 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposal Refinement for Few-Shot Object Detection
Jun 08, 2026Few-shot object detection has gained widely attention in recent years. Some excellent algorithms have been proposed to handle this task. However, most of these algorithms rely on the performance of few-shot classification. Unlike previous attempts, our work focuses on the problem of unbalanced distribution of region proposals between the novel classes and the base classes. In order to alleviate this unbalanced distribution, we propose the proposal refinement approach for different training phases. Specifically, refinement loss is designed for the base training phase to enhance sensitivity of the model to novel classes, and refinement branch is introduced as an auxiliary branch for RPN (Region Proposal Networks) to generate more novel proposals in the fine-tuning phase. By rebalancing the proposal distribution, the proposed approach outperforms the baselines methods by roughly 1\%$\sim$6\% on current benchmarks without increasing any inference time. Through extensive experiments, we prove that we establish a new state-of-the-art method for the few-shot object detection task.
Robust Multi-Stream Massive MIMO Satellite Systems Based on Statistical CSI
Apr 10, 2026This paper investigates multi-stream downlink precoding for massive multiple-input multiple-output low-Earthorbit satellite (SAT) communication systems. We adopt a delay and Doppler precompensation approach to achieve coherent transmission. Under this setting, we formulate a signal transmission model that incorporates the near-independent properties of inter-SAT interference and compensation errors. We then demonstrate that moving beyond single-stream transmission requires both multi-SAT cooperation and multi-antenna UTs. Based on this configuration and the established signal transmission model, we derive the first- and second-order statistical channel characteristics and utilize them to design locally optimal precoding algorithms for both total power constraint (TPC) and per-antenna power constraint (PAPC) conditions, which rely only on statistical channel state information (sCSI). In particular, the designed PAPC algorithm achieves linear complexity with respect to the number of antennas on the cooperative SATs. To reduce the computational complexity of the locally optimal precoder under TPC, we propose a low-complexity and robust precoding scheme optimized for both minimum mean squared error and sum-rate maximization objectives. Using majorization theory, we also provide a rigorous theoretical analysis of the optimal precoding structure under TPC. Moreover, the Lanczos algorithm is adopted to further reduce the complexity of the proposed robust designs. Simulation results show that when each SAT is equipped with a sufficiently large number of antennas, the proposed sCSI-based designs achieve performance comparable to that of instantaneous CSI-based designs.
LiftProj: Space Lifting and Projection-Based Panorama Stitching
Dec 30, 2025Traditional image stitching techniques have predominantly utilized two-dimensional homography transformations and mesh warping to achieve alignment on a planar surface. While effective for scenes that are approximately coplanar or exhibit minimal parallax, these approaches often result in ghosting, structural bending, and stretching distortions in non-overlapping regions when applied to real three-dimensional scenes characterized by multiple depth layers and occlusions. Such challenges are exacerbated in multi-view accumulations and 360° closed-loop stitching scenarios. In response, this study introduces a spatially lifted panoramic stitching framework that initially elevates each input image into a dense three-dimensional point representation within a unified coordinate system, facilitating global cross-view fusion augmented by confidence metrics. Subsequently, a unified projection center is established in three-dimensional space, and an equidistant cylindrical projection is employed to map the fused data onto a single panoramic manifold, thereby producing a geometrically consistent 360° panoramic layout. Finally, hole filling is conducted within the canvas domain to address unknown regions revealed by viewpoint transitions, restoring continuous texture and semantic coherence. This framework reconceptualizes stitching from a two-dimensional warping paradigm to a three-dimensional consistency paradigm and is designed to flexibly incorporate various three-dimensional lifting and completion modules. Experimental evaluations demonstrate that the proposed method substantially mitigates geometric distortions and ghosting artifacts in scenarios involving significant parallax and complex occlusions, yielding panoramic results that are more natural and consistent.
