 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Paper and Code
Jun 13, 2022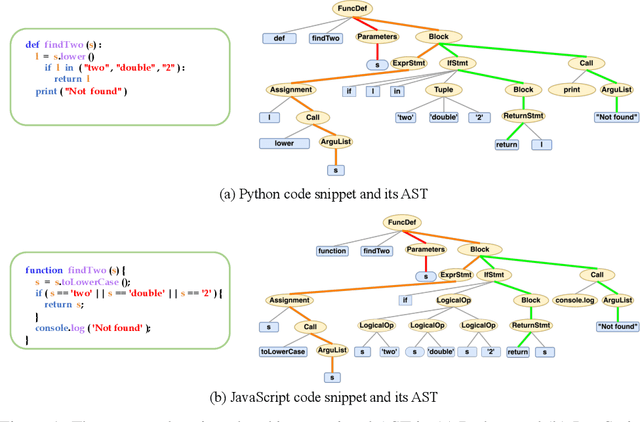
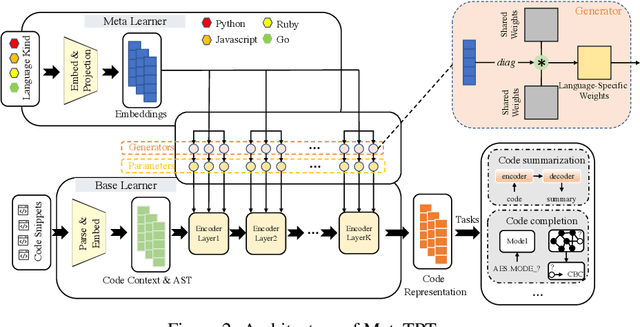
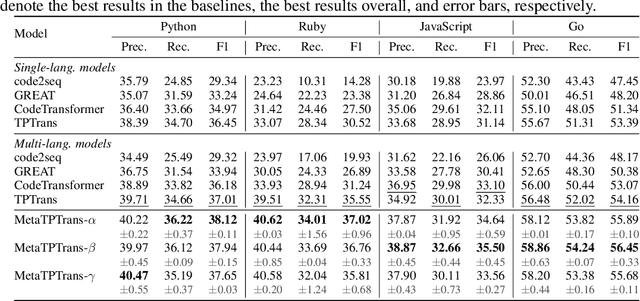
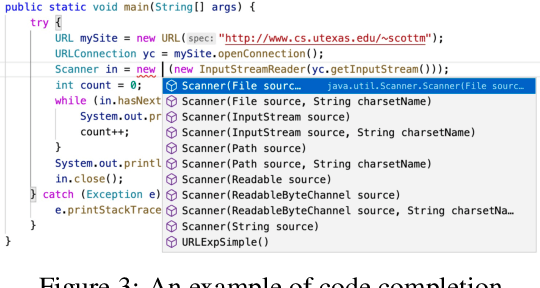
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.