 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE: A Molecular-Guided Foundation Model with Adaptive Region Modeling for Whole Slide Image Analysis
Feb 25, 2026Foundation models have recently achieved impressive success in computational pathology, demonstrating strong generalization across diverse histopathology tasks. However, existing models overlook the heterogeneous and non-uniform organization of pathological regions of interest (ROIs) because they rely on natural image backbones not tailored for tissue morphology. Consequently, they often fail to capture the coherent tissue architecture beyond isolated patches, limiting interpretability and clinical relevance. To address these challenges, we present Cross-modal Adaptive Region Encoder (CARE), a foundation model for pathology that automatically partitions WSIs into several morphologically relevant regions. Specifically, CARE employs a two-stage pretraining strategy: (1) a self-supervised unimodal pretraining stage that learns morphological representations from 34,277 whole-slide images (WSIs) without segmentation annotations, and (2) a cross-modal alignment stage that leverages RNA and protein profiles to refine the construction and representation of adaptive regions. This molecular guidance enables CARE to identify biologically relevant patterns and generate irregular yet coherent tissue regions, selecting the most representative area as ROI. CARE supports a broad range of pathology-related tasks, using either the ROI feature or the slide-level feature obtained by aggregating adaptive regions. Based on only one-tenth of the pretraining data typically used by mainstream foundation models, CARE achieves superior average performance across 33 downstream benchmarks, including morphological classification, molecular prediction, and survival analysis, and outperforms other foundation model baselines overall.
AI-driven Mobile Apps: an Explorative Study
Dec 03, 2022Recent years have witnessed an astonishing explosion in the evolution of mobile applications powered by AI technologies. The rapid growth of AI frameworks enables the transition of AI technologies to mobile devices, significantly prompting the adoption of AI apps (i.e., apps that integrate AI into their functions) among smartphone devices. In this paper, we conduct the most extensive empirical study on 56,682 published AI apps from three perspectives: dataset characteristics, development issues, and user feedback and privacy. To this end, we build an automated AI app identification tool, AI Discriminator, that detects eligible AI apps from 7,259,232 mobile apps. First, we carry out a dataset analysis, where we explore the AndroZoo large repository to identify AI apps and their core characteristics. Subsequently, we pinpoint key issues in AI app development (e.g., model protection). Finally, we focus on user reviews and user privacy protection. Our paper provides several notable findings. Some essential ones involve revealing the issue of insufficient model protection by presenting the lack of model encryption, and demonstrating the risk of user privacy data being leaked. We published our large-scale AI app datasets to inspire more future research.
Checking Patch Behaviour against Test Specification
Jul 28, 2021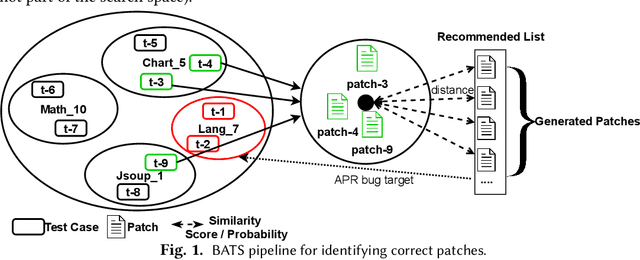
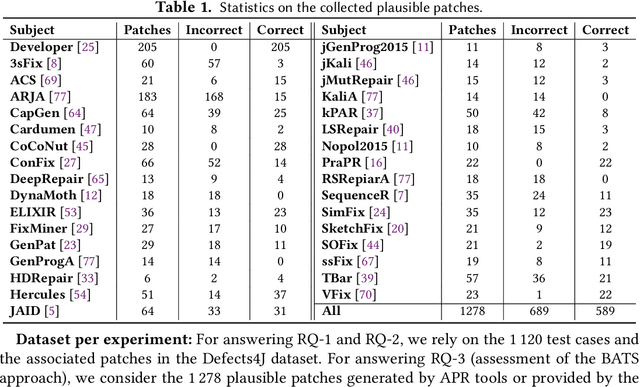
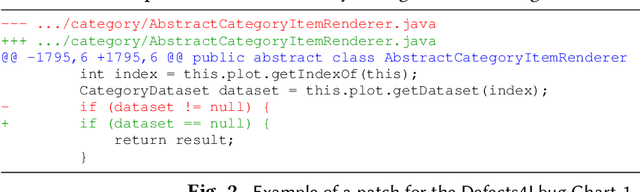