IGDMRec: Behavior Conditioned Item Graph Diffusion for Multimodal Recommendation
Dec 23, 2025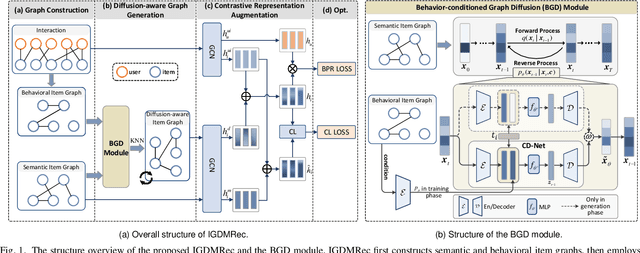
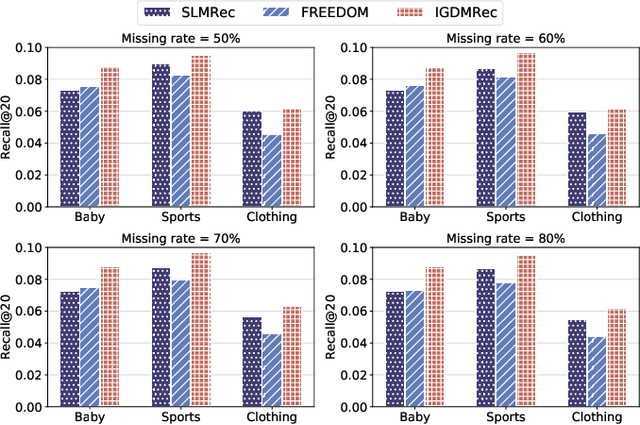
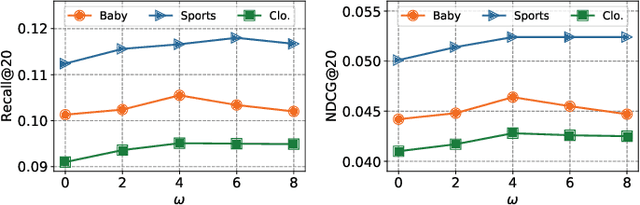
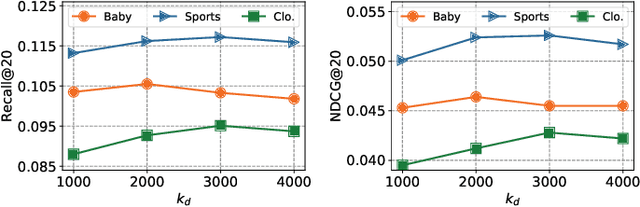
Multimodal recommender systems (MRSs) are critical for various online platforms, offering users more accurate personalized recommendations by incorporating multimodal information of items. Structure-based MRSs have achieved state-of-the-art performance by constructing semantic item graphs, which explicitly model relationships between items based on modality feature similarity. However, such semantic item graphs are often noisy due to 1) inherent noise in multimodal information and 2) misalignment between item semantics and user-item co-occurrence relationships, which introduces false links and leads to suboptimal recommendations. To address this challenge, we propose Item Graph Diffusion for Multimodal Recommendation (IGDMRec), a novel method that leverages a diffusion model with classifier-free guidance to denoise the semantic item graph by integrating user behavioral information. Specifically, IGDMRec introduces a Behavior-conditioned Graph Diffusion (BGD) module, incorporating interaction data as conditioning information to guide the denoising of the semantic item graph. Additionally, a Conditional Denoising Network (CD-Net) is designed to implement the denoising process with manageable complexity. Finally, we propose a contrastive representation augmentation scheme that leverages both the denoised item graph and the original item graph to enhance item representations. \LL{Extensive experiments on four real-world datasets demonstrate the superiority of IGDMRec over competitive baselines, with robustness analysis validating its denoising capability and ablation studies verifying the effectiveness of its key components.
Large Language Models and Artificial Intelligence Generated Content Technologies Meet Communication Networks
Nov 12, 2024



Artificial intelligence generated content (AIGC) technologies, with a predominance of large language models (LLMs), have demonstrated remarkable performance improvements in various applications, which have attracted great interests from both academia and industry. Although some noteworthy advancements have been made in this area, a comprehensive exploration of the intricate relationship between AIGC and communication networks remains relatively limited. To address this issue, this paper conducts an exhaustive survey from dual standpoints: firstly, it scrutinizes the integration of LLMs and AIGC technologies within the domain of communication networks; secondly, it investigates how the communication networks can further bolster the capabilities of LLMs and AIGC. Additionally, this research explores the promising applications along with the challenges encountered during the incorporation of these AI technologies into communication networks. Through these detailed analyses, our work aims to deepen the understanding of how LLMs and AIGC can synergize with and enhance the development of advanced intelligent communication networks, contributing to a more profound comprehension of next-generation intelligent communication networks.
