 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSonic: Towards Universal and Holistic Audio Generation from Video and Text
Apr 06, 2026In this paper, we propose Universal Holistic Audio Generation (UniHAGen), a task for synthesizing comprehensive auditory scenes that include both on-screen and off-screen sounds across diverse domains (e.g., ambient events, musical instruments, and human speech). Prior video-conditioned audio generation models typically focus on producing on-screen environmental sounds that correspond to visible sounding events, neglecting off-screen auditory events. While recent holistic joint text-video-to-audio generation models aim to produce auditory scenes with both on- and off-screen sound but they are limited to non-speech sounds, lacking the ability to generate or integrate human speech. To overcome these limitations, we introduce OmniSonic, a flow-matching-based diffusion framework jointly conditioned on video and text. It features a TriAttn-DiT architecture that performs three cross-attention operations to process on-screen environmental sound, off-screen environmental sound, and speech conditions simultaneously, with a Mixture-of-Experts (MoE) gating mechanism that adaptively balances their contributions during generation. Furthermore, we construct UniHAGen-Bench, a new benchmark with over one thousand samples covering three representative on/off-screen speech-environment scenarios. Extensive experiments show that OmniSonic consistently outperforms state-of-the-art approaches on both objective metrics and human evaluations, establishing a strong baseline for universal and holistic audio generation. Project page: https://weiguopian.github.io/OmniSonic_webpage/
Towards Online Multi-Modal Social Interaction Understanding
Mar 25, 2025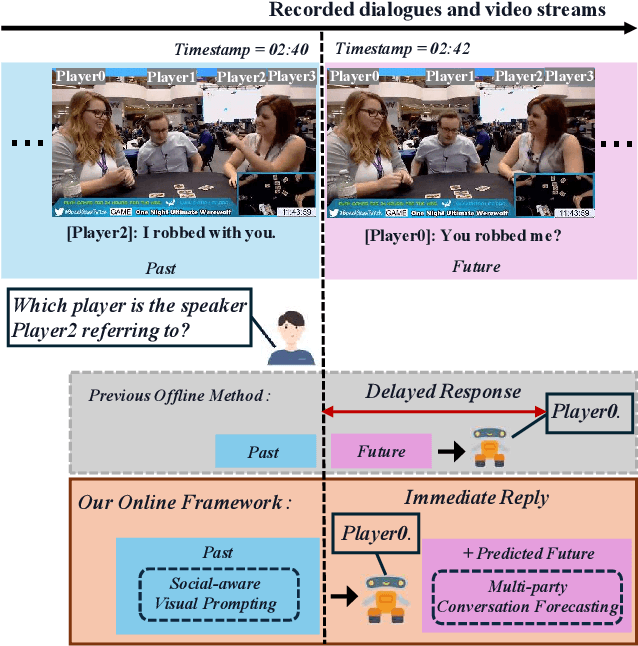
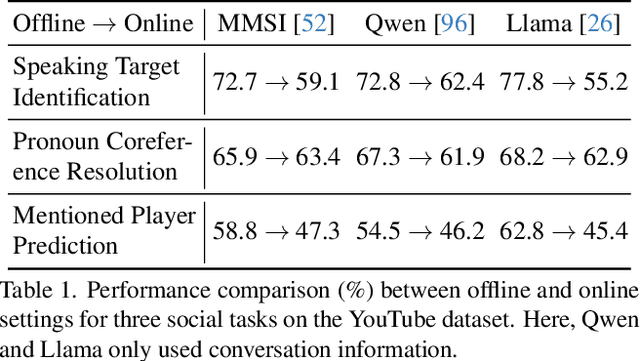
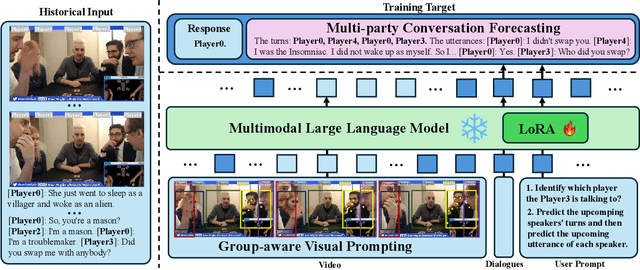
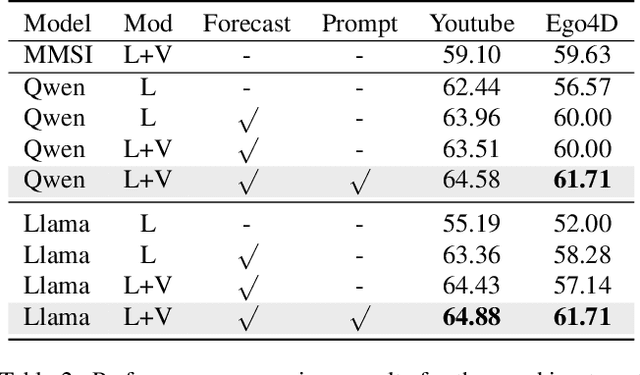
Multimodal social interaction understanding (MMSI) is critical in human-robot interaction systems. In real-world scenarios, AI agents are required to provide real-time feedback. However, existing models often depend on both past and future contexts, which hinders them from applying to real-world problems. To bridge this gap, we propose an online MMSI setting, where the model must resolve MMSI tasks using only historical information, such as recorded dialogues and video streams. To address the challenges of missing the useful future context, we develop a novel framework, named Online-MMSI-VLM, that leverages two complementary strategies: multi-party conversation forecasting and social-aware visual prompting with multi-modal large language models. First, to enrich linguistic context, the multi-party conversation forecasting simulates potential future utterances in a coarse-to-fine manner, anticipating upcoming speaker turns and then generating fine-grained conversational details. Second, to effectively incorporate visual social cues like gaze and gesture, social-aware visual prompting highlights the social dynamics in video with bounding boxes and body keypoints for each person and frame. Extensive experiments on three tasks and two datasets demonstrate that our method achieves state-of-the-art performance and significantly outperforms baseline models, indicating its effectiveness on Online-MMSI. The code and pre-trained models will be publicly released at: https://github.com/Sampson-Lee/OnlineMMSI.
