically lower attack barriers, rendering current agent alignment frameworks inadequate for real-world deployment. To tackle these emerging threats, we propose a lightweight and scalable agent safety alignment framework. Specifically, we update the agent safety taxonomy to accommodate emergent risks from Codex and OpenClaw execution scenarios. We further build a taxonomy-guided data engine with influence-function purification to train lightweight AgentDoG 1.5 variants (0.8B, 2B, 4B, and 8B parameters) using only around 1k samples, achieving comparable performance with leading closed-source models (e.g., GPT-5.4). Based on AgentDoG 1.5, we construct a highly efficient agentic safety SFT and RL training environment, which reduces deployment overhead in Docker-level environments by two orders of magnitude. Finally, we deploy AgentDoG 1.5 as a training-free online guardrail for real-time safety moderation. Extensive experimental results indicate that AgentDoG 1.5 achieves state-of-the-art performance in diverse and complex interactive agentic scenarios. All models and datasets are openly released.
SRL-ORCA: A Socially Aware Multi-Agent Mapless Navigation Algorithm In Complex Dynamic Scenes
Jun 18, 2023
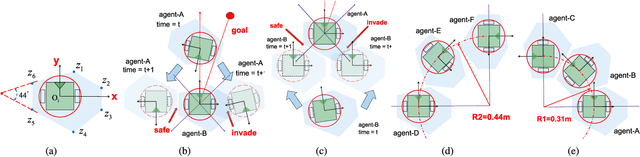
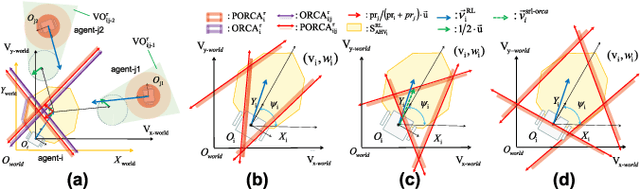
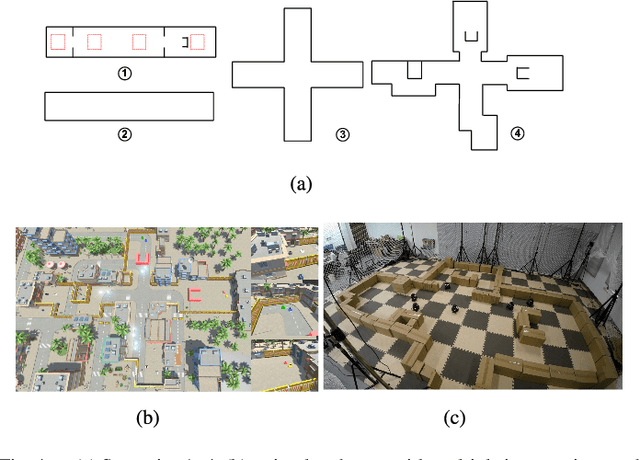
For real-world navigation, it is important to endow robots with the capabilities to navigate safely and efficiently in a complex environment with both dynamic and non-convex static obstacles. However, achieving path-finding in non-convex complex environments without maps as well as enabling multiple robots to follow social rules for obstacle avoidance remains challenging problems. In this letter, we propose a socially aware robot mapless navigation algorithm, namely Safe Reinforcement Learning-Optimal Reciprocal Collision Avoidance (SRL-ORCA). This is a multi-agent safe reinforcement learning algorithm by using ORCA as an external knowledge to provide a safety guarantee. This algorithm further introduces traffic norms of human society to improve social comfort and achieve cooperative avoidance by following human social customs. The result of experiments shows that SRL-ORCA learns strategies to obey specific traffic rules. Compared to DRL, SRL-ORCA shows a significant improvement in navigation success rate in different complex scenarios mixed with the application of the same training network. SRL-ORCA is able to cope with non-convex obstacle environments without falling into local minimal regions and has a 14.1\% improvement in path quality (i.e., the average time to target) compared to ORCA. Videos are available at https://youtu.be/huhXfCDkGws.