Distributed Task-Oriented Communication Networks with Multimodal Semantic Relay and Edge Intelligence
Jan 19, 2024



In this article, we present a novel framework, named distributed task-oriented communication networks (DTCN), based on recent advances in multimodal semantic transmission and edge intelligence. In DTCN, the multimodal knowledge of semantic relays and the adaptive adjustment capability of edge intelligence can be integrated to improve task performance. Specifically, we propose the key techniques in the framework, such as semantic alignment and complement, a semantic relay scheme for deep joint source-channel relay coding, and collaborative device-server optimization and inference. Furthermore, a multimodal classification task is used as an example to demonstrate the benefits of the proposed DTCN over existing methods. Numerical results validate that DTCN can significantly improve the accuracy of classification tasks, even in harsh communication scenarios (e.g., low signal-to-noise regime), thanks to multimodal semantic relay and edge intelligence.
Attention-guided Multi-step Fusion: A Hierarchical Fusion Network for Multimodal Recommendation
Apr 24, 2023The main idea of multimodal recommendation is the rational utilization of the item's multimodal information to improve the recommendation performance. Previous works directly integrate item multimodal features with item ID embeddings, ignoring the inherent semantic relations contained in the multimodal features. In this paper, we propose a novel and effective aTtention-guided Multi-step FUsion Network for multimodal recommendation, named TMFUN. Specifically, our model first constructs modality feature graph and item feature graph to model the latent item-item semantic structures. Then, we use the attention module to identify inherent connections between user-item interaction data and multimodal data, evaluate the impact of multimodal data on different interactions, and achieve early-step fusion of item features. Furthermore, our model optimizes item representation through the attention-guided multi-step fusion strategy and contrastive learning to improve recommendation performance. The extensive experiments on three real-world datasets show that our model has superior performance compared to the state-of-the-art models.
HGAN: Hierarchical Graph Alignment Network for Image-Text Retrieval
Dec 16, 2022Image-text retrieval (ITR) is a challenging task in the field of multimodal information processing due to the semantic gap between different modalities. In recent years, researchers have made great progress in exploring the accurate alignment between image and text. However, existing works mainly focus on the fine-grained alignment between image regions and sentence fragments, which ignores the guiding significance of context background information. Actually, integrating the local fine-grained information and global context background information can provide more semantic clues for retrieval. In this paper, we propose a novel Hierarchical Graph Alignment Network (HGAN) for image-text retrieval. First, to capture the comprehensive multimodal features, we construct the feature graphs for the image and text modality respectively. Then, a multi-granularity shared space is established with a designed Multi-granularity Feature Aggregation and Rearrangement (MFAR) module, which enhances the semantic corresponding relations between the local and global information, and obtains more accurate feature representations for the image and text modalities. Finally, the ultimate image and text features are further refined through three-level similarity functions to achieve the hierarchical alignment. To justify the proposed model, we perform extensive experiments on MS-COCO and Flickr30K datasets. Experimental results show that the proposed HGAN outperforms the state-of-the-art methods on both datasets, which demonstrates the effectiveness and superiority of our model.