Modality-Inconsistent Continual Learning of Multimodal Large Language Models
Dec 17, 2024


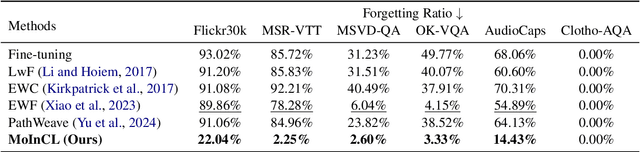
In this paper, we introduce Modality-Inconsistent Continual Learning (MICL), a new continual learning scenario for Multimodal Large Language Models (MLLMs) that involves tasks with inconsistent modalities (image, audio, or video) and varying task types (captioning or question-answering). Unlike existing vision-only or modality-incremental settings, MICL combines modality and task type shifts, both of which drive catastrophic forgetting. To address these challenges, we propose MoInCL, which employs a Pseudo Targets Generation Module to mitigate forgetting caused by task type shifts in previously seen modalities. It also incorporates Instruction-based Knowledge Distillation to preserve the model's ability to handle previously learned modalities when new ones are introduced. We benchmark MICL using a total of six tasks and conduct experiments to validate the effectiveness of our proposed MoInCL. The experimental results highlight the superiority of MoInCL, showing significant improvements over representative and state-of-the-art continual learning baselines.
Continual Audio-Visual Sound Separation
Nov 05, 2024



In this paper, we introduce a novel continual audio-visual sound separation task, aiming to continuously separate sound sources for new classes while preserving performance on previously learned classes, with the aid of visual guidance. This problem is crucial for practical visually guided auditory perception as it can significantly enhance the adaptability and robustness of audio-visual sound separation models, making them more applicable for real-world scenarios where encountering new sound sources is commonplace. The task is inherently challenging as our models must not only effectively utilize information from both modalities in current tasks but also preserve their cross-modal association in old tasks to mitigate catastrophic forgetting during audio-visual continual learning. To address these challenges, we propose a novel approach named ContAV-Sep (\textbf{Cont}inual \textbf{A}udio-\textbf{V}isual Sound \textbf{Sep}aration). ContAV-Sep presents a novel Cross-modal Similarity Distillation Constraint (CrossSDC) to uphold the cross-modal semantic similarity through incremental tasks and retain previously acquired knowledge of semantic similarity in old models, mitigating the risk of catastrophic forgetting. The CrossSDC can seamlessly integrate into the training process of different audio-visual sound separation frameworks. Experiments demonstrate that ContAV-Sep can effectively mitigate catastrophic forgetting and achieve significantly better performance compared to other continual learning baselines for audio-visual sound separation. Code is available at: \url{https://github.com/weiguoPian/ContAV-Sep_NeurIPS2024}.