Towards predicting patch correctness in APR, we propose a simple, but novel hypothesis on how the link between the patch behaviour and failing test specifications can be drawn: similar failing test cases should require similar patches. We then propose BATS, an unsupervised learning-based system to predict patch correctness by checking patch Behaviour Against failing Test Specification. BATS exploits deep representation learning models for code and patches: for a given failing test case, the yielded embedding is used to compute similarity metrics in the search for historical similar test cases in order to identify the associated applied patches, which are then used as a proxy for assessing generated patch correctness. Experimentally, we first validate our hypothesis by assessing whether ground-truth developer patches cluster together in the same way that their associated failing test cases are clustered. Then, after collecting a large dataset of 1278 plausible patches (written by developers or generated by some 32 APR tools), we use BATS to predict correctness: BATS achieves an AUC between 0.557 to 0.718 and a recall between 0.562 and 0.854 in identifying correct patches. Compared against previous work, we demonstrate that our approach outperforms state-of-the-art performance in patch correctness prediction, without the need for large labeled patch datasets in contrast with prior machine learning-based approaches. While BATS is constrained by the availability of similar test cases, we show that it can still be complementary to existing approaches: used in conjunction with a recent approach implementing supervised learning, BATS improves the overall recall in detecting correct patches. We finally show that BATS can be complementary to the state-of-the-art PATCH-SIM dynamic approach of identifying the correct patches for APR tools.
Super-Resolution of Brain MRI Images using Overcomplete Dictionaries and Nonlocal Similarity
Feb 13, 2019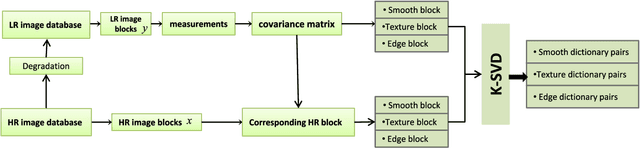
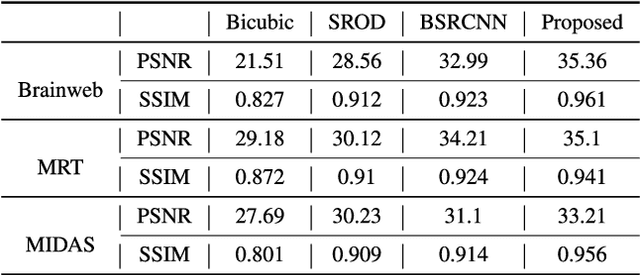


Recently, the Magnetic Resonance Imaging (MRI) images have limited and unsatisfactory resolutions due to various constraints such as physical, technological and economic considerations. Super-resolution techniques can obtain high-resolution MRI images. The traditional methods obtained the resolution enhancement of brain MRI by interpolations, affecting the accuracy of the following diagnose process. The requirement for brain image quality is fast increasing. In this paper, we propose an image super-resolution (SR) method based on overcomplete dictionaries and inherent similarity of an image to recover the high-resolution (HR) image from a single low-resolution (LR) image. We explore the nonlocal similarity of the image to tentatively search for similar blocks in the whole image and present a joint reconstruction method based on compressive sensing (CS) and similarity constraints. The sparsity and self-similarity of the image blocks are taken as the constraints. The proposed method is summarized in the following steps. First, a dictionary classification method based on the measurement domain is presented. The image blocks are classified into smooth, texture and edge parts by analyzing their features in the measurement domain. Then, the corresponding dictionaries are trained using the classified image blocks. Equally important, in the reconstruction part, we use the CS reconstruction method to recover the HR brain MRI image, considering both nonlocal similarity and the sparsity of an image as the constraints. This method performs better both visually and quantitatively than some existing methods.