Task-Oriented Image Transmission for Scene Classification in Unmanned Aerial Systems
Dec 21, 2021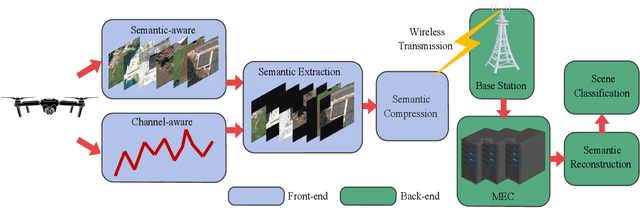
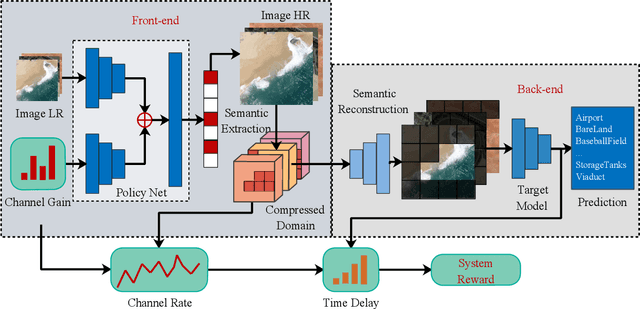
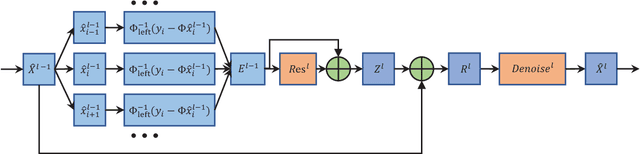
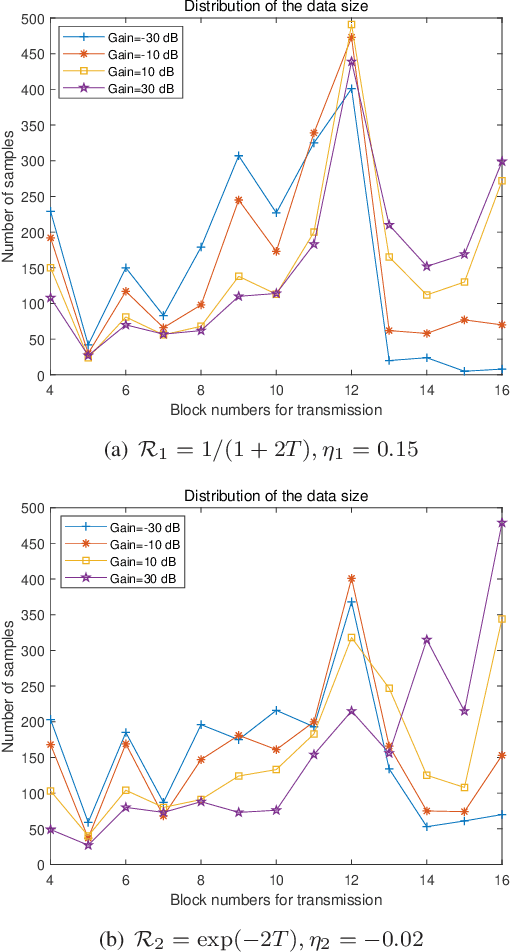
The vigorous developments of Internet of Things make it possible to extend its computing and storage capabilities to computing tasks in the aerial system with collaboration of cloud and edge, especially for artificial intelligence (AI) tasks based on deep learning (DL). Collecting a large amount of image/video data, Unmanned aerial vehicles (UAVs) can only handover intelligent analysis tasks to the back-end mobile edge computing (MEC) server due to their limited storage and computing capabilities. How to efficiently transmit the most correlated information for the AI model is a challenging topic. Inspired by the task-oriented communication in recent years, we propose a new aerial image transmission paradigm for the scene classification task. A lightweight model is developed on the front-end UAV for semantic blocks transmission with perception of images and channel conditions. In order to achieve the tradeoff between transmission latency and classification accuracy, deep reinforcement learning (DRL) is used to explore the semantic blocks which have the best contribution to the back-end classifier under various channel conditions. Experimental results show that the proposed method can significantly improve classification accuracy compared to the fixed transmission strategy and traditional content perception methods.