Class-Incremental Grouping Network for Continual Audio-Visual Learning
Sep 11, 2023Continual learning is a challenging problem in which models need to be trained on non-stationary data across sequential tasks for class-incremental learning. While previous methods have focused on using either regularization or rehearsal-based frameworks to alleviate catastrophic forgetting in image classification, they are limited to a single modality and cannot learn compact class-aware cross-modal representations for continual audio-visual learning. To address this gap, we propose a novel class-incremental grouping network (CIGN) that can learn category-wise semantic features to achieve continual audio-visual learning. Our CIGN leverages learnable audio-visual class tokens and audio-visual grouping to continually aggregate class-aware features. Additionally, it utilizes class tokens distillation and continual grouping to prevent forgetting parameters learned from previous tasks, thereby improving the model's ability to capture discriminative audio-visual categories. We conduct extensive experiments on VGGSound-Instruments, VGGSound-100, and VGG-Sound Sources benchmarks. Our experimental results demonstrate that the CIGN achieves state-of-the-art audio-visual class-incremental learning performance. Code is available at https://github.com/stoneMo/CIGN.
Audio-Visual Class-Incremental Learning
Aug 21, 2023In this paper, we introduce audio-visual class-incremental learning, a class-incremental learning scenario for audio-visual video recognition. We demonstrate that joint audio-visual modeling can improve class-incremental learning, but current methods fail to preserve semantic similarity between audio and visual features as incremental step grows. Furthermore, we observe that audio-visual correlations learned in previous tasks can be forgotten as incremental steps progress, leading to poor performance. To overcome these challenges, we propose AV-CIL, which incorporates Dual-Audio-Visual Similarity Constraint (D-AVSC) to maintain both instance-aware and class-aware semantic similarity between audio-visual modalities and Visual Attention Distillation (VAD) to retain previously learned audio-guided visual attentive ability. We create three audio-visual class-incremental datasets, AVE-Class-Incremental (AVE-CI), Kinetics-Sounds-Class-Incremental (K-S-CI), and VGGSound100-Class-Incremental (VS100-CI) based on the AVE, Kinetics-Sounds, and VGGSound datasets, respectively. Our experiments on AVE-CI, K-S-CI, and VS100-CI demonstrate that AV-CIL significantly outperforms existing class-incremental learning methods in audio-visual class-incremental learning. Code and data are available at: https://github.com/weiguoPian/AV-CIL_ICCV2023.
LaFiCMIL: Rethinking Large File Classification from the Perspective of Correlated Multiple Instance Learning
Aug 15, 2023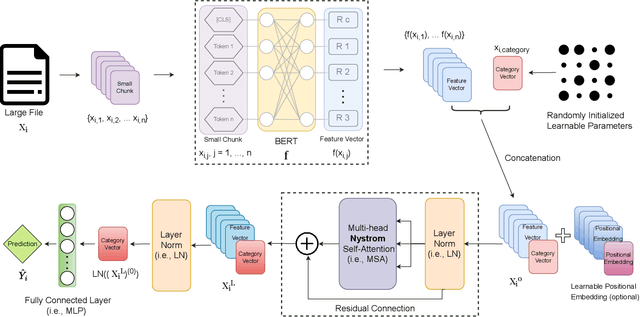
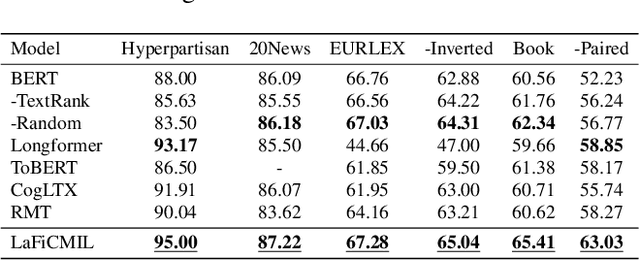
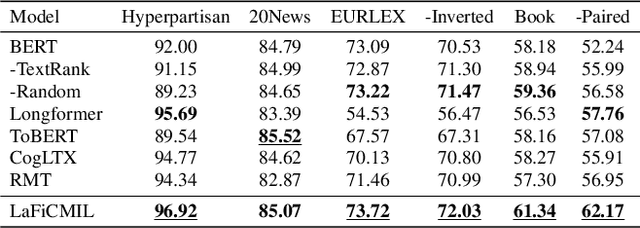
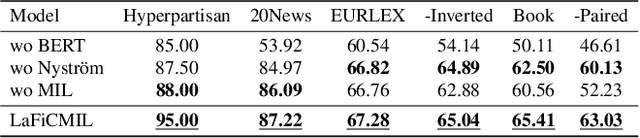
Transformer-based models, such as BERT, have revolutionized various language tasks, but still struggle with large file classification due to their input limit (e.g., 512 tokens). Despite several attempts to alleviate this limitation, no method consistently excels across all benchmark datasets, primarily because they can only extract partial essential information from the input file. Additionally, they fail to adapt to the varied properties of different types of large files. In this work, we tackle this problem from the perspective of correlated multiple instance learning. The proposed approach, LaFiCMIL, serves as a versatile framework applicable to various large file classification tasks covering binary, multi-class, and multi-label classification tasks, spanning various domains including Natural Language Processing, Programming Language Processing, and Android Analysis. To evaluate its effectiveness, we employ eight benchmark datasets pertaining to Long Document Classification, Code Defect Detection, and Android Malware Detection. Leveraging BERT-family models as feature extractors, our experimental results demonstrate that LaFiCMIL achieves new state-of-the-art performance across all benchmark datasets. This is largely attributable to its capability of scaling BERT up to nearly 20K tokens, running on a single Tesla V-100 GPU with 32G of memory.
MetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Jun 13, 2022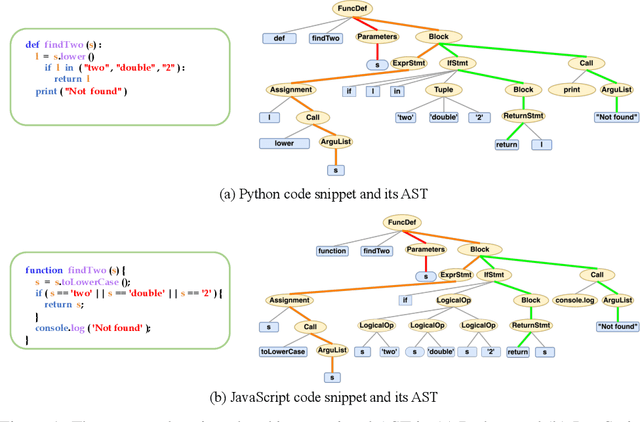
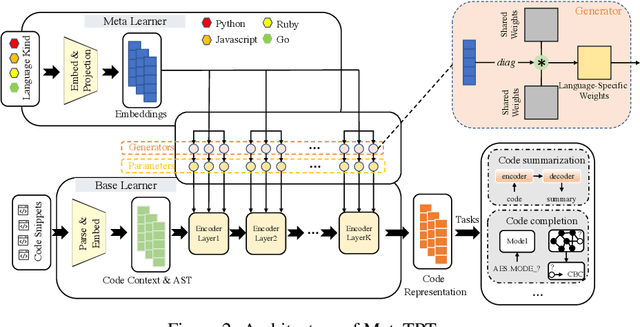
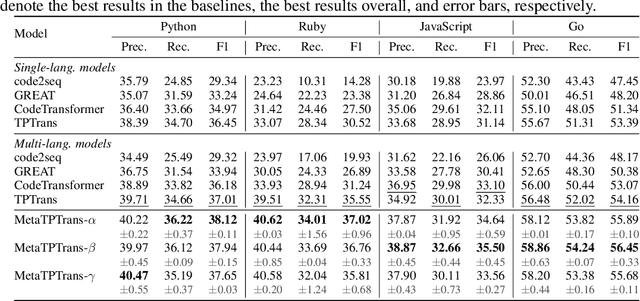
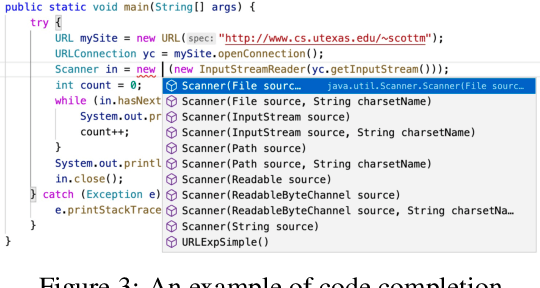
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.