MM-DAG: Multi-task DAG Learning for Multi-modal Data -- with Application for Traffic Congestion Analysis
Jun 05, 2023



This paper proposes to learn Multi-task, Multi-modal Direct Acyclic Graphs (MM-DAGs), which are commonly observed in complex systems, e.g., traffic, manufacturing, and weather systems, whose variables are multi-modal with scalars, vectors, and functions. This paper takes the traffic congestion analysis as a concrete case, where a traffic intersection is usually regarded as a DAG. In a road network of multiple intersections, different intersections can only have some overlapping and distinct variables observed. For example, a signalized intersection has traffic light-related variables, whereas unsignalized ones do not. This encourages the multi-task design: with each DAG as a task, the MM-DAG tries to learn the multiple DAGs jointly so that their consensus and consistency are maximized. To this end, we innovatively propose a multi-modal regression for linear causal relationship description of different variables. Then we develop a novel Causality Difference (CD) measure and its differentiable approximator. Compared with existing SOTA measures, CD can penalize the causal structural difference among DAGs with distinct nodes and can better consider the uncertainty of causal orders. We rigidly prove our design's topological interpretation and consistency properties. We conduct thorough simulations and one case study to show the effectiveness of our MM-DAG. The code is available under https://github.com/Lantian72/MM-DAG
A Multi-robot Coverage Path Planning Algorithm Based on Improved DARP Algorithm
Apr 19, 2023
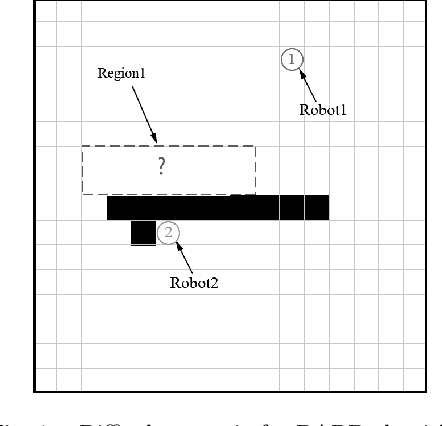

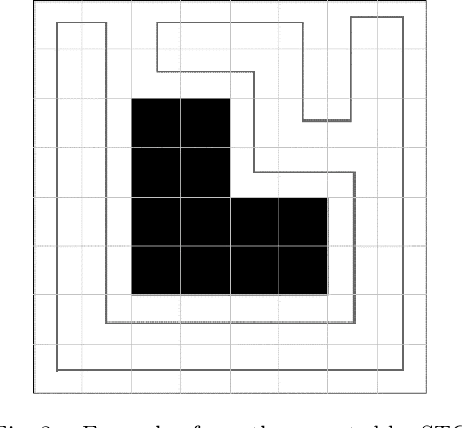
The research on multi-robot coverage path planning (CPP) has been attracting more and more attention. In order to achieve efficient coverage, this paper proposes an improved DARP coverage algorithm. The improved DARP algorithm based on A* algorithm is used to assign tasks to robots and then combined with STC algorithm based on Up-First algorithm to achieve full coverage of the task area. Compared with the initial DARP algorithm, this algorithm has higher efficiency and higher coverage rate.
Latent Augmentation Improves Graph Self-Supervised Learning
Jul 03, 2022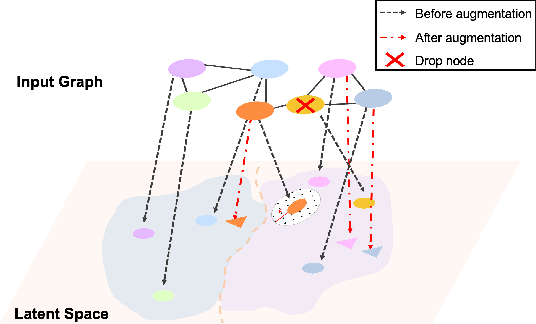
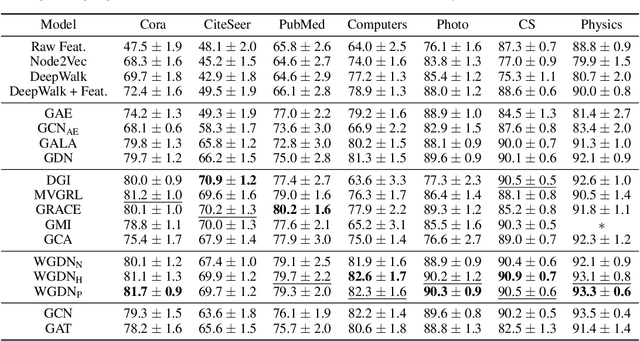
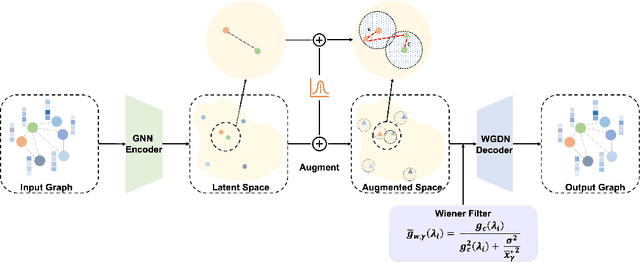
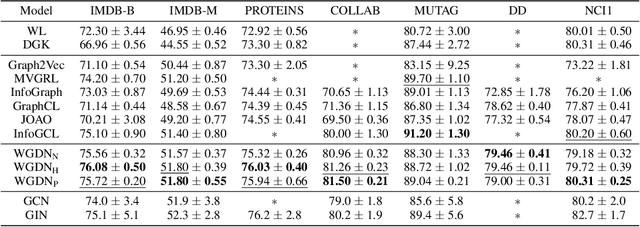
Graph self-supervised learning has been vastly employed to learn representations from unlabeled graphs. Existing methods can be roughly divided into predictive learning and contrastive learning, where the latter one attracts more research attention with better empirical performance. We argue that, however, predictive models weaponed with latent augmentations and powerful decoder could achieve comparable or even better representation power than contrastive models. In this work, we introduce data augmentations into latent space for superior generalization and better efficiency. A novel graph decoder named Wiener Graph Deconvolutional Network is correspondingly designed to perform information reconstruction from augmented latent representations. Theoretical analysis proves the superior reconstruction ability of graph wiener filter. Extensive experimental results on various datasets demonstrate the effectiveness of our approach.