Dual-Sampling Attention Network for Diagnosis of COVID-19 from Community Acquired Pneumonia
May 20, 2020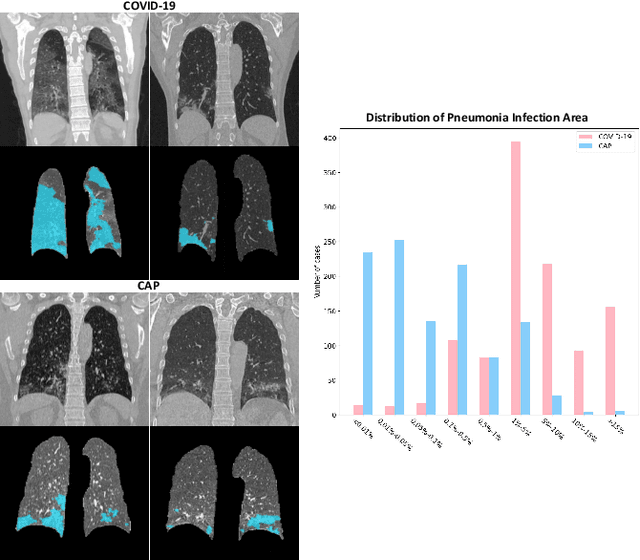
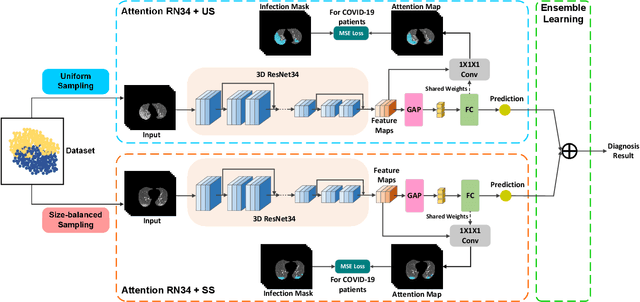
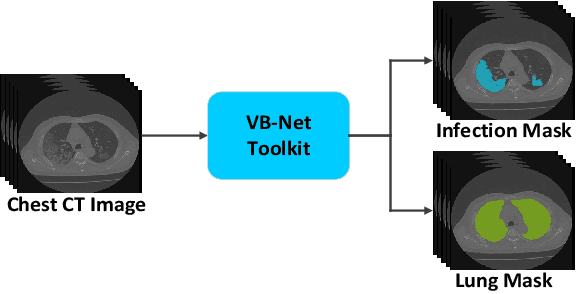
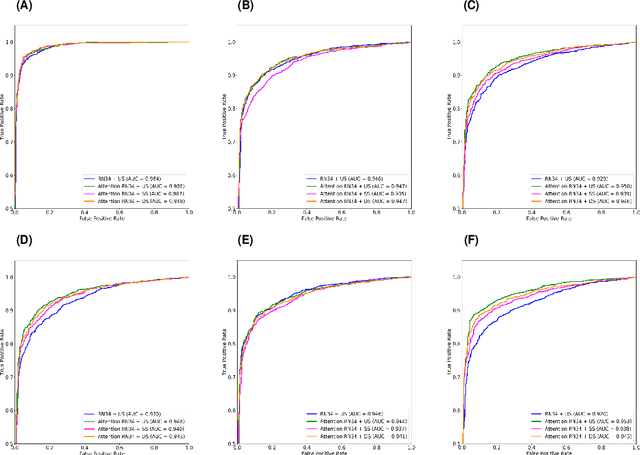
The coronavirus disease (COVID-19) is rapidly spreading all over the world, and has infected more than 1,436,000 people in more than 200 countries and territories as of April 9, 2020. Detecting COVID-19 at early stage is essential to deliver proper healthcare to the patients and also to protect the uninfected population. To this end, we develop a dual-sampling attention network to automatically diagnose COVID- 19 from the community acquired pneumonia (CAP) in chest computed tomography (CT). In particular, we propose a novel online attention module with a 3D convolutional network (CNN) to focus on the infection regions in lungs when making decisions of diagnoses. Note that there exists imbalanced distribution of the sizes of the infection regions between COVID-19 and CAP, partially due to fast progress of COVID-19 after symptom onset. Therefore, we develop a dual-sampling strategy to mitigate the imbalanced learning. Our method is evaluated (to our best knowledge) upon the largest multi-center CT data for COVID-19 from 8 hospitals. In the training-validation stage, we collect 2186 CT scans from 1588 patients for a 5-fold cross-validation. In the testing stage, we employ another independent large-scale testing dataset including 2796 CT scans from 2057 patients. Results show that our algorithm can identify the COVID-19 images with the area under the receiver operating characteristic curve (AUC) value of 0.944, accuracy of 87.5%, sensitivity of 86.9%, specificity of 90.1%, and F1-score of 82.0%. With this performance, the proposed algorithm could potentially aid radiologists with COVID-19 diagnosis from CAP, especially in the early stage of the COVID-19 outbreak.