Checking Patch Behaviour against Test Specification
Jul 28, 2021
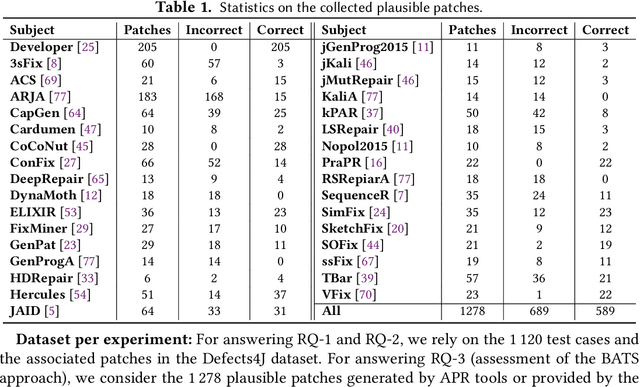
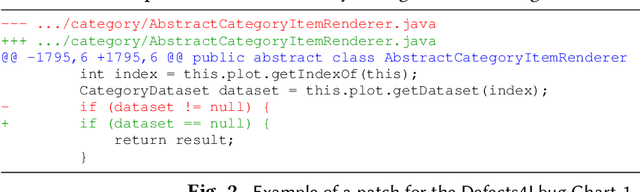

Towards predicting patch correctness in APR, we propose a simple, but novel hypothesis on how the link between the patch behaviour and failing test specifications can be drawn: similar failing test cases should require similar patches. We then propose BATS, an unsupervised learning-based system to predict patch correctness by checking patch Behaviour Against failing Test Specification. BATS exploits deep representation learning models for code and patches: for a given failing test case, the yielded embedding is used to compute similarity metrics in the search for historical similar test cases in order to identify the associated applied patches, which are then used as a proxy for assessing generated patch correctness. Experimentally, we first validate our hypothesis by assessing whether ground-truth developer patches cluster together in the same way that their associated failing test cases are clustered. Then, after collecting a large dataset of 1278 plausible patches (written by developers or generated by some 32 APR tools), we use BATS to predict correctness: BATS achieves an AUC between 0.557 to 0.718 and a recall between 0.562 and 0.854 in identifying correct patches. Compared against previous work, we demonstrate that our approach outperforms state-of-the-art performance in patch correctness prediction, without the need for large labeled patch datasets in contrast with prior machine learning-based approaches. While BATS is constrained by the availability of similar test cases, we show that it can still be complementary to existing approaches: used in conjunction with a recent approach implementing supervised learning, BATS improves the overall recall in detecting correct patches. We finally show that BATS can be complementary to the state-of-the-art PATCH-SIM dynamic approach of identifying the correct patches for APR tools.
Spatial-Temporal Dynamic Graph Attention Networks for Ride-hailing Demand Prediction
Jun 07, 2020
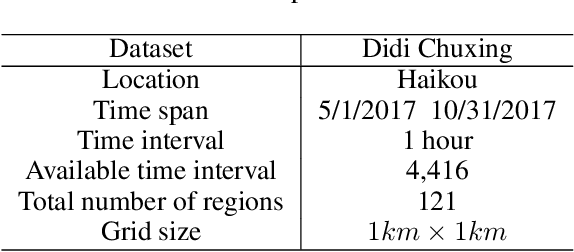
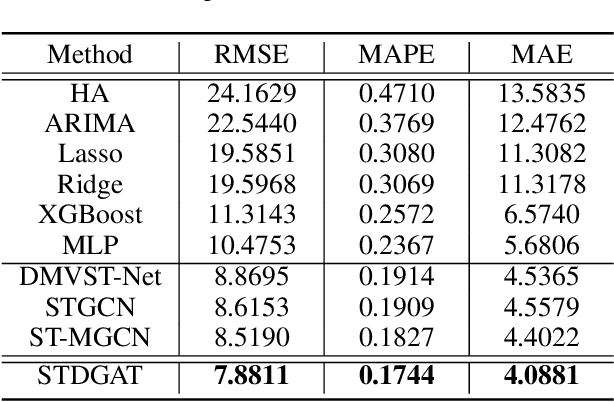
Ride-hailing demand prediction is an important prediction task in traffic prediction. An accurate prediction model can help the platform pre-allocate resources in advance to improve vehicle utilization and reduce the wait-time. This task is challenging due to the complicated spatial-temporal relationships among regions. Most existing methods mainly focus on Euclidean correlations among regions. Though there are some methods that use Graph Convolutional Networks (GCN) to capture the non-Euclidean pair-wise correlations, they only rely on the static topological structure among regions. Besides, they only consider fixed graph structures at different time intervals. In this paper, we propose a novel deep learning method called Spatial-Temporal Dynamic Graph Attention Network (STDGAT) to predict the taxi demand of multiple connected regions in the near future. The method uses Graph Attention Network (GAT), which achieves the adaptive allocation of weights for other regions, to capture the spatial information. Furthermore, we implement a Dynamic Graph Attention mode to capture the different spatial relationships at different time intervals based on the actual commuting relationships. Extensive experiments are conducted on a real-world large scale ride-hailing demand dataset, the results demonstrate the superiority of our method over existing methods.