Joint Prediction and Time Estimation of COVID-19 Developing Severe Symptoms using Chest CT Scan
May 07, 2020
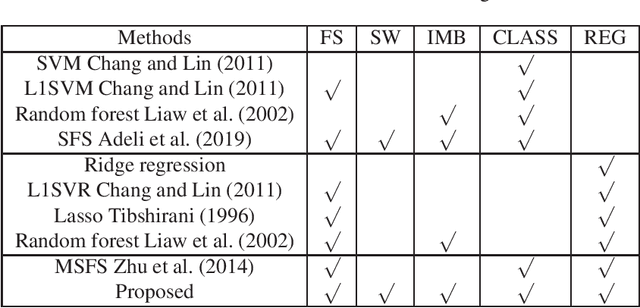
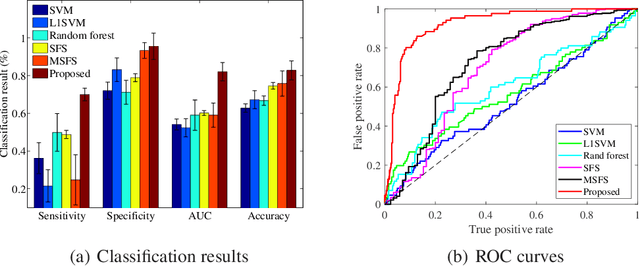
With the rapidly worldwide spread of Coronavirus disease (COVID-19), it is of great importance to conduct early diagnosis of COVID-19 and predict the time that patients might convert to the severe stage, for designing effective treatment plan and reducing the clinicians' workloads. In this study, we propose a joint classification and regression method to determine whether the patient would develop severe symptoms in the later time, and if yes, predict the possible conversion time that the patient would spend to convert to the severe stage. To do this, the proposed method takes into account 1) the weight for each sample to reduce the outliers' influence and explore the problem of imbalance classification, and 2) the weight for each feature via a sparsity regularization term to remove the redundant features of high-dimensional data and learn the shared information across the classification task and the regression task. To our knowledge, this study is the first work to predict the disease progression and the conversion time, which could help clinicians to deal with the potential severe cases in time or even save the patients' lives. Experimental analysis was conducted on a real data set from two hospitals with 422 chest computed tomography (CT) scans, where 52 cases were converted to severe on average 5.64 days and 34 cases were severe at admission. Results show that our method achieves the best classification (e.g., 85.91% of accuracy) and regression (e.g., 0.462 of the correlation coefficient) performance, compared to all comparison methods. Moreover, our proposed method yields 76.97% of accuracy for predicting the severe cases, 0.524 of the correlation coefficient, and 0.55 days difference for the converted time.
Convolution Forgetting Curve Model for Repeated Learning
Jan 19, 2019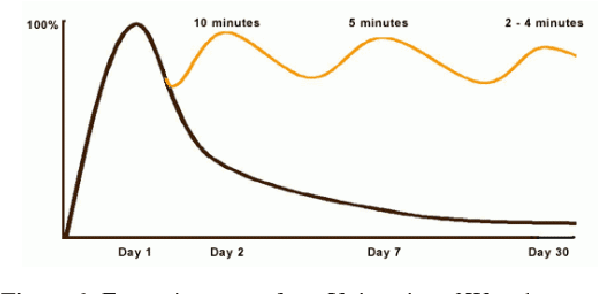
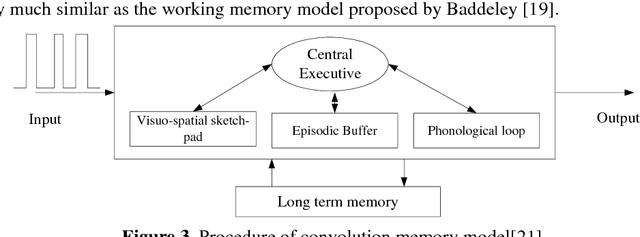
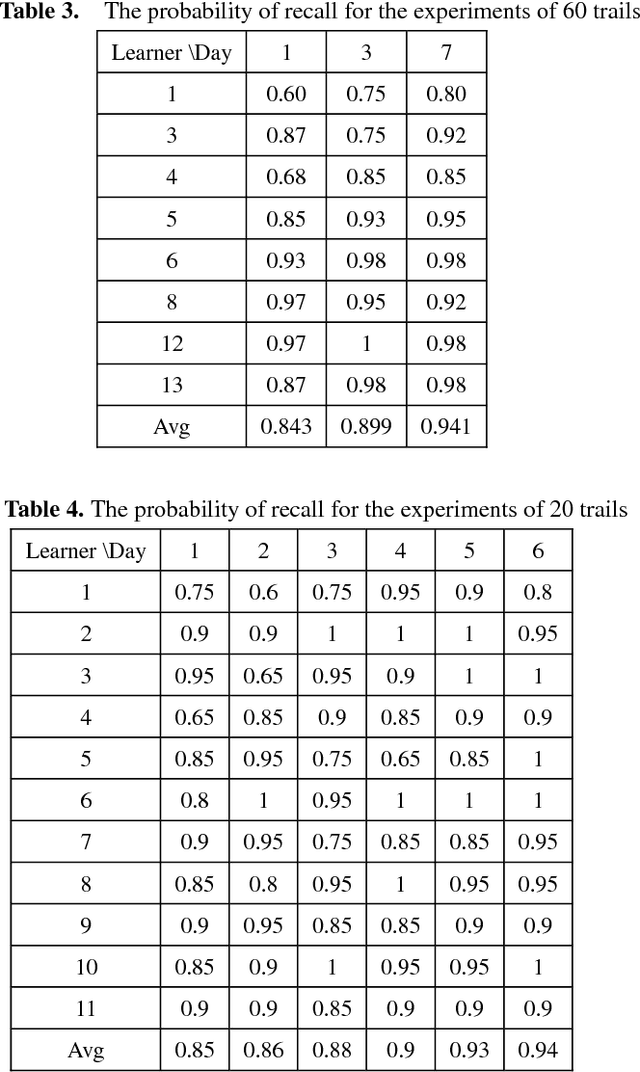
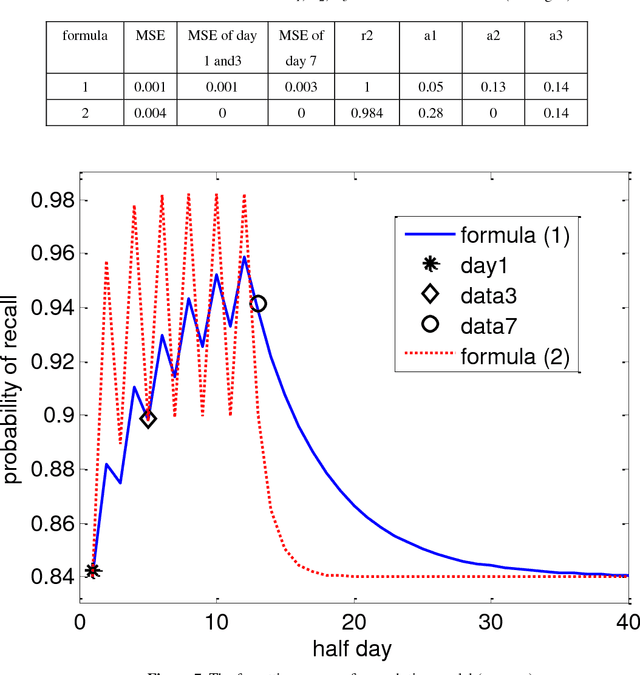
Most of mathematic forgetting curve models fit well with the forgetting data under the learning condition of one time rather than repeated. In the paper, a convolution model of forgetting curve is proposed to simulate the memory process during learning. In this model, the memory ability (i.e. the central procedure in the working memory model) and learning material (i.e. the input in the working memory model) is regarded as the system function and the input function, respectively. The status of forgetting (i.e. the output in the working memory model) is regarded as output function or the convolution result of the memory ability and learning material. The model is applied to simulate the forgetting curves in different situations. The results show that the model is able to simulate the forgetting curves not only in one time learning condition but also in multi-times condition. The model is further verified in the experiments of Mandarin tone learning for Japanese learners. And the predicted curve fits well on the test points.